
10.4 使用RANSAC拟合高鲁棒性回归模型
异常值对线性回归模型具有严重的影响。某些情况下,数据集的一个非常小的子集也可能会对模型参数的估计造成很大的影响。目前已有许多统计检测方法能够检测异常值,但该部分内容已超出本书范围。不过,作为数据方面的研究人员,我们需要根据相关领域的专业知识,并结合自身的判断清除异常值。
作为清除异常值的一种高鲁棒性回归方法,在此我们将学习随机抽样一致性(RANdom SAmple Consensus,RANSAC)算法,使用数据的一个子集(即所谓的内点,inlier)来进行回归模型的拟合。
我们将RANSAC算法的工作流程总结如下:
1)从数据集中随机抽取样本构建内点集合来拟合模型。
2)使用剩余数据对上一步得到的模型进行测试,并将落在预定公差范围内的样本点增至内点集合中。
3)使用全部的内点集合数据再次进行模型的拟合。
4)使用内点集合来估计模型的误差。
5)如果模型性能达到了用户设定的特定阈值或者迭代达到了预定次数,则算法终止,否则跳转到第1步。
现在使用scikit-learn的RANSACRegressor对象来实现我们的线性模型:

我们将RANSACRegression的最大迭代次数设定为100,设定参数min_samples=50,即随机抽取作为内点的最小样本数量设定为50。使用residual_metric参数,我们向其传递了一个lambda函数,此函数能够计算拟合曲线与样本点间垂直距离的绝对值。同时将residual_threshold参数的值设定为5.0,这样只有与拟合曲线垂直距离小于5个单位长度的样本点才能加入到内点集合,此设置在特定数据集上表现良好。scikit-learn默认使用MAD估计来设置内点阈值,其中MAD是目标值y的中位数绝对偏差(Median Absolute Deviation)的缩写。不过,内点阈值的确定是与具体问题相关的,这也是RANSAC的一个问题所在。近年来,已经出现了多种能够自动选出适宜的内点阈值的方法。读者可以通过R.Toldo和A.Fusiello的论文了解详细内容[1]。
完成RANSAC模型的拟合后,我们使用该RANSAC线性回归模型来获取内点和异常值的集合,并将它们与使用内点拟合得到的曲线一同绘制:

从下面的散点图中可以看到,线性回归模型是通过内点(圆)集合拟合得到的:
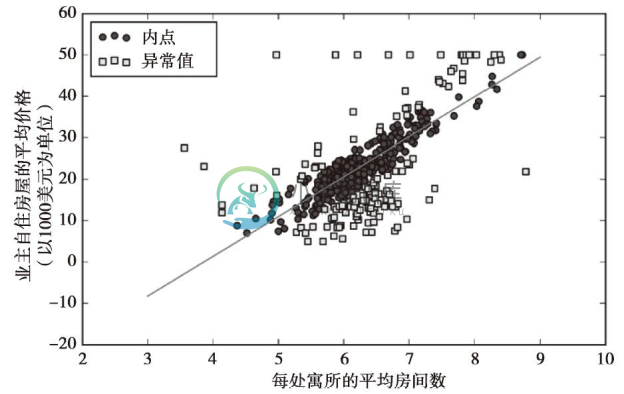
我们使用下面的代码来显示模型的斜率和截距,可以看到结果与前面未使用RANSAC得到的拟合曲线稍有不同:

使用RANSAC,我们降低了数据集中异常点的潜在影响,但无法确定该方法对未知数据的预测性能是否存在正面影响。因此,下一节中将讨论回归模型评估的不同方法,这是预测模型构建系统中的一个重要组成部分。
[1] Automatic Estimation of the Inlier Threshold in Robust Multiple Structures Fitting,in Image Analysis and Processing-ICIAP 2009,pages 123-131.Springer,2009.