
1.2 机器学习的三种不同方法
本节我们将介绍三种不同类型的机器学习方法:监督学习(supervised learning)、无监督学习(unsupervised learning)和强化学习(reinforcement learning)。我们将学习三种不同方法之间的本质区别,并使用概念性示例,让大家对这三种方法在实际问题中的应用有一个直观的认识。

1.2.1 通过监督学习对未来事件进行预测
监督学习的主要目的是使用有类标的训练(training)数据构建模型,我们可以使用经训练得到的模型对未来数据进行预测。此处,术语监督(supervised)是指训练数据集中的每个样本均有一个已知的输出项(类标(label))。
以(过滤)垃圾邮件为例:基于有类标的电子邮件样本库,可以使用监督学习算法训练生成一个判定模型,用来判别一封新的电子邮件是否为垃圾邮件;其中,在用于训练的电子邮件样本库中,每一封电子邮件都已被准确地标记是否为垃圾邮件。监督学习一般使用离散的类标(class label),类似于过滤垃圾邮件的这类问题也被称为分类(classification)。监督学习的另一个子类是回归(regression),回归问题的输出项是连续值。

1.利用分类对类标进行预测
分类是监督学习的一个子类,其目的是基于对过往类标已知示例的观察与学习,实现对新样本类标的预测。这些类标是离散的、无序的值,它们可以视为样本的组别信息(group membership)。前面提到的检测垃圾邮件的例子是一个典型的二类别分类(binary classification)任务,机器学习算法会生成一系列的规则用以判定邮件属于垃圾邮件还是非垃圾邮件。
然而,类标集合并非一定是二类别分类的。通过监督学习算法构造的预测模型可以将训练样本库中出现的任何类标赋给一个尚未被标记的新样本。手写字符识别就是一个典型的多类别分类(multi-class classification)的例子。在此,我们可以将字母表中每个字母的多个不同的手写样本收集起来作为训练数据集。此时,若用户通过输入设备给出一个新的手写字符,我们的预测模型能够以一定的准确率将其判定为字母表中的某个字母。然而,如果我们的训练样本库中没有出现0~9的数字字符,那么模型将无法正确辨别任何输入的数字。
下图通过给出具有30个训练样本的实例说明二类别分类任务的概念:15个样本被标记为负类别(negative class)(图中用圆圈表示);15个样本被标记为正类别(positive class)(图中用加号表示)。此时,我们的数据集是二维的,这意味着每个样本都有两个与其关联的值:x1和x2。现在,我们可以通过有监督的机器学习算法获得一条规则,并将其表示为一条黑色虚线标识的分界线、它可以将两类样本分开,并且可以根据给定的x1、x2值将新样本划分到某个类别中。

2.使用回归预测连续输出值
通过上一节的学习,我们知道了分类的任务就是将具有类别的、无序类标分配给各个新样本。另一类监督学习方法针对连续型输出变量进行预测,也就是所谓的回归分析(regression analysis)。在回归分析中,数据中会给出大量的自变量(解释变量)和相应的连续因变量(输出结果),通过尝试寻找这两种变量之间的关系,就能够预测输出变量。
例如,假定我们想预测学生SAT考试中数学科目的成绩。如果花费在学习上的时间和最终的考试成绩有关联,则可以将其作为训练数据来训练模型,以根据学习时间预测将来要参加考试的学生的成绩。
 “回归”一词最早是由Francis Galton于1886年在其论文“Regression Towards Mediocrity in Hereditary Stature”中提出来的。他在文章中描述了这样一种生物现象,即人口身高的方差没有随着时间的推移而增加。他发现:父辈并未将其身高直接遗传给子辈,而子辈的身高更接近于人们的平均身高。
“回归”一词最早是由Francis Galton于1886年在其论文“Regression Towards Mediocrity in Hereditary Stature”中提出来的。他在文章中描述了这样一种生物现象,即人口身高的方差没有随着时间的推移而增加。他发现:父辈并未将其身高直接遗传给子辈,而子辈的身高更接近于人们的平均身高。
下面用图例阐述了线性回归(linear regression)的概念。给定一个自变量x和因变量y,拟合一条直线使得样例数据点与拟合直线之间的距离最短,最常用的是采用平均平方距离来计算。这样我们就可以通过对样本数据的训练来获得拟合直线的截距和斜率,从而对新的输入变量值所对应的输出变量值进行预测。

1.2.2 通过强化学习解决交互式问题
另一类机器学习方法是强化学习。强化学习的目标是构建一个系统(Agent),在与环境(environment)交互的过程中提高系统的性能。环境的当前状态信息中通常包含一个反馈(reward)信号,我们可以将强化学习视为与监督学习相关的一个领域。然而,在强化学习中,这个反馈值不是一个确定的类标或者连续类型的值,而是一个通过反馈函数产生的对当前系统行为的评价。通过与环境的交互,Agent可以通过强化学习来得到一系列行为,通过探索性的试错或者借助精心设计的激励系统使得正向反馈最大化。
一个常用的强化学习例子就是象棋对弈的游戏。在此,Agent根据棋盘上的当前局态(环境)决定落子的位置,而游戏结束时胜负的判定可以作为激励信号。

