
神经网络异或门不学习

我试图用两个感知器网络做一个异或门,但由于某种原因,网络没有学习,当我在图中绘制误差的变化时,误差达到一个静态水平,并在该区域振荡。
目前我没有给网络添加任何偏见。
import numpy as np
def S(x):
return 1/(1+np.exp(-x))
win = np.random.randn(2,2)
wout = np.random.randn(2,1)
eta = 0.15
# win = [[1,1], [2,2]]
# wout = [[1],[2]]
obj = [[0,0],[1,0],[0,1],[1,1]]
target = [0,1,1,0]
epoch = int(10000)
emajor = ""
for r in range(0,epoch):
for xy in range(len(target)):
tar = target[xy]
fdata = obj[xy]
fdata = S(np.dot(1,fdata))
hnw = np.dot(fdata,win)
hnw = S(np.dot(fdata,win))
out = np.dot(hnw,wout)
out = S(out)
diff = tar-out
E = 0.5 * np.power(diff,2)
emajor += str(E[0]) + ",\n"
delta_out = (out-tar)*(out*(1-out))
nindelta_out = delta_out * eta
wout_change = np.dot(nindelta_out[0], hnw)
for x in range(len(wout_change)):
change = wout_change[x]
wout[x] -= change
delta_in = np.dot(hnw,(1-hnw)) * np.dot(delta_out[0], wout)
nindelta_in = eta * delta_in
for x in range(len(nindelta_in)):
midway = np.dot(nindelta_in[x][0], fdata)
for y in range(len(win)):
win[y][x] -= midway[y]
f = open('xor.csv','w')
f.write(emajor) # python will convert \n to os.linesep
f.close() # you can omit in most cases as the destructor will call it
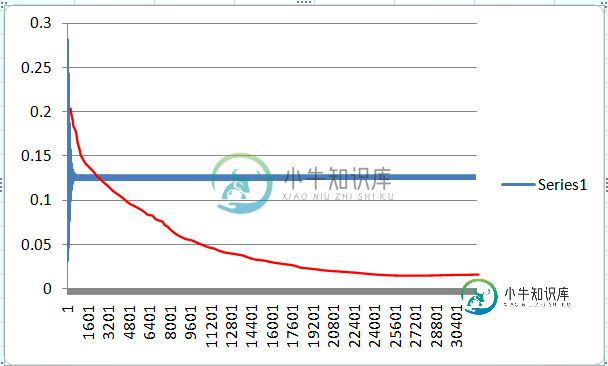
这是错误随着学习轮数的变化而变化。这是正确的吗?红色线是我所期望的错误将如何改变的线。
共有1个答案

这里是一个带有反向传播的隐藏层网络,它可以被定制来运行relu、sigmoid和其他激活的实验。实验结果表明,采用relu的网络性能较好,收敛较快,而采用sigmoid的网络损耗值波动较大。发生这种情况的原因是,“随着x的绝对值的增加,乙状结肠的梯度变得越来越小”。
import numpy as np
import matplotlib.pyplot as plt
from operator import xor
class neuralNetwork():
def __init__(self):
# Define hyperparameters
self.noOfInputLayers = 2
self.noOfOutputLayers = 1
self.noOfHiddenLayerNeurons = 2
# Define weights
self.W1 = np.random.rand(self.noOfInputLayers,self.noOfHiddenLayerNeurons)
self.W2 = np.random.rand(self.noOfHiddenLayerNeurons,self.noOfOutputLayers)
def relu(self,z):
return np.maximum(0,z)
def sigmoid(self,z):
return 1/(1+np.exp(-z))
def forward (self,X):
self.z2 = np.dot(X,self.W1)
self.a2 = self.relu(self.z2)
self.z3 = np.dot(self.a2,self.W2)
yHat = self.relu(self.z3)
return yHat
def costFunction(self, X, y):
#Compute cost for given X,y, use weights already stored in class.
