
通用范例 General Examples - Ex 1: Plotting Cross-Validated Predictions
通用范例/范例一: Plotting Cross-Validated Predictions
http://scikit-learn.org/stable/auto_examples/plot_cv_predict.html
- 资料集:波士顿房产
- 特征:房地产客观数据,如年份、平面大小
- 预测目标:房地产价格
- 机器学习方法:线性迴归
- 探讨重点:10 等分的交叉验証(10-fold Cross-Validation)来实际测试资料以及预测值的关係
- 关键函式:
sklearn.cross_validation.cross_val_predict
(一)引入函式库及内建测试资料库
引入之函式库如下
matplotlib.pyplot: 用来绘制影像sklearn.datasets: 用来绘入内建测试资料库sklearn.cross_validation import cross_val_predict:利用交叉验证的方式来预测sklearn.linear_model:使用线性迴归
(二)引入内建测试资料库(boston房产资料)
使用 datasets.load_boston() 将资料存入, boston 为一个dict型别资料,我们看一下资料的内容。
lr = linear_model.LinearRegression()#lr = LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)boston = datasets.load_boston()y = boston.target
| 显示 | 说明 |
|---|---|
| (‘data’, (506, 13)) | 房地产的资料集,共506笔房产13个特征 |
| (‘feature_names’, (13,)) | 房地产的特征名 |
| (‘target’, (506,)) | 回归目标 |
| DESCR | 资料之描述 |
(三)cross_val_predict的使用
sklearn.cross_validation.cross_val_predict(estimator, X, y=None, cv=None, n_jobs=1, verbose=0, fit_params=None, pre_dispatch=’2*n_jobs’)
X为机器学习数据,
y为回归目标,
cv为交叉验証时资料切分的依据,范例为10则将资料切分为10等分,以其中9等分为训练集,另外一等分则为测试集。
predicted = cross_val_predict(lr, boston.data, y, cv=10)
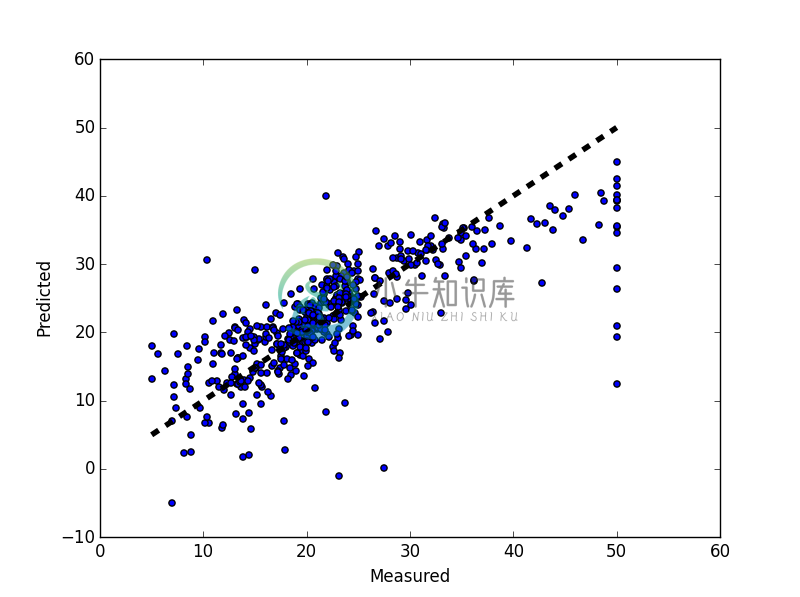
(四)绘出预测结果与实际目标差异图
X轴为回归目标,Y轴为预测结果。
并划出一条斜率=1的理想曲线(用虚线标示)
fig, ax = plt.subplots()ax.scatter(y, predicted)ax.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=4)ax.set_xlabel('Measured')ax.set_ylabel('Predicted')plt.show()
(五)完整程式码
Python source code: plot_cv_predict.py
http://scikit-learn.org/stable/auto_examples/plot_cv_predict.html
from sklearn import datasetsfrom sklearn.cross_validation import cross_val_predictfrom sklearn import linear_modelimport matplotlib.pyplot as pltlr = linear_model.LinearRegression()boston = datasets.load_boston()y = boston.target# cross_val_predict returns an array of the same size as `y` where each entry# is a prediction obtained by cross validated:predicted = cross_val_predict(lr, boston.data, y, cv=10)fig, ax = plt.subplots()ax.scatter(y, predicted)ax.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=4)ax.set_xlabel('Measured')ax.set_ylabel('Predicted')plt.show()