
类神经网路 Neural_Networks
+
+MathJax.Hub.Queue([“Typeset”,MathJax.Hub]);
+
Multi-layer Perceptron(多层感知器)
http://scikit-learn.org/stable/modules/neural_networks_supervised.html
Multi-layer Perceptron (MLP):MLP为一种监督式学习的演算法,藉由 f(·):R^m→R^o ,m是输入时的维度、o是输出时的维度,藉由输入特征 X=x_1,x_2,…..,x_m 和目标值Y,此算法将可以使用非线性近似将资料分类或进行迴归运算。MLP可以在输入层与输出层中间插入许多非线性层,如图1所示:,这是有一层隐藏层的网路。
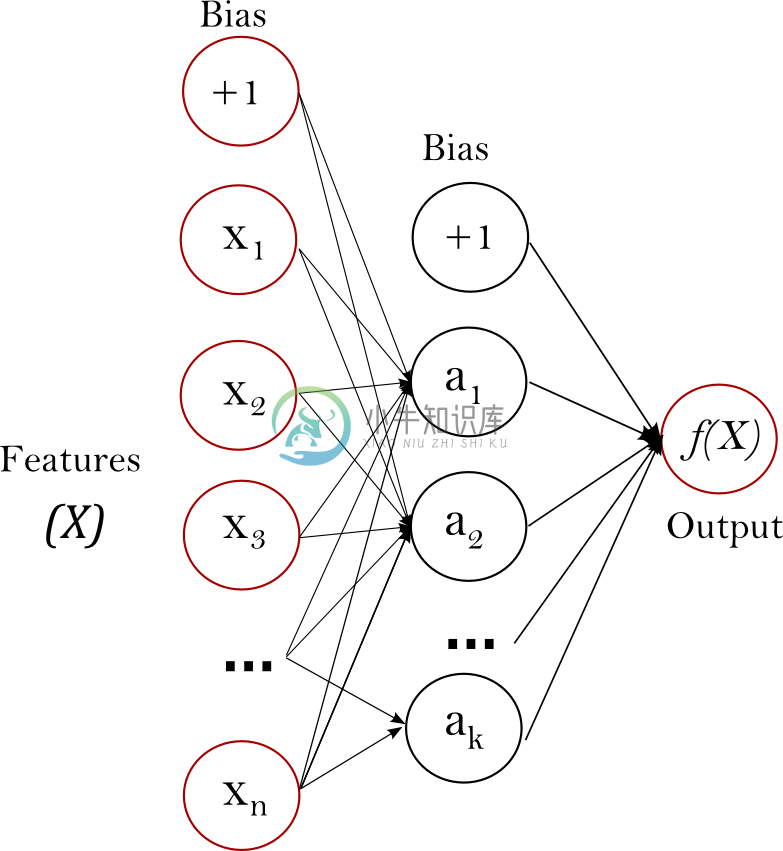
最左边那层称作输入层,为一个神经元集合 {x_i|x_1,x_2,…,x_m}代表输入的特征。每个神经元在隐藏层会根据前一层的输出的结果,做为此层的输入w_1x_1+w_2x_2+…+w_mx_m在将总和使用非线性的活化函数做 f(·):R→R转换,例如:hyperbolic tan function、Sigmoid function,最右边那层为输出层,会接收最后的隐藏层的输出在转换一次成输出值。
intercepts为模型训练后,权重矩阵内包含两个属性:$coefs\$和$intercepts_$。coefs_ 此矩阵中第i个指标表示第$i$层与$i+1$层的权重,intercepts_为偏权值(bias)矩阵,此矩阵中第i个指标表示要加在$i+1层$的偏权值。
MLP优点:
1.有能力建立非线性的模型
2.可以使用$partial_fit$建立real-time模型
MLP缺点:
1.因为凹函数拥有大于一个区域最小值,使用不同的初始权重,会让验证时的准确率浮动
2.MLP模型需要调整每层神经元数、层数、叠代次数
3.MLP对于特征的预先处理很敏感,建议将特征X都尺度降至[0,1]或[-1,+1]或让特征值降至平均值等于0与变异数等于1的数字区间
MLP分类器
使用MLP训练需要使用输入两种阵列,一个是特征X阵列,X阵列包含(样本数,特征数),另一个是Y向量包含目标值(分类标签)下面将会介绍MLP分类器范例。
(一)引入函式库
from sklearn.neural_network import MLPClassifier:引进MLP分类器
(二)建立模拟资料与设定分类器参数
建立拥有三种特征的三笔资料
X = [[0., 0.,0.], [1., 1.,1.],[2., 2.,2.]]
将三笔资料的分类标上
y = [0, 1, 2]
设定分类器:最佳化参数的演算法,alpha值,隐藏层的层数与每层神经元数: hidden_layer_sizes=(5,3)表示隐藏层有两层第一层为五个神经元,第二层为三个神经元
clf = MLPClassifier(solver=’lbfgs’, alpha=1e-5,
hidden_layer_sizes=(5,3), random_state=1)
(三)训练网路参数与预测
将资料丢进分类器,训练网路参数
clf.fit(X, y)
将要预测的资料丢进网路预测
clf.predict([[2., 2., 2.], [-1., -2.,0.],[1., 1.,0.]])
预测结果:array([2, 0, 1])
结果表示[2., 2., 2.]为第三类,[-1., -2.,0.]为第一类,[1., 1.,0.]为第二类
完整程式码:
from sklearn.neural_network import MLPClassifier
X = [[0., 0.,0.], [1., 1.,1.],[2., 2.,2.]]
y = [0, 1, 2]
clf = MLPClassifier(solver='lbfgs', alpha=1e-5,
hidden_layer_sizes=(5,3), random_state=1)
clf.fit(X, y)
clf.predict([[2., 2., 2.], [-1., -2.,0.],[1., 1.,0.]])