
7.2 实现一个简单的多数投票分类器
通过上一小节的介绍,我们已经对集成学习有了初步的认识,现在来做一个热身练习:基于多数投票原则,使用Python实现一个简单的集成分类器。虽然下述算法可通过简单多数投票推广到多分类器的情形,不过为了简单起见,我们仍旧使用更常出现在文献中的术语:多数投票(majority voting)。
集成算法允许我们使用单独的权重对不同分类算法进行组合。我们的目标是构建一个更加强大的元分类器,以在特定的数据集上平衡单个分类器的弱点。通过更严格的数学概念,可以将加权多数投票记为:
![]()
其中,wj是成员分类器Cj对应的权重,![]() 为集成分类器的预测类标,χA(希腊字母chi)为特征函数[Cj(x)=i∈A],A为类标的集合。如果权重均等,可以将此公式简化为:
为集成分类器的预测类标,χA(希腊字母chi)为特征函数[Cj(x)=i∈A],A为类标的集合。如果权重均等,可以将此公式简化为:
![]()
为了更好地理解权重在这里的含义,我们来看几个更加具体的例子。假定有三个成员分类器Cj(j∈{1,2,3}),分别用它们来预测样本x的类标。其中两个成员分类器的预测结果为类别0,而另外一个分类器C3的预测结果为类别1。如果我们平等地看待每个成员分类器,基于多数投票原则,最终的预测结果应该是样本属于类别0:

我们将权重0.6赋给C3,而C1和C2均为0.2,有:

更直观地,由于3×0.2=0.6,可以认为分类器C3的一次预测权重相当于分类器C1或C2的三次预测权重之和,我们可以写作:
![]()
为了使用Python代码实现加权多数投票,可以使用NumPy中的argmax和bincount函数:

我们在第3章中曾讨论过,通过predict_proba方法,scikit-learn中的分类器可以返回样本属于预测类标的概率。如果集成分类器事先得到良好的修正,那么在多数投票中使用预测类别的概率来替代类标会非常有用。使用类别概率进行预测的多数投票修改版本可记为:

其中,pij是第j个分类器预测样本类标为i的概率。
继续前面的例子,假设我们面临一个二类别分类问题,其类标为i∈{0,1},下面集成这三个分类器Cj(j∈{1,2,3})。假定分类器Cj针对某一样本x按照如下概率返回类标的预测结果:
![]()
我们可以按照如下方式计算所属类别的概率:
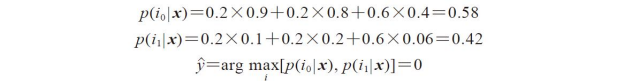
为实现基于类别预测概率的加权多数投票,我们可以再次使用NumPy中的numPy.average和np.argmax方法:

综合上述内容,我们使用Python来实现MajorityVoteClassifier类:


为了帮助读者更好地理解各部分内容,我在代码中加入了大量的注释。不过,在实现其他的方法之前,我们稍做中断,先快速地讨论一下看似让人眼花缭乱的代码。我们使用两个基类BaseEstimator和ClassifierMixin获取某些基本方法,包括设定分类器参数的set_params和返回参数的get_params方法,以及用于计算预测准确率的score方法。此外请注意,我们导入six包从而使得MajorityVoteClassifier与Python 2.7兼容。
接下来我们加入predict方法:如果使用参数vote='classlabel'初始化MajorityVote-Classifier对象,我们就可通过多数投票来预测类标,相反,如果使用参数vote='probability'初始化集成分类器,则可基于类别成员的概率进行类标预测。此外,我们还将加入predict_proba方法来返回平均概率,这在计算受试工作者特征线下区域(Receiver Operator Characteristic area under the curve,ROC AUC)时需要用到。



此外还请注意:这里还定义了我们自行修改的get_params方法,以方便使用_name_estimators函数来访问集成分类器中独立成员函数的参数。起初看起来这有点复杂,但在后续小节中,我们将使用网格搜索来调整超参,那时你会感到这样做意义非凡。
 主要是出于演示的目的,我们才实现了MajorityVoteClassifier类,不过这也完成了scikit-learn中关于多数投票分类器的一个相对复杂的版本。它将出现在下一个版本(v0.17)的sklearn.ensemble.VotingClassifier类中。
主要是出于演示的目的,我们才实现了MajorityVoteClassifier类,不过这也完成了scikit-learn中关于多数投票分类器的一个相对复杂的版本。它将出现在下一个版本(v0.17)的sklearn.ensemble.VotingClassifier类中。
基于多数投票原则组合不同的分类算法
现在我们可以将上一小节实现的MajorityVoteClassifier用于实战了。不过,先准备一个可以用于测试的数据集。既然已经熟悉了从CSV文件中读取数据的方法,我们就走捷径从scikit-learn的dataset模块中加载鸢尾花数据集。此外,为了使分类任务更具挑战,我们只选择其中的两个特征:萼片宽度和花瓣长度。虽然MajorityVoteClassifier可应用到多类别分类问题,但我们只区分两个类别的样本:Iris-Versicolor和Iris-Virginica,并绘制其ROC AUC。代码如下:

 请注意,我们可以使用scikit-learn中的predict_proba方法(如果适用)计算ROC AUC的评分。在第3章中,我们学习了如何通过逻辑斯谛回归模型来计算样本相对于各类别的归属概率;在决策树中,此概率是通过训练时为每个节点创建的频度向量(frequency vector)来计算的。此向量收集对应节点中通过类标分布计算得到各类标频率值。进而对频率进行归一化处理,使得它们的和为1。类似地,k-近邻算法中,也会收集各样本最相邻的k个邻居的类标,并返回归一化的类标频率。虽然决策树和k-近邻分类器都返回了与逻辑斯谛回归模型类似的概率值,但必须注意,这些值并非通过概率密度函数计算得到的。
请注意,我们可以使用scikit-learn中的predict_proba方法(如果适用)计算ROC AUC的评分。在第3章中,我们学习了如何通过逻辑斯谛回归模型来计算样本相对于各类别的归属概率;在决策树中,此概率是通过训练时为每个节点创建的频度向量(frequency vector)来计算的。此向量收集对应节点中通过类标分布计算得到各类标频率值。进而对频率进行归一化处理,使得它们的和为1。类似地,k-近邻算法中,也会收集各样本最相邻的k个邻居的类标,并返回归一化的类标频率。虽然决策树和k-近邻分类器都返回了与逻辑斯谛回归模型类似的概率值,但必须注意,这些值并非通过概率密度函数计算得到的。
下面我们将样本按照五五分划分为训练数据及测试数据:
![]()

我们使用训练数据集训练三种不同类型的分类器:逻辑斯谛回归分类器、决策树分类器及k-近邻分类器各一个,在将它们组合成集成分类器之前,我们先通过10折交叉验证看一下各个分类器在训练数据集上的性能表现:

我们得到的输出显示如以下代码段,单个分类器的预测性能几乎相同:

读者可能会感到奇怪,为什么我们将逻辑斯谛回归和k-近邻分类器的训练作为流水线的一部分?原因在于:如我们在第3章中所述,不同于决策树,逻辑斯谛回归与k-近邻算法(使用欧几里得距离作为距离度量标准)对数据缩放不敏感。虽然鸢尾花特征都以相同的尺度(厘米)度量,不过对特征做标准化处理是一个好习惯。
激动人心的时刻到了,我们现在基于多数投票原则,在MajorityVoteClassifier中组合各成员分类器:

正如我们所见,以10折交叉验证作为评估标准,MajorityVotingClassifier的性能与单个成员分类器相比有着质的提高。