
对Pytorch神经网络初始化kaiming分布详解

函数的增益值
torch.nn.init.calculate_gain(nonlinearity, param=None)
提供了对非线性函数增益值的计算。
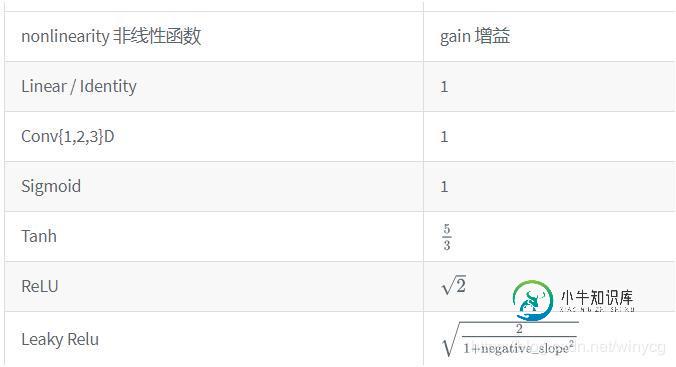
增益值gain是一个比例值,来调控输入数量级和输出数量级之间的关系。
fan_in和fan_out pytorch计算fan_in和fan_out的源码 def _calculate_fan_in_and_fan_out(tensor): dimensions = tensor.ndimension() if dimensions < 2: raise ValueError("Fan in and fan out can not be computed for tensor with fewer than 2 dimensions") if dimensions == 2: # Linear fan_in = tensor.size(1) fan_out = tensor.size(0) else: num_input_fmaps = tensor.size(1) num_output_fmaps = tensor.size(0) receptive_field_size = 1 if tensor.dim() > 2: receptive_field_size = tensor[0][0].numel() fan_in = num_input_fmaps * receptive_field_size fan_out = num_output_fmaps * receptive_field_size return fan_in, fan_out

xavier分布
xavier分布解析:https://prateekvjoshi.com/2016/03/29/understanding-xavier-initialization-in-deep-neural-networks/
假设使用的是sigmoid函数。当权重值(值指的是绝对值)过小,输入值每经过网络层,方差都会减少,每一层的加权和很小,在sigmoid函数0附件的区域相当于线性函数,失去了DNN的非线性性。
当权重的值过大,输入值经过每一层后方差会迅速上升,每层的输出值将会很大,此时每层的梯度将会趋近于0.
xavier初始化可以使得输入值x x x<math><semantics><mrow><mi>x</mi></mrow><annotation encoding="application/x-tex">x</annotation></semantics></math>x方差经过网络层后的输出值y y y<math><semantics><mrow><mi>y</mi></mrow><annotation encoding="application/x-tex">y</annotation></semantics></math>y方差不变。
(1)xavier的均匀分布
torch.nn.init.xavier_uniform_(tensor, gain=1)

也称为Glorot initialization。
>>> w = torch.empty(3, 5)
>>> nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain('relu'))
(2) xavier正态分布
torch.nn.init.xavier_normal_(tensor, gain=1)

也称为Glorot initialization。
kaiming分布
Xavier在tanh中表现的很好,但在Relu激活函数中表现的很差,所何凯明提出了针对于relu的初始化方法。pytorch默认使用kaiming正态分布初始化卷积层参数。
(1) kaiming均匀分布
torch.nn.init.kaiming_uniform_ (tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')

也被称为 He initialization。
a – the negative slope of the rectifier used after this layer (0 for ReLU by default).激活函数的负斜率,
mode – either ‘fan_in' (default) or ‘fan_out'. Choosing fan_in preserves the magnitude of the variance of the weights in the forward pass. Choosing fan_out preserves the magnitudes in the backwards
pass.默认为fan_in模式,fan_in可以保持前向传播的权重方差的数量级,fan_out可以保持反向传播的权重方差的数量级。
>>> w = torch.empty(3, 5) >>> nn.init.kaiming_uniform_(w, mode='fan_in', nonlinearity='relu')
(2) kaiming正态分布
torch.nn.init.kaiming_normal_ (tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')

也被称为 He initialization。
>>> w = torch.empty(3, 5) >>> nn.init.kaiming_normal_(w, mode='fan_out', nonlinearity='relu')
以上这篇对Pytorch神经网络初始化kaiming分布详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
深度神经网络具有独特的功能,可以帮助机器学习突破自然语言的过程。 据观察,这些模型中的大多数将语言视为单词或字符的平坦序列,并使用一种称为递归神经网络或RNN的模型。 许多研究人员得出的结论是,对于短语的分层树,语言最容易被理解。 此类型包含在考虑特定结构的递归神经网络中。 PyTorch有一个特定的功能,有助于使这些复杂的自然语言处理模型更容易。 它是一个功能齐全的框架,适用于各种深度学习,并为
-
递归神经网络是一种遵循顺序方法的深度学习导向算法。在神经网络中,我们总是假设每个输入和输出都独立于所有其他层。这些类型的神经网络被称为循环,因为它们以顺序方式执行数学计算,完成一个接一个的任务。 下图说明了循环神经网络的完整方法和工作 - 在上图中,,,和是包括一些隐藏输入值的输入,即输出的相应输出的,和。现在将专注于实现PyTorch,以在递归神经网络的帮助下创建正弦波。 在训练期间,将遵循模型
-
主要内容:卷积神经网络深度学习是机器学习的一个分支,它是近几十年来研究人员突破的关键步骤。深度学习实现的示例包括图像识别和语音识别等应用。 下面给出了两种重要的深度神经网络 - 卷积神经网络 递归神经网络。 在本章中,我们将关注第一种类型,即卷积神经网络(CNN)。 卷积神经网络 卷积神经网络旨在通过多层阵列处理数据。这种类型的神经网络用于图像识别或面部识别等应用。 CNN与任何其他普通神经网络之间的主要区别在于CNN
-
神经网络的主要原理包括一系列基本元素,即人工神经元或感知器。它包括几个基本输入,如:x1,x2 …… .. xn,如果总和大于激活潜在量,则产生二进制输出。 样本神经元的示意图如下所述 - 产生的输出可以认为是具有激活潜在量或偏差加权和。 典型的神经网络架构如下所述 - 输入和输出之间的层称为隐藏层,层之间的连接密度和类型是配置。例如,完全连接的配置使层L的所有神经元连接到的神经元。对于更明显的定
-
主要内容:神经网络工作流程,反向传播算法,总结通过《 人工神经网络是什么》一节,我们了解了神经网络的发展历程,同时掌握了人工神经网络的基本结构。在本节将主要围绕“反向传播算法”对人工神经网络的分类原理进行讲解。 在神经网络算法还没流行前,机器学习领域最受关注的算法是“支持向量机算法(即 SVM 算法)”,如今神经网络方兴未艾,您也许会好奇,神经网络各层的原理和结构都高度相似,为什么要堆叠这么多的神经网络层呢?就好比为什么单层感知器模型不能解决
-
本文向大家介绍对pytorch网络层结构的数组化详解,包括了对pytorch网络层结构的数组化详解的使用技巧和注意事项,需要的朋友参考一下 最近再写openpose,它的网络结构是多阶段的网络,所以写网络的时候很想用列表的方式,但是直接使用列表不能将网络中相应的部分放入到cuda中去。 其实这个问题很简单的,使用moduleList就好了。 1 我先是定义了一个函数,用来根据超参数,建立一个基础网