
分类神经网络不学习

我正在建立一个分类神经网络,以便对两个不同的类进行分类。
所以这是一个二元分类问题,我正尝试用一个前馈神经网络来解决这个任务。
但是网络是不能学习的,事实上,在训练过程中,网络的精度是不变的。
具体而言,数据集由以下人员组成:
- 65673行22列。
其中一列是具有值(0,1)的目标类,而其他21列是预测器。数据集是这样平衡的:
-
null

可以看到也有NaN值,但我不能删除它,因为在其他列中有值0是有意义的。
我决定对我的数据进行相关性分析,我得到了:
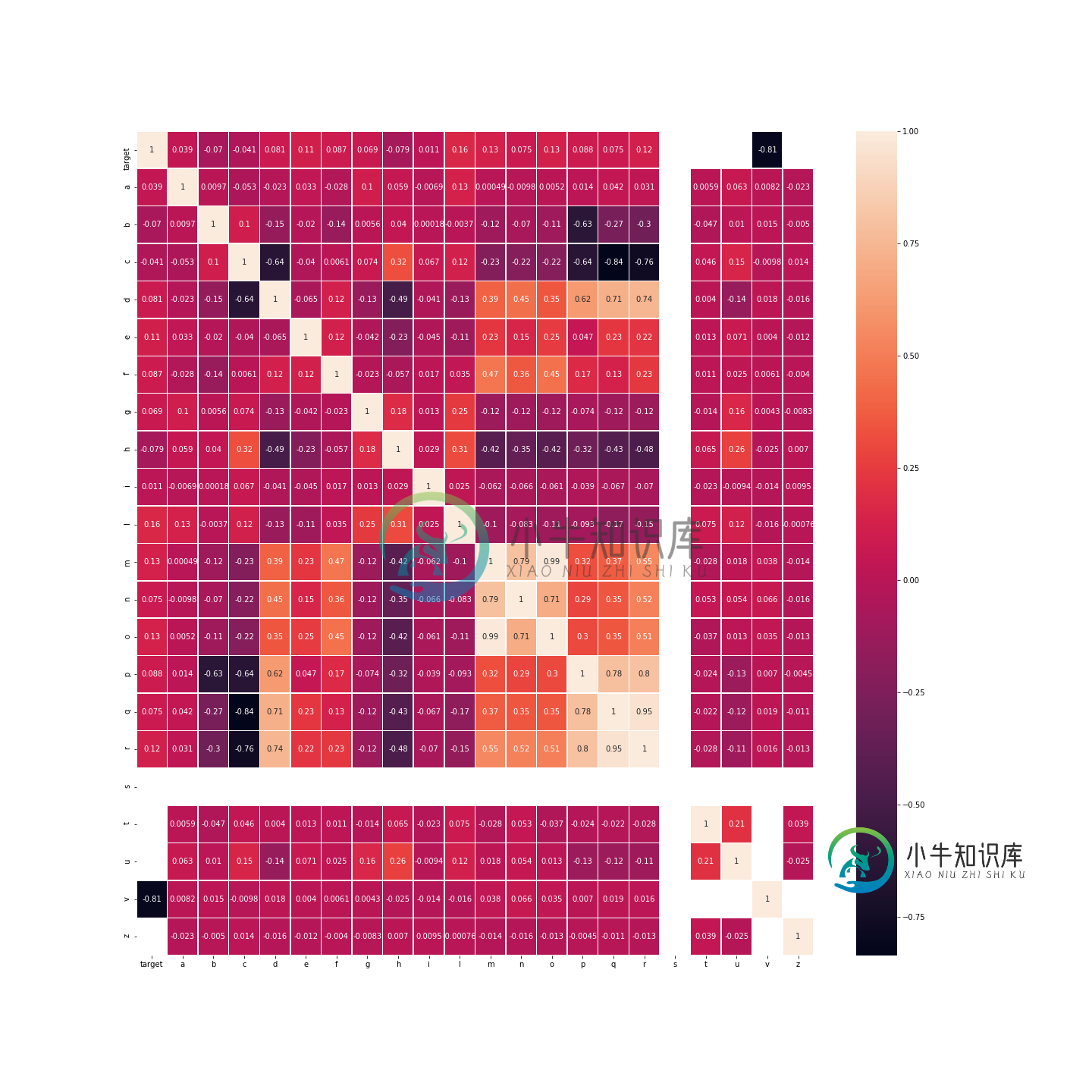
由于目标是对目标值进行分类(或预测),如相关矩阵所示,列[s,t,u,v,z]似乎与目标列不相关。此外,列:
-
null
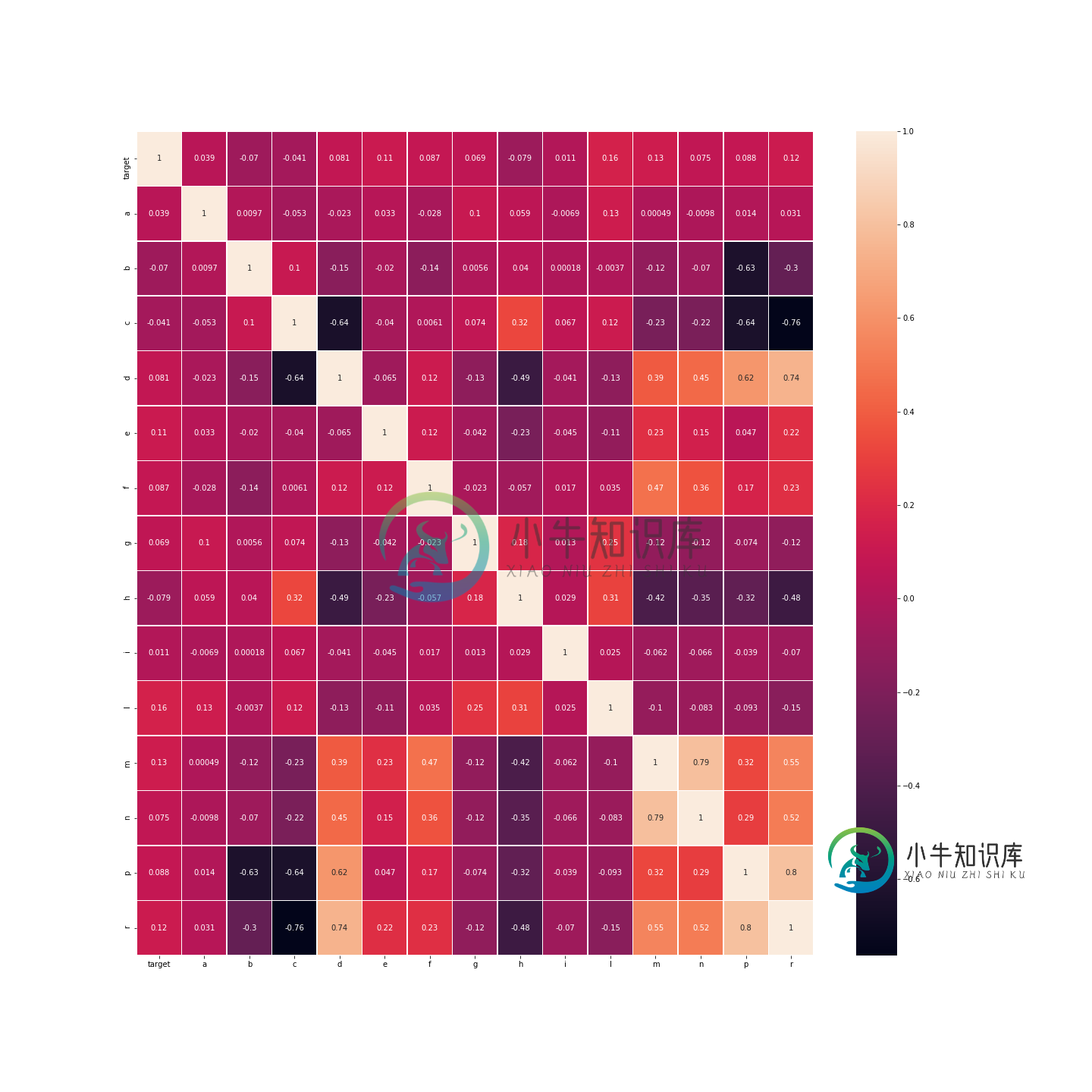
所以我也去掉了o列和Q列。
我得到了这样的情况:
之后,我对dataset进行了划分,以获得目标列和预测器列:
X= dataset.iloc[:,1:dataset.shape[1]]
y= dataset.iloc[:,0]
from keras.optimizers import Adam
from keras.layers import ReLU
model = Sequential()
model.add(Dense(X.shape[1], kernel_initializer='random_uniform',input_shape=(X.shape[1],)))
model.add(ReLU())
model.add(Dropout(0.1))
model.add(Dense(8))
model.add(ReLU())
model.add(Dropout(0.1))
model.add(Dense(4))
model.add(ReLU())
model.add(Dropout(0.1))
model.add(Dense(1, activation='sigmoid'))
opt = Adam(lr=0.00001, beta_1=0.9, beta_2=0.999, amsgrad=False)
model.compile(loss="binary_crossentropy", optimizer = opt, metrics=["accuracy"])
