
8.1 获取IMDb电影评论数据集
情感分析,有时也称为观点挖掘(opinion mining),是NLP领域一个非常流行的分支;它分析的是文档的情感倾向(polarity)。情感分析的一个常见任务就是根据作者对某一主题所表达的观点或是情感来对文档进行分类。
在本章中,我们将使用由Maas等人[1]收集的互联网电影数据库(Internet Movie Database,IMDb)中的大量电影评论数据。此数据集包含50000个关于电影的正面或负面的评论,正面的意思是影片在IMDb数据库中的评分高于6星,而负面的意思是影片的评分低于5星。在本章后续内容中,我们将学习如何从这些电影评论的子集中抽取有意义的信息,以此来构建模型并用于预测评论者对影片的喜好。
读者可通过链接http://ai.stanford.edu/~amaas/data/sentiment/下载电影评论数据集的gzip压缩文档(84.1MB):
·如果读者使用的是Linux或者macOS,可以打开一个终端窗口,使用cd命令定位到download目录,并执行tar-zxf aclImdb_v1.tar.gz命令解压数据集。
·若使用Windows,可以下载免费软件(如7-Zip[2])解压下载的压缩文件。
在成功提取数据集后,我们现在着手将从压缩文件中得到的各文本文档组合为一个CSV文件。在下面的代码中,我们把电影的评论读取到pandas的DataFrame对象中,使用普通的计算机该过程大约需要10分钟的时间。为了实现对处理过程的可视化,同时能够预测剩余处理时间,这里会用到PyPrind包(Python Progress Indicator,https://pypi.python.org/pypi/PyPrind/)。读者可以执行pip install pyprind命令安装PyPrind。
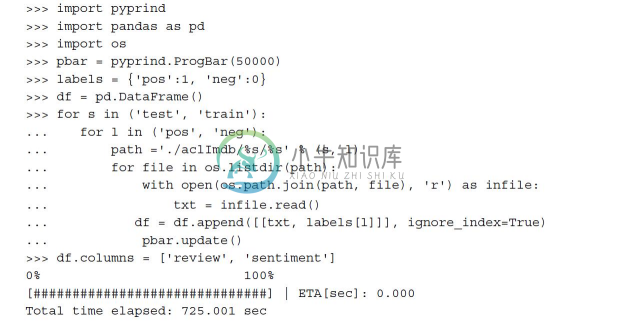
执行上述代码,我们首先初始化了一个包含50000次迭代的进度条对象pbar,这也是我们准备读取的文档的数量。使用嵌套的for循环,我们迭代地读取aclImdb目录下的train和test两个子目录,以及pos和neg二级子目录下的文本文件,并将其附加到DataFrame对象df中,同时加入的还有文档对应的整数型类标(1代表正面,0代表负面)。
由于集成处理过后数据集中的类标是经过排序的,我们现在将使用np.random子模块下的permutation函数对DataFrame对象进行重排——由于在后续小节中我们将直接从本地驱动器读取数据,因此重排对于后续将数据集划分为训练集和测试集的操作是非常有用的。出于使用方便的考虑,我们将经过集成处理及重排后的评论数据集均存储为CSV文件:

本章后续内容中会使用该数据集,现在读取并输出前三个样本的摘要,以此来快速确认数据已按正确格式存储:
![]()
如果在IPython Notebook上运行上述代码,那么将看到数据集中前三个样本的信息,如下表所示:

[1] A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y. Ng, and C. Potts. Learning Word Vectors for Sentiment Analysis. In the proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:Human Language Technologies, pages 142–150, Portland, Oregon, USA, June 2011. Association for Computational Linguistics.
[2] http://www.7-zip.org.