
Apache Flink 是高效和分布式的通用数据处理平台,是一个流批一体分析引擎。
Apache Flink 声明式的数据分析开源系统,结合了分布式 MapReduce 类平台的高效,灵活的编程和扩展性。同时在并行数据库发现查询优化方案。
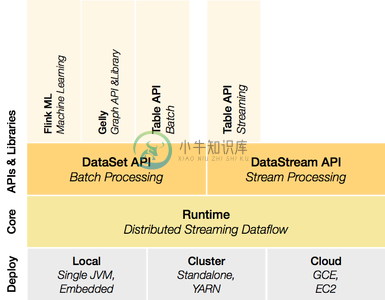
要求
-
Unix 类环境(Linux, Mac OS X, Cygwin)
-
git
-
Maven (at least version 3.0.4)
-
Java 6, 7 or 8 (Note that Oracle's JDK 6 library will fail to build Flink, but is able to run a pre-compiled package without problem)
git clone https://github.com/apache/incubator-flink.git cd incubator-flink mvn clean package -DskipTests # this will take up to 5 minutes
-
Apache Flink是一种可以处理批处理任务的流处理框架。该技术可将批处理数据视作具备有限边界的数据流,借此将批处理任务作为流处理的子集加以处理。为所有处理任务采取流处理为先的方法会产生一系列有趣的副作用。 这种流处理为先的方法也叫做Kappa架构,与之相对的是更加被广为人知的Lambda架构(该架构中使用批处理作为主要处理方法,使用流作为补充并提供早期未经提炼的结果)。Kappa架构中会对一
-
Apache Flink 入门,了解 Apache Flink 1、如何通俗易懂的解释 Flink Flink 主要在协议层面做了各类协议的转换,降低了各数据之间的转换成本,另外 Flink 基于内存保持状态,性能很高 Flink 支持集群和分布式部署,可以支持海量的吞吐,达到 TB 级,相比于传统的数据处理方式,Flink 可以把数据直接转换成表格 比如一个 JSON List ,Flink 可
-
来源|Apache Flink 官方博客 Apache Flink 社区很荣幸地宣布 Apache Flink ML 2.1.0 版本正式发布!本次发布的版本重点改进了 Flink ML 的基础设施,例如 Python SDK,内存管理,以及性能测试框架,来帮助开发者基于 Flink ML 开发具有高性能,高稳定性,以及高易用性的机器学习算法库。 基于本次发版中提出的改进,以及我们得到的性能测试结
-
Apache Flink 社区非常高兴地宣布了 Apache Flink 1.14.4 发布了,这是 Apache Flink 1.14 的第三个 bugfix 版本. 这个版本修复了 51 个 bug 和漏洞,并对 Flink 1.14 进行了小的改进。下面是所有 bug 修复和改进的列表(不包括对构建基础结构和构建稳定性的改进)。有关所有更改的完整列表,请参阅: JIRA 我们强烈建议所有用户
-
我有以下代码来计算socketTextStream中的单词。累积字数和时间窗字数都是必需的。该程序存在累积计数始终与窗口计数相同的问题。为什么会出现这个问题?根据加窗计数计算累积计数的正确方法是什么?
-
那么,如何将作业配置为先运行单个步骤,然后并行运行多个步骤,然后运行最后一个步骤呢?
-
我想在Apache Flink中做流媒体工作来做Kafka- 这应该是流式处理。
-
我正在尝试为ApacheFlink导入ScalaAPI流扩展,如中所述https://ci.apache.org/projects/flink/flink-docs-master/apis/scala_api_extensions.html 但是,我的ScalaIDE抱怨以下消息:对象扩展不是包的成员org.apache.flink.streaming.api.scala 我使用的是scala 2
-
在获得网站访问量基本数据的情况下对有关数据进行统计、分析,从中发现用户访问网站的规律,并将这些规律与网络营销策略等相结合。
-
我想在Apache Flink中实现以下场景: 给定一个具有4个分区的Kafka主题,我想使用不同的逻辑在Flink中独立处理分区内数据,具体取决于事件的类型。 特别是,假设输入Kafka主题包含前面图像中描述的事件。每个事件具有不同的结构:分区1具有字段“a”作为关键字,分区2具有字段“b”作为关键字,等等。在Flink中,我希望根据事件应用不同的业务逻辑,所以我认为我应该以某种方式分割流。为了
-
背景:我一直试图在部署在运动分析运行时的同一个flink应用程序中设置BATCH STREAMING。流部分工作正常,但我有麻烦添加支持BATCH。 Flink:处理数据早于应用程序水印的密钥流 Apache Flink:数据流API的批处理模式失败,但“非法状态异常:排序输入不允许检查点”除外。' 逻辑是这样的: 这样做,我得到了以下例外: 似乎运动分析不允许客户端定义flink-conf.ya
-
一、功能简介 内容时代,用户越来越多的时间被各种资讯流、视频流所占用。这些信息浏览形式的技术形态,我们统称为“信息流”。它不仅是提供信息为主的内容类产品最重要的产品样式,目前也已经被广泛的被应用在工具类、社区类等以信息为补充功能的应用内。 MTJ通过分析市面上主流信息流产品的产品形态及用户使用习惯等核心要素,搭建了信息流分析模型,并于5月正式上线“信息流分析”功能。 对于信息流的分析,有助于帮助信