
机器学习:使用Python - 简介Scikit-learn 机器学习
Scikit-learn 套件的安装
目前Scikit-learn同时支持Python 2及 3,安装的方式也非常多种。对于初学者,最建议的方式是直接下载 Anaconda Python (https://www.continuum.io/downloads)。同时支持 Windows / OSX/ Linux 等作业系统。相关数据分析套件如Scipy, Numpy, 及图形绘制库 matplotlib, bokeh 会同时安装。
开发介面及环境
笔者目前最常用的开发介面为IPython Notebook (3.0版后已改名为Jupyter Notebook) 以及 Atom.io 文字编辑器。在安装Anaconda启用IPython Notebook介面后,本文件连结之程式码皆能够以複制贴上的方式执行测试。目前部份章节也附有notebook格式文件 .ipynb档可借下载。
给机器学习的初学者
本文件的目的并非探讨机器学习的各项理论,我们将以应用范例着手来帮助学习。其中建议以手写数字辨识来当成的敲门砖。而本文件中,有以下范例介绍手写数字辨识,并且藉由这个应用来探讨机器学习中的一个重要类别「监督式学习」。一开始,建议先从 机器学习资料集 Datasets,来了解资料集的型态以及取得方式。接下来最重要的是釐清特征X以及预测目标y之间的关係。要注意这边的大写的X通常代表一个矩阵, 每一列代表一笔资料,而每一行则代表其特征。例如手写数字辨识是利用 8x8的影像资料,来当成训练集。而其中一种特征的取用方法是例用这64个像素的灰阶值来当成特征。而小写的y则代表一个向量,这个向量记录着前述训练资料对应的「答案」。
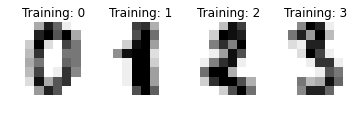
了解资料集之后,接下来则建议先尝试 分类法范例一例用最简单的支持向量机(Support Vector Machine)分类法来达成多目标分类 (Multi-class classification),这裏的「多目标」指的是0到9的数字,该范例利用Scikit-learn内建的SVM分类器,来找出十个目标的分类公式,并介绍如何评估分类法的准确度,以及一些常见的分类指标。例如以下报表标示着对于10个数字的预测准确度。 有了对这个范例的初步认识之后,读者应该开始感觉到监督式学习(Supervised learning)的意义,这裏「监督」的意思是,我们已经知道资料所对应的预测目标,也就是利用图形可猜出数字。也就是训练集中有y。而另一大类别「非监督式学习」则是我们一开始并不知道y,我们想透过演算法来将y找出来。例如透过购买行为及个人资料来分类消费族群。
precision recall f1-score support0 1.00 0.99 0.99 881 0.99 0.97 0.98 912 0.99 0.99 0.99 863 0.98 0.87 0.92 914 0.99 0.96 0.97 925 0.95 0.97 0.96 916 0.99 0.99 0.99 917 0.96 0.99 0.97 898 0.94 1.00 0.97 889 0.93 0.98 0.95 92avg / total 0.97 0.97 0.97 899
而有了基本的分类法,接下来的范例则是利用特征选择来更增进分类的准确性。以手写数字辨识来说。上述的例子共使用了64个像素来当成特征,然而以常理来判断。这64个像素中,处于影像边缘的像素参考价值应该不高,因为手写的笔画鲜少出现在该处。若能将这些特征资料排除在分类公式中,通常能再增进预测的准确度。而「特征选择」的这项技术,主要就是用来处理这类问题。特征选择范例二:Recursive Feature Elimination则是利用了Scikit-learn内建的特征消去法,来找出消去那些特征能够最佳化预测的准确度。而 特征选择范例三:Recursive Feature Elimination with Cross-Validation 则使用了更进阶的交叉验证法来切分训练集以及挑战集来评估准确程度。建议读者可以尝试这几个范例,一步步去深入机器学习的核心。