
在Flink(浓缩)中结合低延迟流和多元数据流

我正在评估Flink,用于流式分析场景,但还没有找到足够的信息,说明如何实现我们今天在遗留系统中所做的ETL设置。
一个非常常见的场景是,我们有一个键控的低吞吐量元数据流,我们希望使用这些数据流来丰富高吞吐量数据流,如下所示:
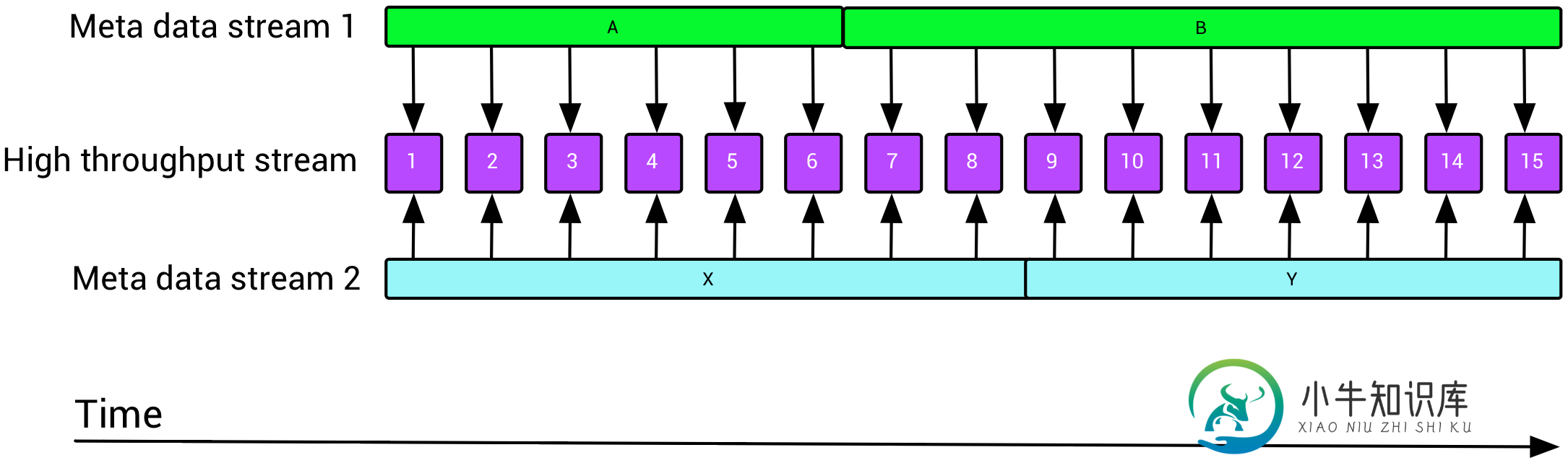
这就提出了两个关于Flink的问题:如何使用时间窗口重叠但不相等的缓慢更新流来丰富快速移动的流(元数据可以活几天,而数据可以活几分钟)?如何有效地将多个(最多10个)流与Flink连接起来,比如一个数据流和九个不同的富集流?
我知道我可以用非窗口的外部ETL缓存来实现我的ETL场景,例如用Redis(这就是我们今天使用的),但是我想看看Flink提供了哪些可能性。
共有1个答案

Flink有几种可用于浓缩的机制。
我将假设所有流共享一个可用于连接相应项的公共键。
最简单的方法可能是使用richflatmap并在其open()方法(关于rich函数的文档)中加载静态浓缩数据。这仅适用于浓缩数据是静态的,或者当您希望更新浓缩数据时愿意重新启动浓缩作业的情况。
您将在Apache Flink培训教材中找到详细的示例和代码。
如果您有许多流(例如,10个)要连接,您可以级联一系列这两个输入的coProcessFunction运算符,但不可否认,这在某些时候会变得相当尴尬。另一种方法是使用union运算符将所有元数据流组合在一起(注意,这要求所有流具有相同的类型),然后使用richcoflatmap或coprocessfunction将这个统一的浓缩流与主流连接起来。
更新:
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.orderId AND
o.ordertime BETWEEN s.shiptime - INTERVAL '4' HOUR AND s.shiptime
-
我想使用Flink流媒体以低延迟处理市场数据( 我有一组计算,每个都订阅三个流:缓慢移动的参数数据、股票价格和汇率。 例如。 Params(缓慢滴答:每天一次或两次): 资源(每秒多次滴答声): fx(每秒多次滴答声): 每当任何股票、外汇汇率或参数数据发生变化时,我都想立即计算结果并将其输出为新流。这在逻辑上可以表示为连接: 例如选择价格=(params.strike-asset.spot)*f
-
我有一个这样的事件来源 我需要通过用户过去的网页访问来丰富我的事件流。(我在数据库中拥有信息,我可以将其用作Flink源) 如何确保在开始处理事件流之前,我已经准备好了扩展数据 我不想从流中进行DB调用。
-
我试图开发以下代码,但它不起作用。我想使用apache Flink来延迟时间(在时间戳字段中指定的)与当前日期不同的事件。 样品: > 当前日期:2022-05-06 10:30 事件1[{“user1”:“1”,“user2”:“2”,“timestamp”:“2022-05-06 10:30”}-- 事件2[{“user1”:“1”,“user2”:“2”,“timestamp”:“2022-
-
在Espresso中,应用程序启动,测试以以下代码开始:onView(withId(r.id.choosebooktitle)).perform(click()); 这会崩溃,因为显示器仍然显示启动屏幕,而chooseBookTitle只有在之后才可见。如何防止谷歌-浓缩咖啡会在它出现之前点击键? (我不想插入等待循环,而是保持事件驱动。在更糟糕的情况下,我回到Robotium)
-
我正在尝试运行Flink流媒体作业。我想确定流处理的延迟和吞吐量。我已启动Kafka代理服务器,并收到来自Kafka的传入消息。如何计算每秒的邮件数(吞吐量)?(如rdd.count。是否有类似的方法来获取传入消息的计数) (完整的场景:我已经通过生产者发送了消息作为Json对象。我在Json对象中添加了一些信息,如名称为字符串和System.currentTimeMills。在流式传输期间,我如
-
如何在允许的延迟期结束之前“清除”窗口元数据(WindowOperator和InternalTimer)? 是否可以将此元数据与窗口数据本身一起清除? 我们不介意丢失元数据——不需要根据之前非延迟数据的上下文来处理具有相同关键时间的延迟事件。 一些背景知识- [目前正在使用Flink-v1.6]我们正在处理事件时间窗口,并处理大量具有唯一键的事件。95%的活动不会迟到,只会开火一次。 我们的工作规