13.1 使用Theano构建、编译并运行表达式
在本节,我们将初步了解强大的Theano库,它能让我们使用Python高效地进行机器学习模型的训练。Theano最初是由Joshua Bengio领导的LISA(Laboratoire d'Informatique des Systèmes Adaptatifs)实验室[1]于2008年开发的。
在深入探究Theano到底是什么,以及它是如何提高机器学习任务处理速度之前,我们先来讨论一下当硬件运行极度耗费运算能力的程序时将会面临的挑战。幸运的是,计算机处理器的性能多年来持续提高,这使得我们可以训练更加强大、复杂的学习系统,从而提高机器学习模型的预测性能。即使是现在最便宜的计算机,其中央处理器也是多核的。在前面章节中,我们看到scikit-learn中的许多函数都可以通过使用多核处理器来提高计算性能。默认情况下,由于全局解释器锁(Global Interpreter Lock,GIL)的缘故,Python代码在执行时只能使用其中一个核。不过,尽管可以使用多线程运行(multiprocessing)库将计算分布到多个核上并行执行,我们也必须意识到,即使最先进的桌面硬件也很少能提供超过8个或者16个核心的计算单元。
回想上一章中,我们实现了一个非常简单的多层感知器模型,虽然它只有一个包含50个节点的隐层,但我们已经需要通过学习来优化大约1000个权重以完成一个非常简单的图像识别任务。MNIST库中的图像是非常小的(只有28×28像素),对于像素密度更高的图像来说,如果我们通过增加额外的隐层对其进行处理,那么可以想象参数数量将会呈现爆炸式增长。随着图像像素的增加,仅使用一个CUP来对其进行处理很快就会变得不可行。现在面临的问题是我们如何才能更加高效地处理此类问题?一个明显的解决方案就是使用GPU。GPU的性能确实很强大,读者可以将显卡看作是我们电脑中的一个小型计算机集群。另一个优势就是,与最新的CPU相比,GPU价格相对低廉,具体比较信息如下图所示:

以上信息来源于如下网站(2015年8月20日):
·http://www.geforce.com/hardware/desktop-gpus/geforce-gtx-980-ti/specifications
一块价格只有CPU 70%的GPU,内核数量却是前者的450倍,而且每秒浮点运算次数也是前者的15倍以上。那么是什么原因阻碍了我们使用GPU来执行机器学习任务呢?我们面临的挑战是:编写执行于GPU的代码不像在解释器中执行Python代码那样方便快捷,我们需要特殊的功能包,如CUDA和OpenCL等。但是,对于实现并运行机器学习算法来说,编写基于CUDA或者OpenCL的代码并不是最好的方案。好消息是,开发出Theano就是用来解决GPU上机器学习的问题。
[1] http://lisa.iro.umontreal.ca.
13.1.1 什么是Theano
Theano究竟是什么呢?一种编程语言?一个编译器?抑或是一个Python库?实际上,Theano兼具以上几种功能。Theano针对于多维数组(张量),能够高效地实现、编译和评估数学表达式。它同时还可以使得代码在GPU运行。不过,其强大性能的真实来源则是利用了GPU中巨大内存带宽以及GPU浮点数运算能力。我们使用Theano可以很容易地共享内存来并行运行代码。Theano开发者在2010年公布的测试报告中指出:在CPU上执行程序时,Theano程序的性能是NumPy的1.8倍,而在GPU上执行相应的代码,Theano速度是NumPy的11倍[1]。请注意,上面是2010年的测试结果,近几年来,无论是Theano还是显卡的性能都有了显著的提高。
那么,Theano和NumPy之间到底有何关系呢?Theano建立在NumPy的基础上并且与其语法相似,这使得熟悉NumPy的用户用起Theano来也得心应手。公正地说,Theano并不像许多人所描述的那样,是“NumPy的兴奋剂”,不过与SymPy(http://www.sympy.org)相类似,SymPy是一个用于符号计算(或者称其为符号代数)的Python包。正如前面章节中所介绍的,我们使用NumPy来描述变量,并组合这些变量,然后再逐行执行相关代码。不过在Theano中,我们首先要写出问题,然后分析问题给出描述。如果代码需要在GPU上运行,Theano可以使用C/C++,或者CUDA/OpenCL生成相应的代码。为了能够生成最优化的代码,我们需要指出待解决问题的领域,可以将其看作是由许多操作构成的树(或者是关于图的符号表达)。请注意,Theano当前仍处于开发活跃阶段,会定期加入新的功能或更新现有功能。在本章,我们首先探究Theano背后的基本概念,然后进一步学习如何将其用于机器学习实践中。由于Theanno是一个包含许多先进功能的库,我们无法在本书中覆盖其所有内容。不过,如果读者希望了解更多关于Theano的内容,可以访问在线文档(http://deeplearning.net/software/theano/)获取更加详细的信息。
[1] J. Bergstra, O. Breuleux, F. Bastien, P. Lamblin, R. Pascanu, G. Desjardins, J. Turian, D. Warde-Farley, and Y.Bengio. Theano: A CPU and GPU Math Compiler in Python. In Proc. 9th Python in Science Conf, pages 1-7,2010.
13.1.2 初探Theano
本节中,我们将迈出学习Theano的第一步。根据系统的设置,通常可以使用pip安装Theano,请在命令行窗口中执行如下命令:
![]()
对于安装过程中可能出现的问题,建议读者通过如下链接:http://deeplearning.net/software/theano/install.html,了解关于系统和平台方面的具体建议。本章中的所有代码均可在CPU中运行;虽然GPU是可选的,但如果读者想体会Theano的真实性能,建议选配。如果读者拥有支持CUDA或者OpenCL的显卡,请参照相关最新教程http://deeplearning.net/software/theano/tutorial/using_gpu.html#using-gpu进行合理的配置。
张量是Theano的核心元素,Theano使用张量对符号数学表达式进行评估。张量可以看作是标量、向量、矩阵等的泛化。具体而言,标量可以定义为0阶张量,而向量和矩阵则可以分别定义为1阶张量和2阶张量,而在第三维上对矩阵的叠加则为3阶张量。作为热身,我们先通过Theano的tensor模块中的标量来计算一维数据样本点x的净输入z,其中权重为w1,偏置值为w0:
![]()
代码如下:

![]()
这种方法是不是简单直接?如果我们在Theano写代码,只须遵循三个步骤:定义符号(变量对象),编译代码,执行代码。初始化阶段,我们定义了三个符号:x1、w1和w0,用来计算z1。然后对函数net_input进行编译,计算出净输入z1。
不过,当我们开发基于Theano的代码时,有一个需要特别注意的细节:变量的类型(dtype)。无论如何,我们在使用整型或者浮点型数据时,需要考虑选择使用64位还是32位的表示方式,这将对代码性能产生极大的影响。我们将在下一节中对此进行更深入的讨论。
13.1.3 配置Theano
无论是macOS、Linux,还是微软的Windows操作系统,系统和应用程序主要都使用64位内存寻址方式。但是,如果想要使用GPU加速评估数学表达式,我们依然依赖于32位的内存寻址方式。这是目前Theano唯一支持的计算架构。本节中,我们将学习如何合理地配置Theano。如果读者对与Theanno配置相关的更多细节感兴趣,请参考在线文档:http://deeplearning.net/software/theano/library/config.html,当实现机器学习算法时,我们主要使用浮点数。默认情况下,NumPy和Theano都使用双精度浮点格式(float64)。不过,当我们在CPU上使用Theano代码开发原型,并将其放到GPU上执行运算时,将浮点数精度在float64(CPU)和float32(GPU)之间来回转换是非常有用的。例如,在Python交互环境下,我们可以执行下面的代码查看Theano中浮点变量的默认设置:
![]()
如果读者在安装Theano后未对设置做任何修改,浮点数的默认设置应为64位。不过,我们可以使用下列代码将其在当前Python交互下的设置更改为32位:
![]()
请注意,虽然Theano目前在GPU上使用32位浮点类型,但在CPU上64位和32位浮点类型都可以使用。因此,如果读者想要更改全局默认设置,可以在命令行(Bash)终端中修改THEANO_FLAGS变量的值:
![]()
此外,也可以将此设置写入特定的Python脚本中,并通过以下方式运行脚本:
![]()
至此,我们已经讨论了如何设置浮点数的默认格式,使得Theano在GPU上发挥最大的性能。接下来,我们讨论代码的执行位置在CPU和GPU之间切换的配置选项。执行如下代码,我们可以检查当前使用的是CPU还是GPU:
![]()
我的个人建议是默认使用cpu,这样设计原型和调试代码就更加容易。例如,在CPU上,我们可以在命令行终端中以脚本的方式来运行Theano代码:
![]()
当我们完成了对程序的编码,并希望尽可能发挥GPU的最大性能来高效运行这些代码时,可以执行如下代码,它无须对原始程序做任何修改:
![]()
我们可以在个人的主目录下创建一个.theanorc文件来永久保存这些设置。例如,如果想始终使用32位浮点格式和GPU,可以通过下述命令创建一个包含此设置的.theanorc的文件:
![]()
如果读者并未使用macOS或者Linux终端,可以使用自己熟悉的文本编辑器来手工创建一个.theanorc文件,文件内容如下:

现在我们已经知道了如何根据硬件情况对Theano做适当配置,在下一节,我们将讨论如何使用更加复杂的阵列结构。
13.1.4 使用数组结构
在本节,我们将讨论如何通过Theano中的tensor模块使用数组结构。执行下列代码,我们可以创建一个简单的2×3矩阵,并使用优化过的Theano张量表达式计算数组中各列之和:

