
Python机器学习之scikit-learn库中KNN算法的封装与使用方法

本文实例讲述了Python机器学习之scikit-learn库中KNN算法的封装与使用方法。分享给大家供大家参考,具体如下:
1、工具准备,python环境,pycharm
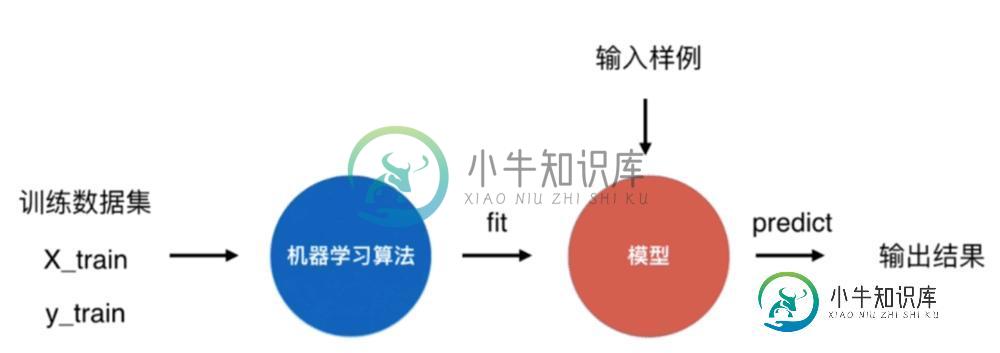
2、在机器学习中,KNN是不需要训练过程的算法,也就是说,输入样例可以直接调用predict预测结果,训练数据集就是模型。当然这里必须将训练数据和训练标签进行拟合才能形成模型。
3、在pycharm中创建新的项目工程,并在项目下新建KNN.py文件。
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
def __init__(self,k):
"""初始化KNN分类器"""
assert k >= 1
"""断言判断k的值是否合法"""
self.k = k
self._X_train = None
self._y_train = None
def fit(self,X_train,y_train):
"""根据训练数据集X_train和Y_train训练KNN分类器,形成模型"""
assert X_train.shape[0] == y_train.shape[0]
"""数据和标签的大小必须一样
assert self.k <= X_train.shape[0]
"""k的值不能超过数据的大小"""
self._X_train = X_train
self._y_train = y_train
return self
def predict(self,X_predict):
"""必须将训练数据集和标签拟合为模型才能进行预测的过程"""
assert self._X_train is not None and self._y_train is not None
"""训练数据和标签不可以是空的"""
assert X_predict.shape[1]== self._X_train.shape[1]
"""待预测数据和训练数据的列(特征个数)必须相同"""
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self,x):
"""给定单个待测数据x,返回x的预测数据结果"""
assert x.shape[0] == self._X_train.shape[1]
"""x表示一行数据,即一个数组,那么它的特征数据个数,必须和训练数据相同
distances = [sqrt(np.sum((x_train - x)**2))for x_train in self._X_train]
nearest = np.argsort(distances)
topk_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topk_y)
return votes.most_common(1)[0][0]
4、新建test.py文件,引入KNNClassifier对象。
from KNN.py import KNNClassifier
raw_data_x = [[3.393,2.331],
[3.110,1.781],
[1.343,3.368],
[3.582,4.679],
[2.280,2.866],
[7.423,4.696],
[5.745,3.533],
[9.172,2.511],
[7.792,3.424],
[7.939,0.791]]
raw_data_y = [0,0,0,0,0,1,1,1,1,1]
X_train = np.array(raw_data_x)
y_train = np.array(raw_data_y)
x = np.array([9.880,3.555])
# 要将x这个矩阵转换成2维的矩阵,一行两列的矩阵
X_predict = x.reshape(1,-1)
"""1,创建一个对象,设置K的值为6"""
knn_clf = KNNClassifier(6)
"""2,将训练数据和训练标签融合"""
knn_clf.fit(X_train,y_train)
"""3,经过2才能跳到这里,传入待预测的数据"""
y_predict = knn_clf.predict(X_predict)
print(y_predict)
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数学运算技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。
-
Scikit-learn 套件的安装 目前Scikit-learn同时支持Python 2及 3,安装的方式也非常多种。对于初学者,最建议的方式是直接下载 Anaconda Python (https://www.continuum.io/downloads)。同时支持 Windows / OSX/ Linux 等作业系统。相关数据分析套件如Scipy, Numpy, 及图形绘制库 matplot
-
校验者: @小瑶 翻译者: @李昊伟 校验者: @hlxstc @BWM-蜜蜂 @小瑶 翻译者: @... 内容提要 在本节中,我们介绍一些在使用 scikit-learn 过程中用到的 机器学习 词汇,并且给出一些例子阐释它们。 机器学习:问题设置 一般来说,一个学习问题通常会考虑一系列 n 个 样本 数据,然后尝试预测未知数据的属性。 如果每个样本是 多个属性的数据 (比如说是一个多维记录),
-
本文向大家介绍机器学习之KNN算法原理及Python实现方法详解,包括了机器学习之KNN算法原理及Python实现方法详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了机器学习之KNN算法原理及Python实现方法。分享给大家供大家参考,具体如下: 文中代码出自《机器学习实战》CH02,可参考本站: 机器学习实战 (Peter Harrington著) 中文版 机器学习实战 (Peter
-
本文向大家介绍基于Python和Scikit-Learn的机器学习探索,包括了基于Python和Scikit-Learn的机器学习探索的使用技巧和注意事项,需要的朋友参考一下 你好,%用户名%! 我叫Alex,我在机器学习和网络图分析(主要是理论)有所涉猎。我同时在为一家俄罗斯移动运营商开发大数据产品。这是我第一次在网上写文章,不喜勿喷。 现在,很多人想开发高效的算法以及参加机器学习的竞赛。所以他
-
从sklearn加载流行数字数据集。数据集模块,并将其分配给可变数字。 分割数字。将数据分为两组,分别命名为X_train和X_test。还有,分割数字。目标分为两组Y_训练和Y_测试。 提示:使用sklearn中的训练测试分割方法。模型选择;将随机_状态设置为30;并进行分层抽样。使用默认参数,从X_序列集和Y_序列标签构建SVM分类器。将模型命名为svm_clf。 在测试数据集上评估模型的准确
-
随着 AlphaGo 在人机大战中一举成名,关于机器学习的研究开始广受关注,数据科学家也一跃成为 21世纪最性感的职业。关于机器学习和神经网络的广泛应用虽然兴起不久,但是对这两个密切关联的领域的研究其实已经持续了好几十年,早已形成了系统化的知识体系。对于想要踏入机器学习领域的初学者而言,理论知识的获取并非难事。