model.fit(X,y, batch_size=64, epochs=100, validation_split=0.25)
Epoch 2/100 49254/49254
Epoch 3/100 49254/49254
Epoch 4/100 49254/49254
Epoch 5/100 49254/49254
Epoch 6/100 49254/49254
Epoch 7/100 49254/49254
Epoch 8/100 49254/49254
Epoch 9/100 49254/49254
Epoch 10/100 49254/49254
...。
Epoch 98/100 49254/49254[==========================================================]-2S 49US/步进-损失:0.6878-Acc:0.5516-Val_Loss:0.6881-Val_Acc:0.5503
99/100年49254/49254[============================================================================]-2S 49US/步进-损失:0.6878-Acc:0.5516-Val_Loss:0.6881-Val_Acc:0.5503
Epoch 100/100 49254/49254
正如你所看到的,精确度始终保持不变,这是唯一一个我能看到损失函数有一些变化的模型。
我想做的是:
- 在所有层中使用Sigmoid激活函数
- 增加节点数和隐藏层数
- 在所有层中添加l2惩罚
- 使用不同的学习速率(从0.01到0.000001)
- 减少或增加BATCH_SIZE
但在所有情况下,结果都是一样的,甚至更糟。
关于归一化问题,是不是按照最小最大归一化对它们进行了归一化?
有人能帮助我更好地理解这个问题吗?非常感谢。
共有1个答案

你的神经网络小得离谱,这与一个离谱的小学习率成对。
至少应执行以下操作:
- 将您的学习率提高到0.001
- 将神经元数量增加到16、32个(为什么不增加第三层64个)
-
我试图用两个感知器网络做一个异或门,但由于某种原因,网络没有学习,当我在图中绘制误差的变化时,误差达到一个静态水平,并在该区域振荡。 目前我没有给网络添加任何偏见。 这是错误随着学习轮数的变化而变化。这是正确的吗?红色线是我所期望的错误将如何改变的线。
