
4.6 通过随机森林判定特征的重要性
在前面几节,我们学习了如何在逻辑斯谛回归上通过L1正则化将不相关特征剔除,并且学习了用于特征选择的SBS算法。另一种从数据集中选择相关特征的有效方法是使用随机森林,也就是在第3章中介绍的集成技术。我们可以通过森林中所有决策树得到的平均不纯度衰减来度量特征的重要性,而不必考虑数据是否线性可分。更加方便的是:scikit-learn中实现的随机森林已经为我们收集好了关于特征重要程度的信息,在拟合了RandomForestClassifier后,可以通过feature_importances_得到这些内容。执行以下代码,可在葡萄酒数据集上训练10000棵树,并且分别根据其重要程度对13个特征给出重要性等级。请记住(在第3章中曾讨论过的):无需对基于树的模型做标准化或归一化处理。代码如下:


执行上述代码后,根据特征在葡萄酒数据集中的相对重要性,绘制出根据特征重要性排序的图,请注意,这些特征重要性经过归一化处理,其和为1.0。
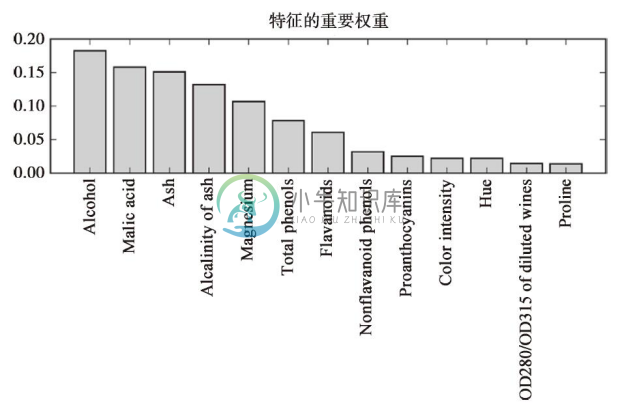
由上图我们可以得到结论:基于10000棵决策树平均不纯度衰减的计算,数据集上最具判别效果的特征是“alcohol”。有趣的是,上图中排名靠前的四个特征中有三个也出现在前面章节中使用SBS算法所选的五个特征中。不过,就可解释性而言,随机森林有一个重要的特性值得一提。例如:如果两个或者更多个特征是高度相关的,一个特征的相关特征未被完全包含进来,那么此特征可能会得到一个较高的评分。另一方面,如果我们的关注点仅在模型的预测性能上,而不关心对特征重要性解释,那么就不必纠缠于上述问题。在总结本小节关于特征重要性和随机森林的内容之前,需要提醒一下:在完成对模型的拟合后,scikit-learn还实现了一个transofrm方法,可以在用户设定阈值的基础上进行特征选择,这在我们将RandomForestClassifier作为特征选择器,并将其作为scikit-learn实现分析流程环节中的一个步骤时尤为有效,它使得我们可以通过同一个预估器来连接不同的预处理步骤,我们将在第6章中对这些相关内容进行探讨。例如,将阈值设为0.15,我们可以使用下列代码将数据集压缩到三个最重要的特征:Alcohol、Malic acid和Ash:
