
6.3 通过学习及验证曲线来调试算法
在本节,我们将学习两个有助于提高学习算法性能的简单但功能强大的判定工具:学习曲线(learning curve)与验证曲线(validation curve)。在下一小节中,我们将讨论如何使用学习曲线来判定学习算法是否面临过拟合(高方差)或欠拟合(高偏差)问题。此外,我们还将了解一下验证曲线,它可以帮助我们找到学习算法中的常见问题。
6.3.1 使用学习曲线判定偏差和方差问题
如果一个模型在给定训练数据上构造得过于复杂——模型中有太多的自由度或者参数——这时模型可能对训练数据过拟合,而对未知数据泛化能力低下。通常情况下,收集更多的训练样本有助于降低模型的过拟合程度。但是,在实践中,收集更多数据会带来高昂的成本,或者根本不可行。通过将模型的训练及准确性验证看作是训练数据集大小的函数,并绘制其图像,我们可以很容易看出模型是面临高方差还是高偏差的问题,以及收集更多的数据是否有助于解决问题。在讲解如何通过scikit-learn绘制学习曲线之前,我们先通过下图来讨论一下模型常见的两个问题:

左上方图像显示的是一个高偏差模型。此模型的训练准确率和交叉验证准确率都很低,这表明此模型未能很好地拟合数据。解决此问题的常用方法是增加模型中参数的数量,例如,收集或构建额外特征,或者降低类似于SVM和逻辑斯谛回归器等模型的正则化程度。右上方图像中的模型面临高方差的问题,表明训练准确度与交叉验证准确度之间有很大差距。针对此类过拟合问题,我们可以收集更多的训练数据或者降低模型的复杂度,如增加正则化的参数;对于不适合正则化的模型,也可以通过第4章介绍的特征选择,或者第5章中的特征提取来降低特征的数量。需要注意:收集更多的训练数据可以降低模型过拟合的概率。不过该方法并不适用于所有问题,例如:训练数据中噪声数据较多,或者模型本身已经接近于最优。
在下一小节中,我们将看到如何使用验证曲线来解决模型中存在的问题,不过先看一下如何使用scikit-learn中的学习曲线函数评估模型:

执行上述代码,可以得到如下学习曲线:
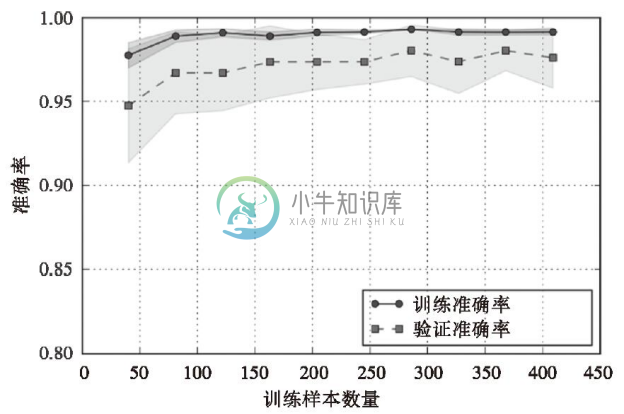
通过learning_curve函数的train_size参数,我们可以控制用于生成学习曲线的样本的绝对或相对数量。在此,通过设置train_sizes=np.linspace(0.1,1.0,10)来使用训练数据集上等距间隔的10个样本。默认情况下,learning_curve函数使用分层k折交叉验证来计算交叉验证的准确性,通过cv参数将k的值设置为10。然后,我们可以简单地通过不同规模训练集上返回的交叉验证和测试评分来计算平均准确率,并且,我们使用matplotlib的plot函数绘制出准确率图像。此外,在绘制图像时,我们通过fill_between函数加入了平均准确率标准差的信息,用以表示评价结果的方差。
通过前面学习曲线图像可见,模型在测试数据集上表现良好。但是,在训练准确率曲线与交叉验证准确率之间,存在着相对较小差距,这意味着模型对训练数据有轻微的过拟合。
6.3.2 通过验证曲线来判定过拟合与欠拟合
验证曲线是一种通过定位过拟合或欠拟合等诸多问题所在,来帮助提高模型性能的有效工具。验证曲线与学习曲线相似,不过绘制的不是样本大小与训练准确率、测试准确率之间的函数关系,而是准确率与模型参数之间的关系,例如,逻辑斯谛回归模型中的正则化参数C。我们继续看下如何使用scikit-learn来绘制验证曲线:


使用上述代码,我们可得到参数C的验证曲线图像:
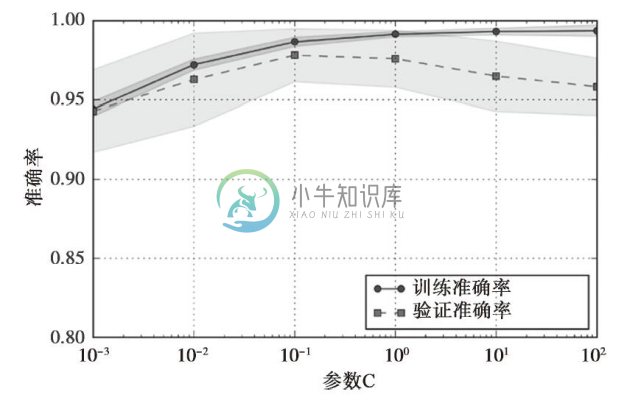
与learning_curve函数类似,如果我们使用的是分类算法,则validation_curve函数默认使用分层k折交叉验证来评价模型的性能。在validation_curve函数内,我们可以指定想要验证的参数。在本例中,需要验证的是参数C,即定义在scikit-learn流水线中的逻辑斯谛回归分类器的正则化参数,我们将其记为'clf_C',并通过param_range参数来设定其值的范围。与上一节的学习曲线类似,我们绘制了平均训练准确率、交叉验证准确率及对应的标准差。
虽然不同C值之间准确率的差异非常小,但我们可以看到,如果加大正则化强度(较小的C值),会导致模型轻微的欠拟合;如果增加C的值,这意味着降低正则化的强度,因此模型会趋向于过拟合。在本例中,最优点在C=0.1附近。