-
我用两个输出神经元会得到更好的结果吗?(一个激活为“是音乐”,另一个激活为“不是音乐”)。 (您可以在这里看到这方面的C++源代码:https://github.com/mcmenaminadrian/musonet--尽管在任何给定的时间,公开回购中的内容可能并不完全是我在机器上使用的内容。)
-
神经网络和深度学习是一本免费的在线书。本书会教会你: 神经网络,一种美妙的受生物学启发的编程范式,可以让计算机从观测数据中进行学习 深度学习,一个强有力的用于神经网络学习的众多技术的集合 神经网络和深度学习目前给出了在图像识别、语音识别和自然语言处理领域中很多问题的最好解决方案。本书将会教你在神经网络和深度学习背后的众多核心概念。 想了解本书选择的观点的更多细节,请看这里。或者直接跳到第一章 开始
-
人工神经网络指由大量的神经元互相连接而形成的复杂网络结构。以人的视觉系统为例,人的视觉系统的信息处理是分级的,高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表达语义或者意图。人工神经网络提出最初的目的是为了模拟生物神经网络传递和处理信息的功能。它按照一定规则将许多神经元连接在一起,并行的处理外接输入信息。人工神经网络的每一层都有若干神经元并用可变权重的有向弧连接,具体训练过程是通过多次迭代对已知信息的反复学习并调整改变神经元的连接权重。
-
神经网络 (Neural Network) 是机器学习的一个分支,全称人工神经网络(Artificial Neural Network,缩写 ANN),是一种模仿生物神经网络的结构和功能的数学模型或计算模型,用于对函数进行估计或近似。 Perceptron (感知器) 一个典型的神经网络由输入层、一个或多个隐藏层以及输出层组成,其中箭头代表着数据流动的方向,而圆圈代表激活函数(最常用的激活函数为
-
译者:bat67 最新版会在译者仓库首先同步。 可以使用torch.nn包来构建神经网络. 我们以及介绍了autograd,nn包依赖于autograd包来定义模型并对它们求导。一个nn.Module包含各个层和一个forward(input)方法,该方法返回output。 例如,下面这个神经网络可以对数字进行分类: 这是一个简单的前馈神经网络(feed-forward network)。它接受一