6.1 基于流水线的工作流
我们在前面章节中学习了不同的数据预处理技术,无论是第4章中介绍的用于特征缩放的标准化方法,还是第5章中介绍的用于数据压缩的主成分分析等,我们在使用训练数据对模型进行拟合时就得到了一些参数,但将模型用于新数据时需重设这些参数。本节读者将学到一个方便使用的工具:scikit-learn中的Pipline类。它使得我们可以拟合出包含任意多个处理步骤的模型,并将模型用于新数据的预测。
6.1.1 加载威斯康星乳腺癌数据集
本章我们将使用威斯康星乳腺癌(Breast Cancer Wisconsin)数据集进行讲解,此数据集共包含569个恶性或者良性肿瘤细胞样本。数据集的前两列分别存储了样本唯一的ID以及对样本的诊断结果(M代表恶性,B代表良性)。数据集的3~32列包含了30个从细胞核照片中提取、用实数值标识的特征,它们可以用于构建判定模型,对肿瘤是良性还是恶性做出预测。威斯康星乳腺癌数据集已经存储在UCI机器学习数据集库中,关于此数据集更多的信息请访问链接:https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Diagnostic)。
在本节,我们通过三个步骤来读取数据集,并将其划分为训练数据集和测试数据集。
1)使用pandas从UCI网站直接读取数据集:

2)接下来,将数据集的30个特征的赋值给一个NumPy的数组对象X。使用scikit-learn中的LabelEncoder类,我们可以将类标从原始的字符串表示(M或者B)转换为整数:

转换后的类标(诊断结果)存储在一个数组y中,此时恶性肿瘤和良性肿瘤分别被标识为类1和类0,我们可以通过调用LabelEncoder的transform方法来显示虚拟类标(0和1):
![]()
3)在构建第一个流水线模型前,先将数据集划分为训练数据集(原始数据集80%的数据)和一个单独的测试数据集(原始数据集20%的数据):

6.1.2 在流水线中集成数据转换及评估操作
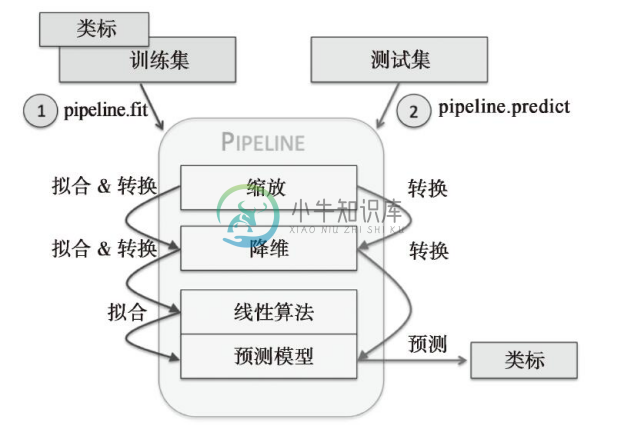
通过前面章节的学习,我们了解到:出于性能优化的目的,许多学习算法要求将不同特征的值缩放到相同的范围。这样,我们在使用逻辑斯谛回归模型等线性分类器分析威斯康星乳腺癌数据集之前,需要对其特征列做标准化处理。此外,我们还想通过第5章中介绍过的主成分分析(PCA)——使用特征抽取进行降维的技术,将最初的30维数据压缩到一个二维的子空间上。我们无需在训练数据集和测试数据集上分别进行模型拟合、数据转换,而是通过流水线将StandardScaler、PCA,以及LogisticRegression对象串联起来:

Pipeline对象采用元组的序列作为输入,其中每个元组中的第一个值为一个字符串,它可以是任意的标识符,我们通过它来访问流水线中的元素,而元组的第二个值则为scikit-learn中的一个转换器或者评估器。
流水线中包含了scikit-learn中用于数据预处理的类,最后还包括一个评估器。在前面的示例代码中,流水线中有两个预处理环节,分别是用于数据缩放和转换的StandardScaler及PCA,最后还有一个作为评估器的逻辑斯谛回归分类器。当在流水线pipe_lr上执行fit方法时,StandardScaler会在训练数据上执行fit和transform操作,经过转换后的训练数据将传递给流水线上的下一个对象——PCA。与前面的步骤类似,PCA会在前一步转换后的输入数据上执行fit和transform操作,并将处理过的数据传递给流水线中的最后一个对象——评估器。我们应该注意到:流水线中没有限定中间步骤的数量。流水线的工作方式可用下图来描述: