
应用范例 Application - 波士顿房地产云端评估(二)
支持向量机回归分析: Property value prediction
此档案使用scikit-learn 机器学习套件里的SVR演算法,来达成波士顿房地产价钱预测
(一)引入函式库及内建波士顿房地产资料库
引入之函式库如下
sklearn.datasets: 用来汇入内建之波士顿房地产资料库sklearn.SVR: 支持向量机回归分析之演算法matplotlib.pyplot: 用来绘制影像
from sklearn import datasetsfrom sklearn.svm import SVRimport matplotlib.pyplot as pltboston = datasets.load_boston()X=boston.datay = boston.target
使用 datasets.load_boston() 将资料存入至boston。
使用datasets.data将士顿房地产资料的数据资料(data)汇入到X。
使用datasets.target将士顿房地产资料的预测数值汇入到y。
为一个dict型别资料,我们看一下资料的内容。
(二)SVR的使用
sklearn.svm.SVR(kernel=’rbf’, degree=3, gamma=’auto’, coef0=0.0, tol=0.001, C=1.0, epsilon=0.1, shrinking=True, cache_size=200, verbose=False, max_iter=-1)
clf = SVR(kernel='rbf', C=1e3, gamma=0.1)clf.fit(X, y)
使用clf = SVR(kernel='rbf', C=1e3, gamma=0.1),将SVR演算法引入到clf,并设定SVR演算法的参数。
使用clf.fit(X, y),用波士顿房地产数据(boston.data)以及预测目标(y)来训练预测机clf
(三)使用joblib.dump汇出预测器
from sklearn.externals import joblibjoblib.dump(clf,"./machine_SVR.pkl")
使用joblib.dump将SVR预测器汇出为pkl档。
(四)训练以及分类
接着使用clf=joblib.load("./machine_SVR.pkl")将pkl档汇入为一个SVR预测器clf。接着使用波士顿房地产数据(boston.data),以及预测目标(y)来训练预测机clf clf.fit(boston.data, y)。最后,使用predict_y=clf.predict(boston.data[2])预测第三笔资料的价格,并将结果存入predicted_y变数。
clf=joblib.load("./machine_SVR.pkl")clf.fit(boston.data, y)predict_y=clf.predict(boston.data[2])
(五)使用score计算准确率
先用predict=clf.predict(X)将所有波士顿房地产数据丢入clf预测机预测,并将所预测出的结果存入predict。接着使用clf.score(X, y)来计算准确率,score=1为最理想情况,本范例中score=0.99988275378631286
predict=clf.predict(X)clf.score(X, y)
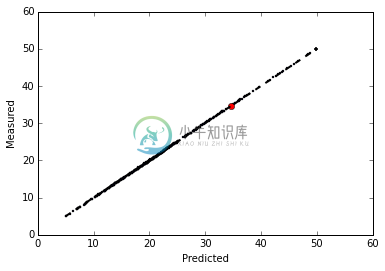
(六)绘出预测结果与实际目标差异图
X轴为预测结果,Y轴为回归目标。
并划出一条斜率=1的理想曲线(用虚线标示)。
红点为房地产第三项数据的预测结果
因为使用clf的准确率很高,所以预测结果与回归目标几乎一样,scatter的点会几乎都在理想曲线上。
plt.scatter(predict,y,s=2)plt.plot(predict_y, predict_y, 'ro')plt.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=2)plt.xlabel('Predicted')plt.ylabel('Measured')
(六)完整程式码
%matplotlib inlinefrom sklearn import datasetsfrom sklearn.svm import SVRimport matplotlib.pyplot as pltboston = datasets.load_boston()X=boston.datay = boston.targetclf = SVR(kernel='rbf', C=1e3, gamma=0.1)clf.fit(X, y)from sklearn.externals import joblibjoblib.dump(clf,"./machine_SVR.pkl")clf=joblib.load("./machine_SVR.pkl")clf.fit(boston.data, y)predict_y=clf.predict(boston.data[2])predict=clf.predict(X)clf.score(X, y)plt.scatter(predict,y,s=2)plt.plot(predict_y, predict_y, 'ro')plt.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=2)plt.xlabel('Predicted')plt.ylabel('Measured')