
1.1 什么是知识图谱
知识图谱是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法[1] 。知识图谱由节点和边组成。节点可以是实体,如一个人、一本书等,或是抽象的概念,如人工智能、知识图谱等。边可以是实体的属性,如姓名、书名,或是实体之间的关系,如朋友、配偶。知识图谱的早期理念来自Semantic Web[2,3] (语义网),其最初理想是把基于文本链接的万维网转化成基于实体链接的语义网。
1989年,Tim Berners-Lee 提出构建一个全球化的以“链接”为中心的信息系统(Linked Information System)。任何人都可以通过添加链接把自己的文档链入其中。他认为,相比基于树的层次化组织方式,以链接为中心和基于图的组织方式更加适合互联网这种开放的系统。这一思想逐步被人们实现,并演化发展成为今天的World Wide Web。
1994年,Tim Berners-Lee 又提出 Web 不应该仅仅只是网页之间的互相链接。实际上,网页中描述的都是现实世界中的实体和人脑中的概念。网页之间的链接实际包含语义,即这些实体或概念之间的关系;然而,机器却无法有效地从网页中识别出其中蕴含的语义。他于1998年提出了Semantic Web的概念[4] 。Semantic Web仍然基于图和链接的组织方式,只是图中的节点代表的不只是网页,而是客观世界中的实体(如人、机构、地点等),而超链接也被增加了语义描述,具体标明实体之间的关系(如出生地是、创办人是等)。相对于传统的网页互联网,Semantic Web的本质是数据的互联网(Web of Data)或事物的互联网(Web of Things)。
在 Semantic Web 被提出之后,出现了一大批新兴的语义知识库。如作为谷歌知识图谱后端的Freebase[5] ,作为IBM Waston后端的DBpedia[6] 和Yago[7] ,作为Amazon Alexa后端的True Knowledge,作为苹果Siri后端的Wolfram Alpha,以及开放的Semantic Web Schema——Schema.ORG[8] ,目标成为世界最大开放知识库的Wikidata[9] 等。尤其值得一提的是,2010年谷歌收购了早期语义网公司 MetaWeb,并以其开发的 Freebase 作为数据基础之一,于2012年正式推出了称为知识图谱的搜索引擎服务。随后,知识图谱逐步在语义搜索[10,11] 、智能问答[12-14] 、辅助语言理解[15,16] 、辅助大数据分析[17-19] 、增强机器学习的可解释性[20] 、结合图卷积辅助图像分类[21,22] 等多个领域发挥出越来越重要的作用。
如图1-1所示,知识图谱旨在从数据中识别、发现和推断事物与概念之间的复杂关系,是事物关系的可计算模型。知识图谱的构建涉及知识建模、关系抽取、图存储、关系推理、实体融合等多方面的技术,而知识图谱的应用则涉及语义搜索、智能问答、语言理解、决策分析等多个领域。构建并利用好知识图谱需要系统性地利用包括知识表示(Knowledge Representation)、图数据库、自然语言处理、机器学习等多方面的技术。
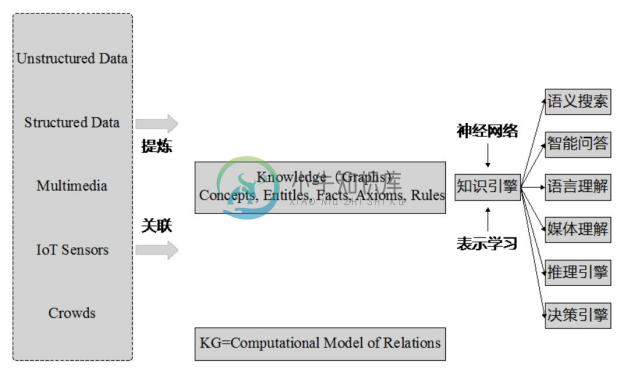
图1-1 知识图谱:事物关系的可计算模型