
类神经网路 Neural_Networks - Ex 4: Varying regularization in Multi-layer Perceptron
http://scikit-learn.org/stable/auto_examples/neural_networks/plot_mlp_alpha.html
此范例是比较不同的正归化参数’alpha’,对于使用scikit-learn的资料产生器
,所产生的circles、 moon
和random n-class classification,三种资料集的成效。
PS:正规化为一种处理无限大、发散以及一些不合理表示式的方法,透过引入一项辅助性的概念——正规子(regulator),去限制函数使得函数不会发散
此处的Alpha参数即为正规子,目的是去限制权重(Weight,W)的大小,以防万一overfitting与underfitting的问题,增加alpha值可能可以处理overfitting,反之减小alpha可能可以解决underfitting的问题,至于权重大小,如何影响输出请看图1: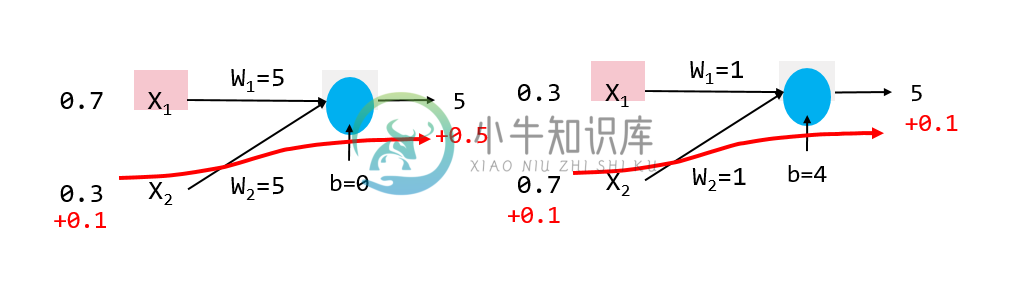
图1:比较同样输入,对于不同大小权重值,对于输出的影响左图为权重为5时,当输入变动0.1时,输出增加0.5,即输出改变10%,右图为权重为1时,当输入变动0.1时,输出增加0.1,即输出改变2%,通常模型对于input较不敏感,模型表现较好
结果将显示出:使用不同alpha值去限制权重产生出的决策边界
(一)引入函式库
print(__doc__)# Author: Issam H. Laradji# License: BSD 3 clauseimport numpy as npfrom matplotlib import pyplot as pltfrom matplotlib.colors import ListedColormapfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.datasets import make_moons, make_circles, make_classificationfrom sklearn.neural_network import MLPClassifier
(二)设定模型参数与产生资料
h = .02 # step size in the meshalphas = np.logspace(-5, 3, 5)#names = []for i in alphas:names.append('alpha ' + str(i))classifiers = []for i in alphas:classifiers.append(MLPClassifier(alpha=i, random_state=1))X, y = make_classification(n_features=2, n_redundant=0, n_informative=2,random_state=0, n_clusters_per_class=1)rng = np.random.RandomState(2)X += 2 * rng.uniform(size=X.shape)linearly_separable = (X, y)datasets = [make_moons(noise=0.3, random_state=0),make_circles(noise=0.2, factor=0.5, random_state=1),linearly_separable]figure = plt.figure(figsize=(17, 9))i = 1# iterate over datasetsfor X, y in datasets:# preprocess dataset, split into training and test partX = StandardScaler().fit_transform(X)X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.4)x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5xx, yy = np.meshgrid(np.arange(x_min, x_max, h),np.arange(y_min, y_max, h))