1.2.3 通过无监督学习发现数据本身潜在的结构
在监督学习中,训练模型之前,我们事先可以获知各训练样本对应的目标值。在强化学习中,可以由Agent定义反馈函数对特定行为进行判定。然而,在无监督学习中,我们将处理无类标数据或者是总体分布趋势不明朗的数据。通过无监督学习,我们可以在没有已知输出变量和反馈函数指导的情况下提取有效信息来探索数据的整体结构。
1.通过聚类发现数据的子群
聚类是一种探索性数据分析技术。在没有任何相关先验信息的情况下,它可以帮助我们将数据划分为有意义的小的组别(即簇(cluster))。对数据进行分析时,生成的每个簇中其内部成员之间具有一定的相似度,而与其他簇中的成员则具有较大的不同,这也是为什么聚类有时被称为“无监督分类”。聚类是获取数据的结构信息,以及导出数据间有价值的关系的一种很好的技术,例如,它使得市场人员可以基于用户的兴趣将其分为不同的类别,以分别制定相应的市场营销计划。
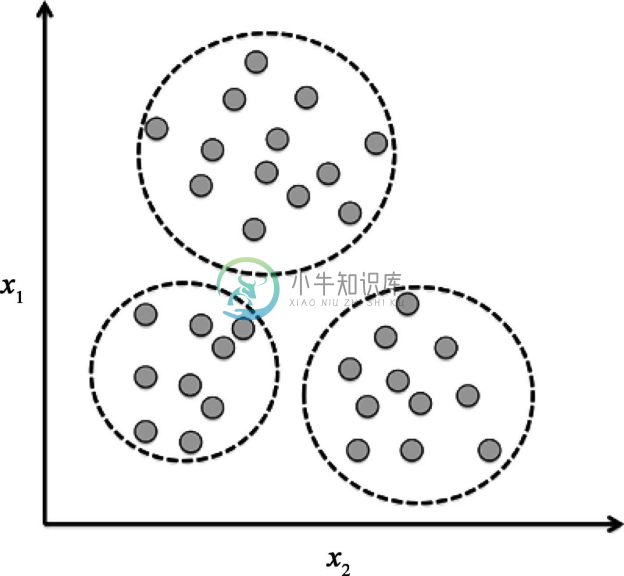
下图演示了聚类方法如何根据数据的x1及x2两个特征值之间的相似性将无类标的数据划分到三个不同的组中。
2.数据压缩中的降维
数据降维(dimensionality reduction)是无监督学习的另一个子领域。通常,我们面对的数据都是高维的(每一次采样都会获取大量的样本值),这就对有限的数据存储空间以及机器学习算法性能提出了挑战。无监督降维是数据特征预处理时常用的技术,用于清除数据中的噪声,它能够在最大程度保留相关信息的情况下将数据压缩到一个维度较小的子空间,但同时也可能会降低某些算法在准确性方面的性能。
降维技术有时在数据可视化方面也是非常有用的。例如,一个具有高维属性的数据集可以映射到一维、二维或者三维的属性空间,并通过三维或二维的散点图和直方图对数据进行可视化展示。下图展示了一个使用非线性降维方法将三维的Swiss Roll压缩到二维特征子空间的实例。

1.2.4 基本术语及符号介绍
目前我们已经讨论了机器学习的三大方法:监督学习、无监督学习和强化学习。在此,我们介绍一下下一章将要用到的一些基本术语。下面表格摘录了鸢尾花数据集(Iris dataset)中的部分数据,鸢尾花数据集是机器学习领域的一个经典示例,它包含了Setosa、Versicolor和Virginica三个品种总共150种鸢尾花的测量数据。其中,每一个样本代表数据集中的一行,而花的测量值以厘米为度量单位存储为列,我们将其定义为数据集的特征。

为了保证描述过程中所用符号及推理过程简单、高效,我们将采用线性代数(Linear algebra)中的一些基本知识。在后续章节中,我们将主要使用矩阵和向量来标识数据。并做如下约定:矩阵X中的每一行代表一个样本,而样本中的每个特征都表示为单独的列。
在鸢尾花数据集中,包含150个样本和4个特征,因此将其记作150×4维的矩阵X∈R150×4:

 在本书中,我们将使用上标(i)来指代第i个训练样本,使用下标(j)来指代训练数据集中的第j维特征。
在本书中,我们将使用上标(i)来指代第i个训练样本,使用下标(j)来指代训练数据集中的第j维特征。

类似地,可以用一个150维的列向量来存储目标变量(在本例中为类标):
