
互分解 Cross Decomposition
互分解 / 范例一:Compare cross decomposition methods
这个范例目的是比较几个互分解的方法。互分解运算主要是使用潜在变量模式(Latent variable modeling)分析来寻找两个矩阵之间的主要相关成份。
对比于外显变量(Manifest variable),也就是一般的观察变量(Observational variable),潜在变量是可能会影响实验观察的一个未知因素。
(一)引入函式库及内建手写数字资料库
引入之函式库如下
- matplotlib.pyplot: 用来绘制影像
- sklearn.cross_decomposition: 互分解物件
- PLSCanonical: Partial Least Squares 净最小平方法
- PLSRegression: PLS 净最小平方迴归法
- CCA: Canonical correlation analysis 典型相关分析
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.cross_decomposition import PLSCanonical, PLSRegression, CCA#首先产生500笔常态分布资料n = 500# 共有两个潜在变量:l1 = np.random.normal(size=n)l2 = np.random.normal(size=n)# np.array([l1, l1, l2, l2]).shape = (4L, 500L)# latents 为 500 x 4 之矩阵latents = np.array([l1, l1, l2, l2]).T#接下来加入乱数形成X, Y矩阵X = latents + np.random.normal(size=4 * n).reshape((n, 4))Y = latents + np.random.normal(size=4 * n).reshape((n, 4))X_train = X[:n / 2]Y_train = Y[:n / 2]X_test = X[n / 2:]Y_test = Y[n / 2:]# numpy.corrcoef(x, y=None) 用来记算 Pearson product-moment 相关係数print("Corr(X)")print(np.round(np.corrcoef(X.T), 2))print("Corr(Y)")print(np.round(np.corrcoef(Y.T), 2))
Corr(X)[[ 1. 0.48 0.02 0. ][ 0.48 1. 0.02 -0.02][ 0.02 0.02 1. 0.51][ 0. -0.02 0.51 1. ]]Corr(Y)[[ 1. 0.49 -0.01 0.05][ 0.49 1. -0.06 0.06][-0.01 -0.06 1. 0.53][ 0.05 0.06 0.53 1. ]]
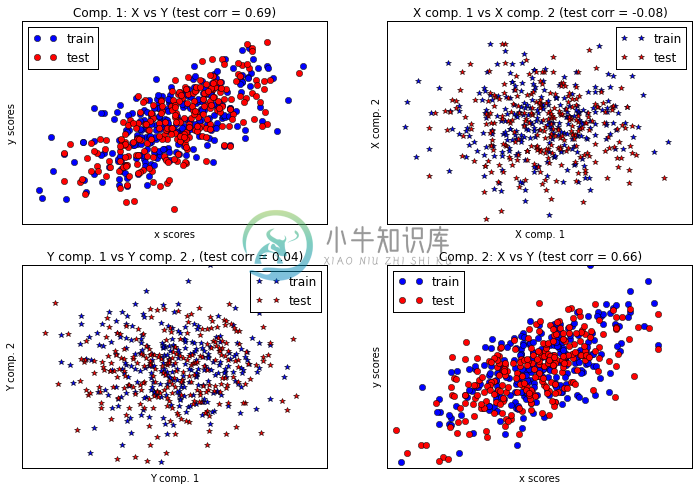
# Canonical (symmetric) PLS# Transform data# ~~~~~~~~~~~~~~plsca = PLSCanonical(n_components=2)plsca.fit(X_train, Y_train)X_train_r, Y_train_r = plsca.transform(X_train, Y_train)X_test_r, Y_test_r = plsca.transform(X_test, Y_test)# Scatter plot of scores# ~~~~~~~~~~~~~~~~~~~~~~# 1) On diagonal plot X vs Y scores on each components#figure = plt.figure(figsize=(30,20), dpi=300)plt.figure(figsize=(12, 8), dpi=600)plt.subplot(221)plt.plot(X_train_r[:, 0], Y_train_r[:, 0], "ob", label="train")plt.plot(X_test_r[:, 0], Y_test_r[:, 0], "or", label="test")plt.xlabel("x scores")plt.ylabel("y scores")plt.title('Comp. 1: X vs Y (test corr = %.2f)' %np.corrcoef(X_test_r[:, 0], Y_test_r[:, 0])[0, 1])plt.xticks(())plt.yticks(())plt.legend(loc="best")plt.subplot(224)plt.plot(X_train_r[:, 1], Y_train_r[:, 1], "ob", label="train")plt.plot(X_test_r[:, 1], Y_test_r[:, 1], "or", label="test")plt.xlabel("x scores")plt.ylabel("y scores")plt.title('Comp. 2: X vs Y (test corr = %.2f)' %np.corrcoef(X_test_r[:, 1], Y_test_r[:, 1])[0, 1])plt.xticks(())plt.yticks(())plt.legend(loc="best")# 2) Off diagonal plot components 1 vs 2 for X and Yplt.subplot(222)plt.plot(X_train_r[:, 0], X_train_r[:, 1], "*b", label="train")plt.plot(X_test_r[:, 0], X_test_r[:, 1], "*r", label="test")plt.xlabel("X comp. 1")plt.ylabel("X comp. 2")plt.title('X comp. 1 vs X comp. 2 (test corr = %.2f)'% np.corrcoef(X_test_r[:, 0], X_test_r[:, 1])[0, 1])plt.legend(loc="best")plt.xticks(())plt.yticks(())plt.subplot(223)plt.plot(Y_train_r[:, 0], Y_train_r[:, 