(三)绘制图形
# just plot the dataset firstcm = plt.cm.RdBucm_bright = ListedColormap(['#FF0000', '#0000FF'])ax = plt.subplot(len(datasets), len(classifiers) + 1, i)# Plot the training pointsax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright)# and testing pointsax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright, alpha=0.6)ax.set_xlim(xx.min(), xx.max())ax.set_ylim(yy.min(), yy.max())ax.set_xticks(())ax.set_yticks(())i += 1# iterate over classifiersfor name, clf in zip(names, classifiers):ax = plt.subplot(len(datasets), len(classifiers) + 1, i)clf.fit(X_train, y_train)score = clf.score(X_test, y_test)# Plot the decision boundary. For that, we will assign a color to each# point in the mesh [x_min, x_max]x[y_min, y_max].if hasattr(clf, "decision_function"):Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])else:Z = clf.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1]# Put the result into a color plotZ = Z.reshape(xx.shape)ax.contourf(xx, yy, Z, cmap=cm, alpha=.8)# Plot also the training pointsax.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap=cm_bright)# and testing pointsax.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap=cm_bright,alpha=0.6)ax.set_xlim(xx.min(), xx.max())ax.set_ylim(yy.min(), yy.max())ax.set_xticks(())ax.set_yticks(())ax.set_title(name)ax.text(xx.max() - .3, yy.min() + .3, ('%.2f' % score).lstrip('0'),size=15, horizontalalignment='right')i += 1figure.subplots_adjust(left=.02, right=.98)plt.show()
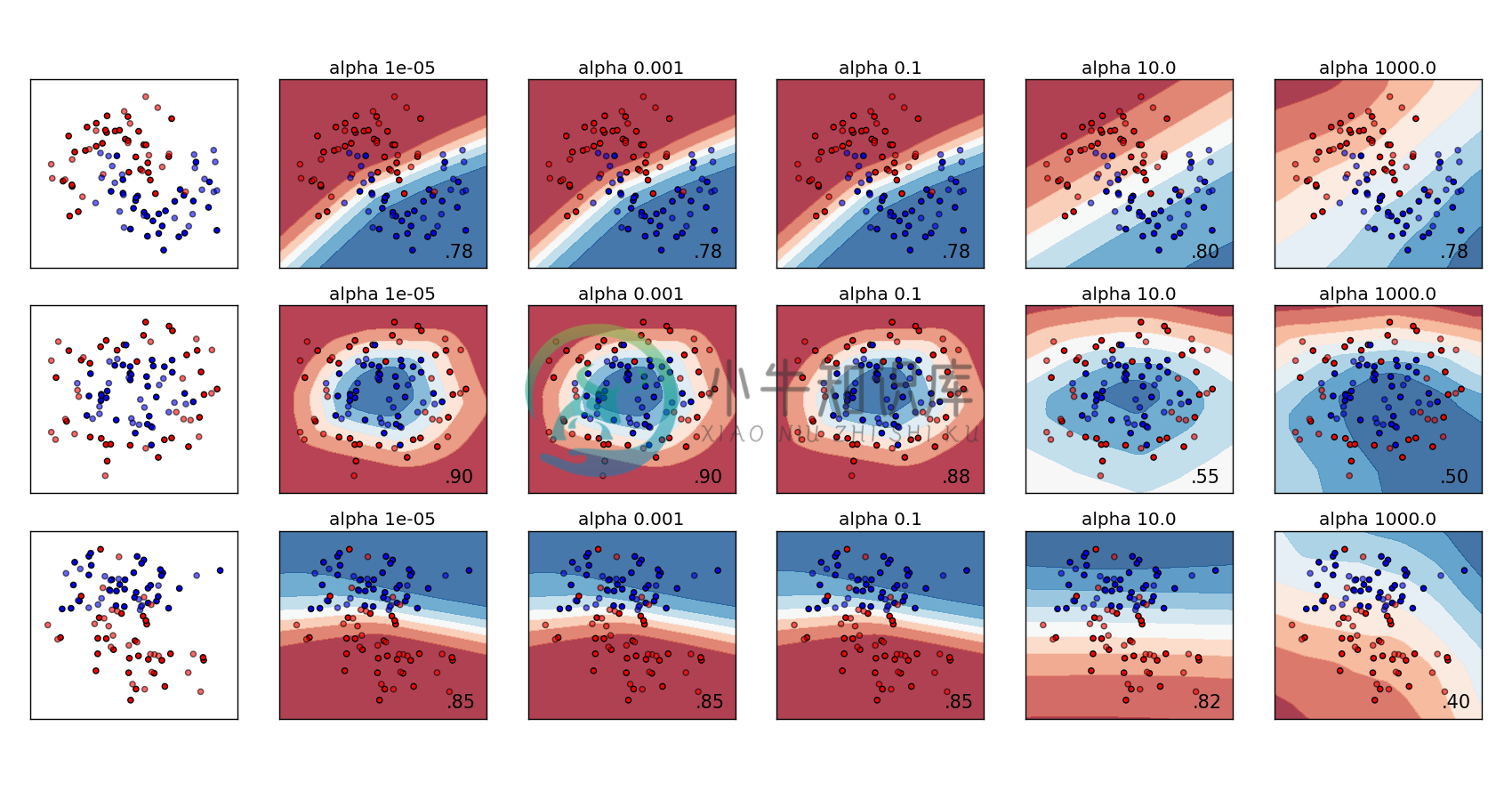
图2:不同alpha结果图,每张子图右下角是分辨率,alpha值很大,模型的结果明显underfitting