
用Python SDK在流数据流流水线中不工作的Apache Beam侧输入

我正在处理一个更大的数据流管道,它在批处理模式下工作得很好,但完成后的重构确实有侧输入的问题。如果我将管道置于流模式并移除侧输入,管道在Google的数据流上可以完美地工作。
如果把所有东西都剥离下来,构建以下简短的脚本来封装这个问题,并能够与它一起玩。
import apache_beam as beam
import os
import json
import sys
import logging
""" Here the switches """
run_local = False
streaming = False
project = 'google-project-name'
bucket = 'dataflow_bucket'
tmp_location = 'gs://{}/{}/'.format(bucket, "tmp")
topic = "projects/{}/topics/dataflowtopic".format(project)
credentials_file = os.path.join(os.path.dirname(__file__), "credentials.json")
if os.path.exists(credentials_file):
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credentials_file
if not run_local:
runner = "DataflowRunner"
else:
runner = "DirectRunner"
argv = [
'--region={0}'.format("europe-west6"),
'--project={0}'.format(project),
'--temp_location={0}'.format(tmp_location),
'--runner={0}'.format(runner),
'--save_main_session',
'--max_num_workers=2'
]
if streaming:
argv.append('--streaming')
def filter_existing(item, existing=None, id_field: str = 'id'):
sys.stdout.write(".")
if not item.get(id_field) in existing:
return True
return False
class UserProcessor(beam.DoFn):
def process(self, user, **kwargs):
if run_local:
print("processing an user and getting items for it")
else:
logging.info("processing an user and getting items for it")
for i in range(10):
yield {"id": i, "item_name": "dingdong", "user": user}
class ExistingProcessor(beam.DoFn):
def process(self, user, **kwargs):
if run_local:
print("creating the list to exclude items from the result")
else:
logging.info("creating the list to exclude items from the result")
yield {"id": 3}
yield {"id": 5}
yield {"id": 9}
with beam.Pipeline(argv=argv) as p:
if streaming:
if run_local:
print("Waiting for Pub/Sub Message on Topic: {}".format(topic))
else:
logging.info("Waiting for Pub/Sub Message on Topic: {}".format(topic))
users = p | "Loading user" >> beam.io.ReadFromPubSub(topic=topic) | beam.Map(lambda x: json.loads(x.decode()))
else:
if run_local:
print("Loading Demo User")
else:
logging.info("Loading Demo User")
example_user = {"id": "indi","name": "Indiana Jones"}
users = p | "Loading user" >> beam.Create([example_user])
process1 = users | "load all items for user" >> beam.ParDo(UserProcessor().with_input_types(dict))
process2 = users | "load existing items for user" >> beam.ParDo(ExistingProcessor().with_input_types(dict)) | beam.Map(lambda x: x.get('id'))
if run_local:
process1 | "debug process1" >> beam.Map(print)
process2 | "debug process2" >> beam.Map(print)
#filtered = (process1, process2) | beam.Flatten() # this works
filtered = process1 | "filter all against existing items" >> beam.Filter(filter_existing, existing=beam.pvalue.AsList(process2)) # this does NOT work when streaming, it does in batch
if run_local:
filtered | "debug filtered" >> beam.Map(print)
filtered | "write down result" >> beam.io.WriteToText(os.path.join(os.path.dirname(__file__), "test_result.txt"))
else:
filtered | "write down result" >> beam.io.WriteToText("gs://{}/playground/output.txt".format(bucket))
if run_local:
print("pipeline initialized!")
else:
logging.info("pipeline initialized!")
在Google的Dataflow中以批处理作业的形式运行这个脚本可以完成它需要做的事情。请参阅从数据流中可视化的管道:
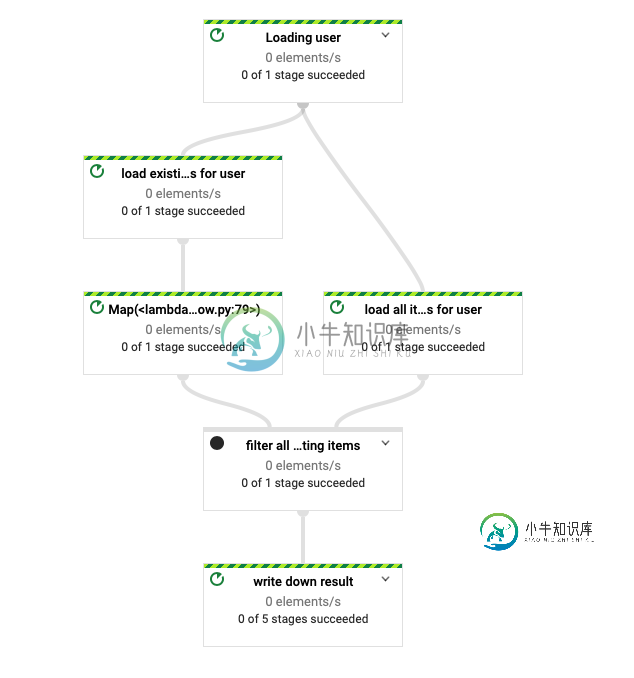
# this works in streaming AND batch mode
# filtered = (process1, process2) | beam.Flatten() # this works
# this does NOT work in streaming mode, but DOES works in batch mode
filtered = process1 | "filter all against existing items" >> beam.Filter(filter_existing, existing=beam.pvalue.AsList(process2))
共有1个答案

你是正确的,问题是侧输入没有窗口化。当您使用侧输入运行并行Do(Map、FlatMap、Filter,...)时,运行器会等待侧输入“完全计算”,然后才运行主输入。在这种情况下,它是从没有窗口的PubSub源读取的,这意味着它永远不会“完成”(也就是说,将来可能会有更多的数据出现)。
要使其工作,您需要窗口两侧,这样侧边输入将变成“完成到时间X”,然后过滤器可以运行“到时间X”,因为X从窗口边界向前跳到窗口边界。
-
我已经用Python SDK(Apache Beam Python 3.7 SDK 2.19.0)构建了一个窗口流数据流管道。初始数据的表示如下: 其思想是找出给定窗口中每行号码的平均通话长度。数据作为CSV的行从pub/sub中读取,我向所有行添加一个与该数字的平均调用长度相对应的值: 我使用以下管道: 有什么想法吗?
-
我试图从一个数据流作业中运行两个分离的管道,类似于下面的问题: 一个数据流作业中的并行管道 如果我们使用单个p.run()使用单个数据流作业运行两个分离的管道,如下所示: 我认为它将在一个数据流作业中启动两个独立的管道,但它会创建两个包吗?它会在两个不同的工人上运行吗?
-
请注意:问题是基于旧的,现在称为“脚本”管道格式。当使用“声明性管道”时,并行块可以嵌套在阶段块内(请参见使用声明性管道的并行阶段1.2)。 我想知道并行步骤应该如何使用Jenkins工作流/管道插件,特别是。如何将它们与构建阶段混合。我知道一般的模式: 我可以并行地构建不同的阶段吗?或者“并行”步骤只意味着在单个阶段中使用?
-
问题内容: 我是管道功能概念的新手。我有一些关于 从数据库的角度来看: 管道功能到底是什么? 使用管道功能的好处是什么? 使用管道功能解决了哪些挑战? 使用管道功能有什么优化优势? 谢谢。 问题答案: 引用“问汤姆·甲骨文”: 流水线函数只是“您可以假装为数据库表的代码” 流水线函数使您(让我惊讶) 在您认为可以使用它的任何时候-从函数而不是表中选择*可能是“有用的”。 就优点而言:使用Pipel
-
这与这个问题最为相似。 我正在Dataflow 2.x中创建一个管道,它从Pubsub队列获取流式输入。进入的每一条消息都需要通过来自Google BigQuery的一个非常大的数据集进行流式传输,并且在写入数据库之前附加了所有相关的值(基于一个键)。 问题是来自BigQuery的映射数据集非常大--任何将其用作侧输入的尝试都失败了,数据流运行程序会抛出错误“java.lang.IllegalAr