
在流式流水线中组合多个边输入时数据流失败

我已经用Python SDK(Apache Beam Python 3.7 SDK 2.19.0)构建了一个窗口流数据流管道。初始数据的表示如下:
| Phone Number | Call length |
|--------------|-------------|
| 1234 | 6 |
| 1234 | 2 |
| 5678 | 5 |
其思想是找出给定窗口中每行号码的平均通话长度。数据作为CSV的行从pub/sub中读取,我向所有行添加一个与该数字的平均调用长度相对应的值:
| Phone Number | Call length | mean call length |
|--------------|-------------|------------------|
| 1234 | 6 | 4 |
| 1234 | 2 | 4 |
| 5678 | 5 | 5 |
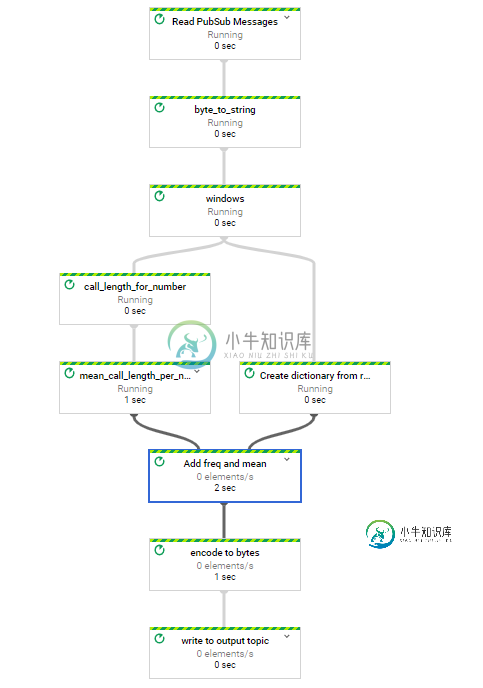
我使用以下管道:
with beam.Pipeline(options=pipeline_options) as pipeline:
calls = (pipeline
| 'Read PubSub Messages' >> beam.io.ReadFromPubSub(subscription=input_sub)
| 'byte_to_string' >> beam.Map(lambda x: x.decode("utf-8"))
| 'windows' >> beam.WindowInto(window.FixedWindows(10))
)
mean_call_length = (calls
| 'call_length_for_number' >> beam.ParDo(get_list_of_pairs_of_tuples(),'number','call_length')
| 'mean_call_length_per_number' >> beam.combiners.Mean.PerKey()
)
recombine = (calls
| 'Create dictionary from raw string' >> beam.ParDo(SplitToDict())
| 'Add mean' >> beam.FlatMap(combine_calcs,pvalue.AsList(mean_call_length))
| 'encode to bytes' >> beam.Map(lambda x: str(x).encode())
| 'write to output topic' >> beam.io.WriteToPubSub(topic=output_topic)
)
Caused by: org.apache.beam.sdk.coders.CoderException: java.io.EOFException
有什么想法吗?
共有1个答案

我通过更改管道将平均值计算的结果转换为整数来解决这个问题:
...
mean_call_length = (calls
| 'call_length_for_number' >> beam.ParDo(get_list_of_pairs_of_tuples(),'number','call_length')
| 'mean_call_length_per_number' >> beam.combiners.Mean.PerKey())
| 'convert_mean_to_int' >> beam.Map(lambda elem: (elem[0],int(elem[1])))
...
Python SDK和底层Java代码之间似乎存在一些键入问题;Java代码似乎期望元素[1]低于一定的字节数,如果通过Python SDK提交浮点数,则超过这个字节数。
-
我正在处理一个更大的数据流管道,它在批处理模式下工作得很好,但完成后的重构确实有侧输入的问题。如果我将管道置于流模式并移除侧输入,管道在Google的数据流上可以完美地工作。 如果把所有东西都剥离下来,构建以下简短的脚本来封装这个问题,并能够与它一起玩。 在Google的Dataflow中以批处理作业的形式运行这个脚本可以完成它需要做的事情。请参阅从数据流中可视化的管道:
-
我试图从一个数据流作业中运行两个分离的管道,类似于下面的问题: 一个数据流作业中的并行管道 如果我们使用单个p.run()使用单个数据流作业运行两个分离的管道,如下所示: 我认为它将在一个数据流作业中启动两个独立的管道,但它会创建两个包吗?它会在两个不同的工人上运行吗?
-
问题内容: 我是管道功能概念的新手。我有一些关于 从数据库的角度来看: 管道功能到底是什么? 使用管道功能的好处是什么? 使用管道功能解决了哪些挑战? 使用管道功能有什么优化优势? 谢谢。 问题答案: 引用“问汤姆·甲骨文”: 流水线函数只是“您可以假装为数据库表的代码” 流水线函数使您(让我惊讶) 在您认为可以使用它的任何时候-从函数而不是表中选择*可能是“有用的”。 就优点而言:使用Pipel
-
我有一个drl文件,它在两个规则流组中包含规则:“第一个规则流组”和“第二个规则流组”。这些组的激活取决于“规则A”和“规则B”。是否有任何方法可以停用规则B,以便在规则A条件匹配时触发,从而仅将焦点设置为“第一个规则流组”?
-
主要内容:实例,实例,实例,实例,实例,实例关键词:流水线,乘法器 硬件描述语言的一个突出优点就是指令执行的并行性。多条语句能够在相同时钟周期内并行处理多个信号数据。 但是当数据串行输入时,指令执行的并行性并不能体现出其优势。而且很多时候有些计算并不能在一个或两个时钟周期内执行完毕,如果每次输入的串行数据都需要等待上一次计算执行完毕后才能开启下一次的计算,那效率是相当低的。流水线就是解决多周期下串行数据计算效率低的问题。 流水线 流水线的基
-
问题内容: 我必须用Java实现HTTP客户端,并且出于我的需要,似乎最有效的方法是实现HTTP管道(按照RFC2616)。 顺便说一句,我想管道POST。(我也不在谈论多路复用。我在谈论流水线,即在接收到任何HTTP请求的响应之前,通过一个连接发送许多请求) 我找不到明确声明其支持流水线的第三方库。但是我可以使用例如Apache HTTPCore 来构建这样的客户端,或者如果需要的话,可以自己构