1], "*b", label="train")plt.plot(Y_test_r[:, 0], Y_test_r[:, 1], "*r", label="test")plt.xlabel("Y comp. 1")plt.ylabel("Y comp. 2")plt.title('Y comp. 1 vs Y comp. 2 , (test corr = %.2f)'% np.corrcoef(Y_test_r[:, 0], Y_test_r[:, 1])[0, 1])plt.legend(loc="best")plt.xticks(())plt.yticks(())plt.show()
################################################################################ PLS regression, with multivariate response, a.k.a. PLS2n = 1000q = 3p = 10X = np.random.normal(size=n * p).reshape((n, p))B = np.array([[1, 2] + [0] * (p - 2)] * q).T# each Yj = 1*X1 + 2*X2 + noizeY = np.dot(X, B) + np.random.normal(size=n * q).reshape((n, q)) + 5pls2 = PLSRegression(n_components=3)pls2.fit(X, Y)print("True B (such that: Y = XB + Err)")print(B)# compare pls2.coef_ with Bprint("Estimated B")print(np.round(pls2.coef_, 1))pls2.predict(X)################################################################################ PLS regression, with univariate response, a.k.a. PLS1n = 1000p = 10X = np.random.normal(size=n * p).reshape((n, p))y = X[:, 0] + 2 * X[:, 1] + np.random.normal(size=n * 1) + 5pls1 = PLSRegression(n_components=3)pls1.fit(X, y)# note that the number of compements exceeds 1 (the dimension of y)print("Estimated betas")print(np.round(pls1.coef_, 1))################################################################################ CCA (PLS mode B with symmetric deflation)cca = CCA(n_components=2)cca.fit(X_train, Y_train)X_train_r, Y_train_r = plsca.transform(X_train, Y_train)X_test_r, Y_test_r = plsca.transform(X_test, Y_test)
True B (such that: Y = XB + Err)[[1 1 1][2 2 2][0 0 0][0 0 0][0 0 0][0 0 0][0 0 0][0 0 0][0 0 0][0 0 0]]Estimated B[[ 1. 1. 1. ][ 2. 1.9 2. ][ 0. 0. 0. ][ 0. 0. 0. ][ 0. 0. 0. ][ 0. 0. -0.1][ 0. 0. 0. ][ 0. 0. 0.1][ 0. 0. 0. ][ 0. 0. 0. ]]Estimated betas[[ 1. ][ 2. ][ 0. ][ 0. ][ 0. ][ 0. ][ 0. ][-0.1][ 0. ][ 0. ]]
(四)完整程式码
Python source code: plot_compare_cross_decomposition.py
http://scikit-learn.org/stable/_downloads/plot_compare_cross_decomposition.py
print(__doc__)import numpy as npimport matplotlib.pyplot as pltfrom sklearn.cross_decomposition import PLSCanonical, PLSRegression, CCA################################################################################ Dataset based latent variables modeln = 500# 2 latents vars:l1 = np.random.normal(size=n)l2 = np.random.normal(size=n)latents = np.array([l1, l1, l2, l2]).TX = latents + np.random.normal(size=4 * n).reshape((n, 4))Y = latents + np.random.normal(size=4 * n).reshape((n, 4))X_train = X[:n / 2]Y_train = Y[:n / 2]X_test = X[n / 2:]Y_test = Y[n / 2:]print("Corr(X)")print(np.round(np.corrcoef(X.T), 2))print("Corr(Y)")print(np.round(np.corrcoef(Y.T), 2))################################################################################ Canonical (symmetric) PLS# Transform data# ~~~~~~~~~~~~~~plsca = PLSCanonical(n_components=2)plsca.fit(X_train, Y_train)X_train_r, Y_train_r = plsca.transform(X_train, Y_train)X_test_r, Y_test_r = plsca.transform(X_test, Y_test)# Scatter plot of scores# ~~~~~~~~~~~~~~~~~~~~~~# 1) On diagonal plot X vs Y scores on each componentsplt.figure(figsize=(12, 8))plt.subplot(221)plt.plot(X_train_r[:, 0], Y_train_r[:, 0], "ob", label="train")plt.plot(X_test_r[:, 0], Y_test_r[:, 0], "or", label="test")plt.xlabel("x scores")plt.ylabel("y scores")plt.title('Comp. 1: X vs Y (test corr = %.2f)' %np.corrcoef(X_test_r[:, 0], Y_test_r[:, 0])[0, 1])plt.xticks(())plt.yticks(())plt.legend(loc="best")plt.subplot(224)plt.plot(X_train_r[:, 1], Y_train_r[:, 1], "ob", label="train")plt.plot(X_test_r[:, 1], Y_test_r[:, 1], "or", label="test")plt.xlabel("x scores")plt.ylabel("y scores")plt.title('Comp. 2: X vs Y (test corr = %.2f)' %np.corrcoef(X_test_r[:, 1], Y_test_r[:, 1])[0, 1])plt.xticks(())plt.yticks(())plt.legend(loc="best")# 2) Off diagonal plot components 1 vs 2 for X and Yplt.subplot(222)plt.plot(X_train_r[:, 0], X_train_r[:, 1], "*b", label="train")plt.plot(X_test_r[:, 0], X_test_r[:, 1], "*r", label="test")plt.xlabel("X comp. 1")plt.ylabel("X comp. 2")plt.title('X comp. 1 vs X comp. 2 (test corr = %.2f)'% np.corrcoef(X_test_r[:, 0], X_test_r[:, 1])[0, 1])plt.legend(loc="best")plt.xticks(())plt.yticks(())plt.subplot(223)plt.plot(Y_train_r[:, 0], Y_train_r[:, 1], "*b", label="train")plt.plot(Y_test_r[:, 0], Y_test_r[:, 1], "*r", label="test")plt.xlabel("Y comp. 1")plt.ylabel("Y comp. 2")plt.title('Y comp. 1 vs Y comp. 2 , (test corr = %.2f)'% np.corrcoef(Y_test_r[:, 0], Y_test_r[:, 1])[0, 1])plt.legend(loc="best")plt.xticks(())plt.yticks(())plt.show()################################################################################ PLS regression, with multivariate response, a.k.a. PLS2n = 1000q = 3p = 10X = np.random.normal(size=n * p).reshape((n, p))B = np.array([[1, 2] + [0] * (p - 2)] * q).T# each Yj = 1*X1 + 2*X2 + noizeY = np.dot(X, B) + np.random.normal(size=n * q).reshape((n, q)) + 5pls2 = PLSRegression(n_components=3)pls2.fit(X, Y)print("True B (such that: Y = XB + Err)")print(B)# compare pls2.coef_ with Bprint("Estimated B")print(np.round(pls2.coef_, 1))pls2.predict(X)################################################################################ PLS regression, with univariate response, a.k.a. PLS1n = 1000p = 10X = np.random.normal(size=n * p).reshape((n, p))y = X[:, 0] + 2 * X[:, 1] + np.random.normal(size=n * 1) + 5pls1 = PLSRegression(n_components=3)pls1.fit(X, y)# note that the number of compements exceeds 1 (the dimension of y)print("Estimated betas")print(np.round(pls1.coef_, 1))################################################################################ CCA (PLS mode B with symmetric deflation)cca = CCA(n_components=2)cca.fit(X_train, Y_train)X_train_r, Y_train_r = plsca.transform(X_train, Y_train)X_test_r, Y_test_r = plsca.transform(X_test, Y_test)