
Java基于WebMagic爬取某豆瓣电影评论的实现

目的
搭建爬虫平台,爬取某豆瓣电影的评论信息。
准备
webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。webmagic的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬虫开发的材料。
下载WebMagic源码,或Maven导入,或Jar包方式导入。 码云地址:https://gitee.com/flashsword20/webmagic
试运行
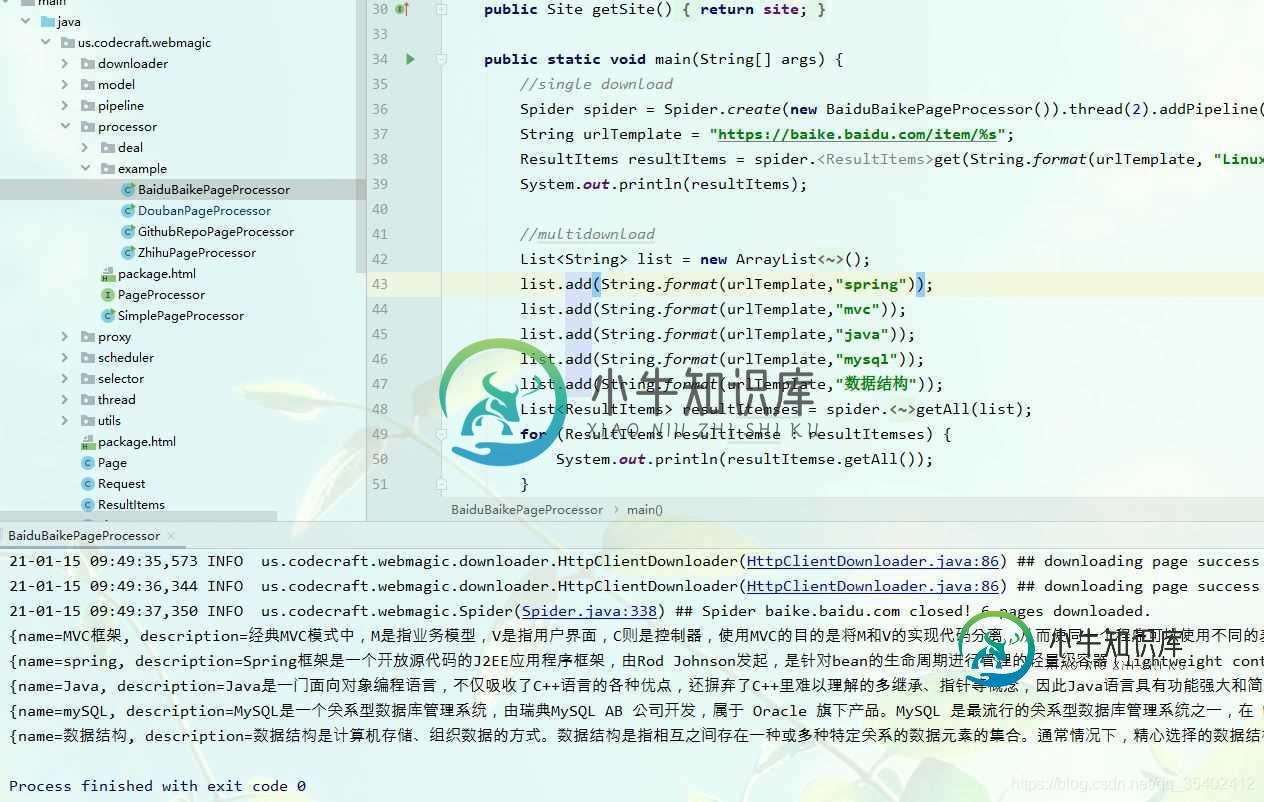
搭建好后打开项目, 在 us.codecraft.webmagic.processor.example 包下有几个可运行的例子,我们可以直接运行体验(BaiduBaikePageProcessor 百度百科的这个比较稳定)。
爬到结果说明没问题。
自定义爬虫
接下来我们自己编写一个爬取豆瓣评论的爬虫。
爬取地址:https://movie.douban.com/subject/35096844/reviews?start=0
F12进入开发者html" target="_blank">模式 分析前端页面
我们发现我们需要爬取的评论信息存放在 class=short-content的div 中。
创建一个豆瓣爬取的类DoubanPageProcessor如下:
package us.codecraft.webmagic.processor.example;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.List;
import java.util.Map;
/**
* A simple PageProcessor.
