
6.4 使用网格搜索调优机器学习模型
在机器学习中,有两类参数:通过训练数据学习得到的参数,如逻辑斯谛回归中的回归系数;以及学习算法中需要单独进行优化的参数。后者即为调优参数,也称为超参,对模型来说,就如逻辑斯谛回归中的正则化系数,或者决策树中的深度参数。
在上一节中,我们使用验证曲线通过调优超参提高模型的性能。本节中,我们将学习一种功能强大的超参数优化技巧:网格搜索(grid search),它通过寻找最优的超参值的组合以进一步提高模型的性能。
6.4.1 使用网络搜索调优超参
网格搜索法非常简单,它通过对我们指定的不同超参列表进行暴力穷举搜索,并计算评估每个组合对模型性能的影响,以获得参数的最优组合。

使用上述代码,我们初始化了一个sklearn.grid_search模块下的GridSearchCV对象,用于对支持向量机流水线的训练与调优。我们将GridSearchCV的param_grid参数以字典的方式定义为待调优的参数。对线性SVM来说,我们只需调优正则化参数(C);对基于RBF的核SVM来说,我们同时需要调优C和gamma参数。请注意此处的gamma是针对核SVM特别定义的。在训练数据集上完成网格搜索后,可以通过best_scroe_属性得到最优模型的性能评分,具体参数信息可通过best_params_属性得到。在本例中,当'cfl_C'=0.1时,线性SVM模型可得到的最优k折交叉验证准确率为97.8%。
最后,我们将使用独立的测试数据集,通过GridSearchCV对象的best_estimator_属性对最优模型进行性能评估:

 虽然网格搜索是寻找最优参数集合的一种功能强大的方法,但评估所有参数组合的计算成本也是相当昂贵的。使用scikit-learn抽取不同参数组合的另一种方法就是随机搜索(randomized search)。借助于scikit-learn中的RandomizedSearchCV类,我们可以以特定的代价从抽样分布中抽取出随机的参数组合。关于此方法的更详细细节及其示例请访问链接:http://scikit-learn.org/stable/modules/grid_search.html#randomized-parameter-optimization。
虽然网格搜索是寻找最优参数集合的一种功能强大的方法,但评估所有参数组合的计算成本也是相当昂贵的。使用scikit-learn抽取不同参数组合的另一种方法就是随机搜索(randomized search)。借助于scikit-learn中的RandomizedSearchCV类,我们可以以特定的代价从抽样分布中抽取出随机的参数组合。关于此方法的更详细细节及其示例请访问链接:http://scikit-learn.org/stable/modules/grid_search.html#randomized-parameter-optimization。
6.4.2 通过嵌套交叉验证选择算法
在上一节中我们看到,结合网格搜索进行k折交叉验证,通过超参数值的改动对机器学习模型进行调优,这是一种有效提高机器学习模型性能的方法。如果要在不同机器学习算法中做出选择,则推荐另外一种方法——嵌套交叉验证,在一项对误差估计的偏差情形研究中,Varma和Simon给出了如下结论:使用嵌套交叉验证,估计的真实误差与在测试集上得到的结果几乎没有差距[1]。
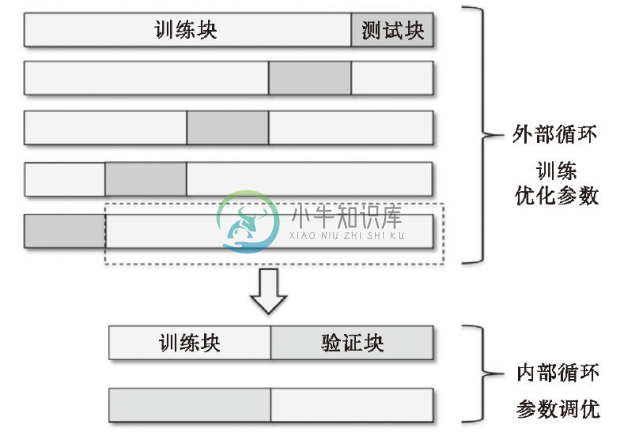
在嵌套交叉验证的外围循环中,我们将数据划分为训练块及测试块;而在用于模型选择的内部循环中,我们则基于这些训练块使用k折交叉验证。在完成模型的选择后,测试块用于模型性能的评估。下图通过5个外围模块及2个内部模块解释了嵌套交叉验证的概念,这适用于计算性能要求比较高的大规模数据集。这种特殊类型的嵌套交叉验证也称为5×2交叉验证(5×2 cross-validation):
借助于scikit-learn,我们可以通过如下方式使用嵌套交叉验证:

代码返回的交叉验证准确率平均值对模型超参调优的预期值给出了很好的估计,且使用该值优化过的模型能够预测未知数据。例如,我们可以使用嵌套交叉验证方法比较SVM模型与简单的决策树分类器;为了简单起见,我们只调优树的深度参数:


在此可见,嵌套交叉验证对SVM模型性能的评分(97.8%)远高于决策树的(90.8%)。由此,可以预期:SVM是用于对此数据集未知数据进行分类的一个好的选择。
[1] A.Varma and R.Simon.Bias in Error Estimation When Using Cross-validation for Model Selection.BMC bioinformatics,7(1):91,2006.