self.yHat = self.forward(X)
J = 0.5*sum((y-self.yHat)**2)
return J
def costFunctionPrime(self,X,y):
# Compute derivative with respect to W1 and W2
delta3 = np.multiply(-(y-self.yHat),self.sigmoid(self.z3))
djw2 = np.dot(self.a2.T, delta3)
delta2 = np.dot(delta3,self.W2.T)*self.sigmoid(self.z2)
djw1 = np.dot(X.T,delta2)
return djw1,djw2
if __name__ == "__main__":
EPOCHS = 6000
SCALAR = 0.01
nn= neuralNetwork()
COST_LIST = []
inputs = [ np.array([[0,0]]), np.array([[0,1]]), np.array([[1,0]]), np.array([[1,1]])]
for epoch in xrange(1,EPOCHS):
cost = 0
for i in inputs:
X = i #inputs
y = xor(X[0][0],X[0][1])
cost += nn.costFunction(X,y)[0]
djw1,djw2 = nn.costFunctionPrime(X,y)
nn.W1 = nn.W1 - SCALAR*djw1
nn.W2 = nn.W2 - SCALAR*djw2
COST_LIST.append(cost)
plt.plot(np.arange(1,EPOCHS),COST_LIST)
plt.ylim(0,1)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title(str('Epochs: '+str(EPOCHS)+', Scalar: '+str(SCALAR)))
plt.show()
inputs = [ np.array([[0,0]]), np.array([[0,1]]), np.array([[1,0]]), np.array([[1,1]])]
print "X\ty\ty_hat"
for inp in inputs:
print (inp[0][0],inp[0][1]),"\t",xor(inp[0][0],inp[0][1]),"\t",round(nn.forward(inp)[0][0],4)
最终结果:
X y y_hat
(0, 0) 0 0.0
(0, 1) 1 0.9997
(1, 0) 1 0.9997
(1, 1) 0 0.0005
训练后获得的重量为:
nn.w1
[ [-0.81781753 0.71323677]
[ 0.48803631 -0.71286155] ]
nn.w2
[ [ 2.04849235]
[ 1.40170791] ]
我发现以下youtube系列对理解神经网络极为有用:神经网络demystified
-
我创建了一个神经网络,其结构如下: Input1-Input2-输入层。 N0-N1-隐藏层。每个节点3个权重(一个用于偏移)。 N2——输出层。3个砝码(一个用于偏置)。 我正在尝试使用以下测试数据对其进行XOR函数训练: 0 1-期望结果:1 1 0-期望结果:1 0 0-所需结果:0 1 1-所需结果:0 训练后,测试的均方误差(当寻找1结果时){0,1}=0,我认为这很好。但是测试的均方误
-
我已经实现了下面的神经网络来解决Python中的异或问题。我的神经网络由3个神经元的输入层、1个2个神经元的隐层和1个神经元的输出层组成。我使用Sigmoid函数作为隐藏层和输出层的激活函数: backpropogation似乎是正确的,但我一直得到这个错误,所有的值都变成了“nan”,输出: 你能帮我解决这个问题吗?谢谢你。
-
我正在建立一个分类神经网络,以便对两个不同的类进行分类。 所以这是一个二元分类问题,我正尝试用一个前馈神经网络来解决这个任务。 但是网络是不能学习的,事实上,在训练过程中,网络的精度是不变的。 具体而言,数据集由以下人员组成: 65673行22列。 其中一列是具有值(0,1)的目标类,而其他21列是预测器。数据集是这样平衡的: null 可以看到也有NaN值,但我不能删除它,因为在其他列中有值0是
-
我实现了以下神经网络来解决Python中的异或问题。我的神经网络由2个神经元的输入层、1个2个神经元的隐藏层和1个神经元的输出层组成。我使用Sigmoid函数作为隐藏层的激活函数,使用线性(恒等式)函数作为输出层的激活函数: 反向传播似乎都是正确的;我想到的唯一问题是我在实现偏差单位时遇到的一些问题。无论哪种方式,每次运行代码时,每个输入的所有谓词都会收敛到大约0.5。我仔细检查了代码,似乎找不到
-
神经网络和深度学习是一本免费的在线书。本书会教会你: 神经网络,一种美妙的受生物学启发的编程范式,可以让计算机从观测数据中进行学习 深度学习,一个强有力的用于神经网络学习的众多技术的集合 神经网络和深度学习目前给出了在图像识别、语音识别和自然语言处理领域中很多问题的最好解决方案。本书将会教你在神经网络和深度学习背后的众多核心概念。 想了解本书选择的观点的更多细节,请看这里。或者直接跳到第一章 开始
-
人工神经网络指由大量的神经元互相连接而形成的复杂网络结构。以人的视觉系统为例,人的视觉系统的信息处理是分级的,高层的特征是低层特征的组合,从低层到高层的特征表示越来越抽象,越来越能表达语义或者意图。人工神经网络提出最初的目的是为了模拟生物神经网络传递和处理信息的功能。它按照一定规则将许多神经元连接在一起,并行的处理外接输入信息。人工神经网络的每一层都有若干神经元并用可变权重的有向弧连接,具体训练过程是通过多次迭代对已知信息的反复学习并调整改变神经元的连接权重。