* 爬取豆瓣某电影的评论 爬取地址:https://movie.douban.com/subject/35096844/reviews?start=0
*
* @author code4crafter@gmail.com <br>
* @since 0.1.0
*/
public class DoubanPageProcessor implements PageProcessor {
private Site site;
public DoubanPageProcessor(String urlPattern) {
this.site = Site.me().setRetryTimes(3).setSleepTime(300); // 设置站点重试次数3 间隔300ms
}
@Override
public void process(Page page) {
page.putField("title", page.getHtml().xpath("//title/text()")); //爬取网页标题
// page.putField("html", page.getHtml().toString()); //爬取整个页面的html
page.putField("titleList", page.getHtml().css("div.short-content", "text").all()); // 我们要爬取的核心信息内容,获取方式与css选择器用法一样
// page.putField("content", page.getHtml().smartContent());
}
@Override
public Site getSite() {
//settings
return site;
}
public static void main(String[] args) {
Spider spider = Spider.create(new DoubanPageProcessor("https://movie\\.douban\\.com\\d+"));
ResultItems resultItems = spider.<ResultItems>get("https://movie.douban.com/subject/35096844/reviews?start=0");// 爬取并获得爬取结果
Map<String, Object> map = resultItems.getAll();
for (Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue()); //打印爬取的所有内容
}
List<String> shortList = (List<String>) map.get("titleList");
System.out.println("=====================分隔线===================\n短评如下:");
for (int i = 0; i < shortList.size(); i++) {
System.out.println(i + "、" + shortList.get(i).trim()); // 打印爬取的评论内容
}
spider.close();
}
}
运行结果如下:
爬取成功。
到此这篇关于Java基于WebMagic爬取某豆瓣电影评论的实现的文章就介绍到这了,更多相关Java WebMagic爬取内容请搜索小牛知识库以前的文章或继续浏览下面的相关文章希望大家以后多多支持小牛知识库!
-
本文向大家介绍Python爬豆瓣电影实例,包括了Python爬豆瓣电影实例的使用技巧和注意事项,需要的朋友参考一下 文件结构 html_downloader.py - 下载网页html内容 html_outputer.py - 输出结果到文件中 html_parser.py: 解析器:解析html的dom树 spider_main.py - 主函数 综述 其实就是使用了urllib2和Beauti
-
通过本案例[豆瓣电影Top250信息爬取]锻炼除正则表达式之外三种信息解析方式:Xpath、BeautifulSoup和PyQuery。 爬取url地址:https://movie.douban.com/top250 分析: 分析url地址:https://movie.douban.com/top250 每页25条数据,共计10页 第一页:https://movie.douban.com/top2
-
本文向大家介绍Python多线程爬取豆瓣影评API接口,包括了Python多线程爬取豆瓣影评API接口的使用技巧和注意事项,需要的朋友参考一下 爬虫库 使用简单的requests库,这是一个阻塞的库,速度比较慢。 解析使用XPATH表达式 总体采用类的形式 多线程 使用concurrent.future并发模块,建立线程池,把future对象扔进去执行即可实现并发爬取效果 数据存储 使用Pytho
-
本文向大家介绍实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250,包括了实践Python的爬虫框架Scrapy来抓取豆瓣电影TOP250的使用技巧和注意事项,需要的朋友参考一下 安装部署Scrapy 在安装Scrapy前首先需要确定的是已经安装好了Python(目前Scrapy支持Python2.5,Python2.6和Python2.7)。官方文档中介绍了三种方法进行安装,我采用的
-
本文向大家介绍基于python实现的抓取腾讯视频所有电影的爬虫,包括了基于python实现的抓取腾讯视频所有电影的爬虫的使用技巧和注意事项,需要的朋友参考一下 我搜集了国内10几个电影网站的数据,里面近几十W条记录,用文本没法存,mongodb学习成本非常低,安装、下载、运行起来不会花你5分钟时间。
-
本文向大家介绍基于豆瓣API+Angular开发的web App,包括了基于豆瓣API+Angular开发的web App的使用技巧和注意事项,需要的朋友参考一下 一、扯淡的说 name:【豆瓣搜索】 最近关注了下豆瓣的API,发现豆瓣开放平台需要加强API文档撰写啊....但是有个可喜的发现豆瓣V2接口提供了搜索接口。最近在用phantom弄些爬虫,想想,真是美丽极了!有个豆瓣的接口,我都不用去