如前所述,使用Theano只需遵循3个基本步骤:定义变量、编译以及执行代码。上例显示Theano可以处理Python和NumPy的数据格式:列表(list)和数组(numpy.ndarry)
 注意:在创建TensorVariable的fmatrix变量时,我们使用了可选的名称参数(在此为x),这对调试代码或者输出Theano图来说非常有用。例如,若未使用此名称参数,则输出变量名为x的fmatrix时,实际显示结果是其类型TesnsorType:
注意:在创建TensorVariable的fmatrix变量时,我们使用了可选的名称参数(在此为x),这对调试代码或者输出Theano图来说非常有用。例如,若未使用此名称参数,则输出变量名为x的fmatrix时,实际显示结果是其类型TesnsorType:
![]()
但如果在初始化TensorVariable时,像示例代码那样指定了名称参数x,则会显示此参数:
![]()
此时可通过type方法获取TensorType:
![]()
Theano还拥有一个非常智能的内存管理系统,通过对内存的复用使得系统运行速度更快。具体来说,Theano可以管理散布在多种硬件上的存储空间,如CPU和GPU。通过跟踪内存空间的变化,它可以对缓冲区进行镜像。接下来,我们来看一下shared变量,它允许我们使用大型对象(数组),这些对象可以被多种类型的函数读写,这样我们就可以在编译后对更新这些对象。关于Theano内存处理的更详细介绍超出了本书的范围。读者可通过链接http://deeplearning.net/software/theano/tutorial/aliasing.html获取Theano内存管理的最新信息。

正如我们所见,通过Theano共享内存是很容易的。在上一个例子中,我们定义了一个update变量,并通过此变量声明:在for循环每次迭代后,数组w加1以更新。在定义了要更新的对象,以及如何进行更新之后,我们便可以通过update参数将其传递给theano.function进行编译。
使用Theano的另一个巧妙方法就是:在编译之前通过givens变量在图中加入新的值[1]。使用这种方法,借助于共享变量,我们可以降低通过CPU将数据从内存传输到GPU的次数,从而加速算法的学习速度。如果我们在theano.function中使用了inputs参数,数据将会在CPU和GPU之间多次传输,例如,在梯度下降中,我们需对数据进行多次循环遍历(迭代)。如果数据集能够加载到GPU内存中,使用givens它就可以在训练过程中得以保持(例如,通过子批次进行学习)。代码如下:

由上述示例代码,我们还可发现:givens值的格式是Python字典,它可以将变量名映射到真实的Python对象上。其中,变量名与我们在fmatrix中定义的名字相同。
[1] Theano会将计算过程编译成一个图模型。——译者注
13.1.5 整理思路——线性回归示例
现在我们已经对Theano有了初步的认识,再来看一个非常实际的例子,并实现一个基于最小二乘法(Ordinary Least Squares,OLS)的回归。关于回归分析的相关内容,请参见第10章。
让我们从创建包含5个训练样本的一维数据集开始:

请注意,在构造NumPy数组时,我们将数据格式设定为theano.config.floatX,这使得我们可以在需要时将数据在CPU和GPU之间来回传递。
接下来,我们来实现一个训练函数,以误差平方和作为代价函数,它可以通过学习得到线性回归模型的回归系数。其中,w0为偏置单元(x=0时y轴上的截距)。代码如下:

上述示例代码中的grad函数是Theano的一个非常实用的功能。我们通过wrt传递参数,此函数可以自动计算表达式相对于参数的导数。
在实现了训练函数后,我们训练线性回归模型,并通过查看误差平方和代价函数的值来检验模型是否收敛:

如下图所示,学习算法在经过5次迭代后就已经收敛:

到目前为止一切进展顺利,通过查看代价函数,我们似乎已经在此特定数据集上构建了一个可用的回归模型。现在,我们编译一个新的函数,用来对输入的特征进行预测:

实现预测函数也相当简单,只需遵循Theano的三个步骤:定义、编译和执行。接下来,我们绘制出线性回归在训练数据上的拟合情况:

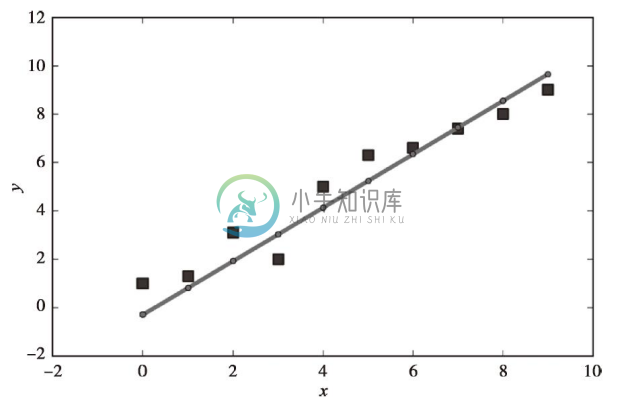
由结果图像可以看出,模型恰当地拟合了数据点。
构建简单的回归模型是熟悉Theano API的一个很好的方式。不过,我们的最终目标是发挥出Theano的优势,也就是实现高效的人工神经网络。现在我们已经拥有了实现第12章中多层感知器所需的工具:Theano。不过实现起来依然让人感到枯燥,对吗?因此,我们来学习一下我个人最喜欢的一个深度学习库,它构建在Theano之上,可以尽可能简单地实现神经网络相关的实验。不过,在介绍Keras库之前,我们先在下一节中讨论一下如何选择神经网络中的激励函数。