
2.1 人造神经元——早期机器学习概览
在详细讨论感知器和相关算法之前,先大体了解一下早期机器学习的起源。为了理解大脑的工作原理以设计人工智能系统,沃伦·麦卡洛可(Warren McCullock)与沃尔特·皮茨(Walter Pitts)在1943年提出了第一个脑神经元的抽象模型,也称作麦卡洛可-皮茨神经元(McCullock-Pitts neuron,MCP)[1],神经元是大脑中相互连接的神经细胞,它可以处理和传递化学和电信号,如下图所示:

麦卡洛可和皮茨将神经细胞描述为一个具备二进制输出的逻辑门。树突接收多个输入信号,如果累加的信号超过某一阈值,经细胞体的整合就会生成一个输出信号,并通过轴突进行传递。
几年后,弗兰克·罗森布拉特(Frank Rossenblatt)基于MCP神经元模型提出了第一个感知器学习法则[2]。在此感知器规则中,罗森布拉特提出了一个自学习算法,此算法可以自动通过优化得到权重系数,此系数与输入值的乘积决定了神经元是否被激活。在监督学习与分类中,类似算法可用于预测样本所属的类别。
更严谨地讲,我们把这个问题看作一个二值分类的任务,为了简单起见,我们把两类分别记为1(正类别)和-1(负类别)。我们可以定义一个激励函数(activation function)φ(z),它以特定的输入值x与相应的权值向量w的线性组合作为输入,其中,z也称作净输入(z=w1x1+…+wmxm):

此时,对于一个特定样本x(i)的激励,也就是φ(z)的输出,如果其值大于预设的阈值θ,我们将其划分到1类,否则为-1类。在感知器算法中,激励函数φ(·)是一个简单的分段函数。

 注意:在下面的小节中,借用了线性代数的部分符号。例如,使用向量点积(vector dot product)来表示x和w乘积的和,而上标T则表示转置,它使得行向量和列向量之间能够相互转换:
注意:在下面的小节中,借用了线性代数的部分符号。例如,使用向量点积(vector dot product)来表示x和w乘积的和,而上标T则表示转置,它使得行向量和列向量之间能够相互转换:

此外,转置操作也可以通过其主对角线应用到矩阵上,例如:

在本书中,我们仅使用了线性代数中最基本的符号。不过,如果读者想要快速复习一下相关内容,请参考Zico Kolter的线性代数可通过如下链接免费获取:http://www.cs.cmu.edu/~zkolter/course/linalg/linalg_notes.pdf。
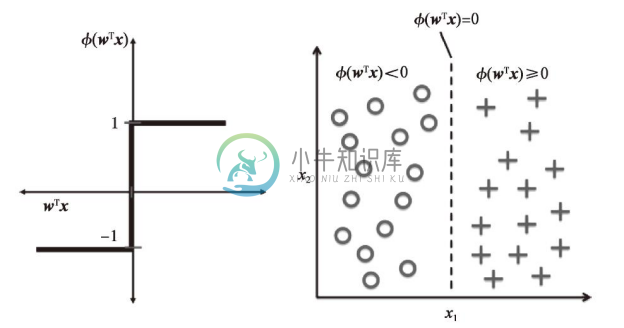
下图中,左图说明了感知器模型的激励函数如何将输入z=wTx转换到二值输出(-1或1),右图说明了感知器模型如何将两个可区分类别进行线性区分。
MCP神经元和罗森布拉特阈值感知器的理念就是,通过模拟的方式还原大脑中单个神经元的工作方式:它是否被激活。这样,罗森布拉特感知器最初的规则非常简单,可总结为如下几步:
1)将权重初始化为零或一个极小的随机数。
2)迭代所有训练样本x(i),执行如下操作:
(1)计算输出值![]() 。
。
(2)更新权重。
这里的输出值是指通过前面定义的单位阶跃函数预测得出的类标,而每次对权重向量中每一权重w的更新方式为:
![]()
对于用于更新权重wj的值Δwj,可通过感知器学习规则计算获得:
![]()
其中,η为学习速率(一个介于0.0到1.0之间的常数),y(i)为第i个样本的真实类标,![]() 为预测得到的类标。需特别注意,权重向量中的所有权重值是同时更新的,这意味着在所有的权重Δwj更新前,我们无法重新计算
为预测得到的类标。需特别注意,权重向量中的所有权重值是同时更新的,这意味着在所有的权重Δwj更新前,我们无法重新计算![]() 。具体地,对于一个二维数据集,可通过下式进行更新:
。具体地,对于一个二维数据集,可通过下式进行更新:

在使用Python语言实现感知器之前,让我们通过一个简单的推导实验来体验一下这个学习规则的简洁之美。对于如下式所示的两种场景,若感知器对类标的预测正确,权重可不做更新:

但是,在类标预测错误的情况下,权重的值会分别趋向于正类别或者负类别的方向:

为了对乘法因子![]() 有个更直观的认识,我们看另一个简单的例子,其中:
有个更直观的认识,我们看另一个简单的例子,其中:
![]()
假定![]() ,且模型将此样本错误地分到了-1类别内。在此情况下,我们应将相应的权值增1,以保证下次遇到此样本时使得激励
,且模型将此样本错误地分到了-1类别内。在此情况下,我们应将相应的权值增1,以保证下次遇到此样本时使得激励![]() 能将其更多地判定为正类别,这也相当于增大其值大于单位阶跃函数阈值的概率,以使得此样本被判定为+1类。
能将其更多地判定为正类别,这也相当于增大其值大于单位阶跃函数阈值的概率,以使得此样本被判定为+1类。
![]()
权重的更新与![]() 的值成比例。例如,如果有另外一个样本
的值成比例。例如,如果有另外一个样本![]() 被错误分到了-1类别中,我们应更大幅度地移动决策边界,以保证下次遇到此样本时能正确分类。
被错误分到了-1类别中,我们应更大幅度地移动决策边界,以保证下次遇到此样本时能正确分类。
![]()
需要注意的是:感知器收敛的前提是两个类别必须是线性可分的,且学习速率足够小。如果两个类别无法通过一个线性决策边界进行划分,可以为模型在训练数据集上的学习迭代次数设置一个最大值,或者设置一个允许错误分类样本数量的阈值——否则,感知器训练算法将永远不停地更新权值。

在学习下一小节中感知器的实现方法之前,我们先通过一个简单的示例图片总结一下刚刚学到的感知器的基本概念:

上图说明了感知器如何接收样本x的输入,并将其与权值w进行加权以计算净输入(net input)。进而净输入被传递到激励函数(在此为单位阶跃函数),然后生成值为+1或者-1的二值输出,并以其作为样本的预测类标。在学习阶段,此输出用来计算预测的误差并更新权重。
[1] W.S.McCulloch and W.Pitts.A Logical Calculus of the Ideas Immanent in Nervous Activity.The bulletin of mathematical biophysics,5(4):115–133,1943.
[2] F.Rosenblatt,The Perceptron,a Perceiving and Recognizing Automaton.Cornell Aeronautical Laboratory,1957.