
4.6 开源工具实践:基于DeepDive的关系抽取实践
本实践介绍了一个公司实体间的股权交易关系的实例,该案例是基于斯坦福大学DeepDive 开源关系抽取框架实现的。本实践的相关工具、实验数据及操作说明由OpenKG提供,地址为http://openkg.cn。该框架遵循Apache开源协议。
4.6.1 开源工具的技术架构
如图4-41所示为DeepDive的整体处理流程,主要分为数据准备和因子图模型构建两个部分,CNdeepdive 在此基础上添加了神经网络模型和增量操作。在具体应用中,可以选择使用因子图模型或神经网络模型。
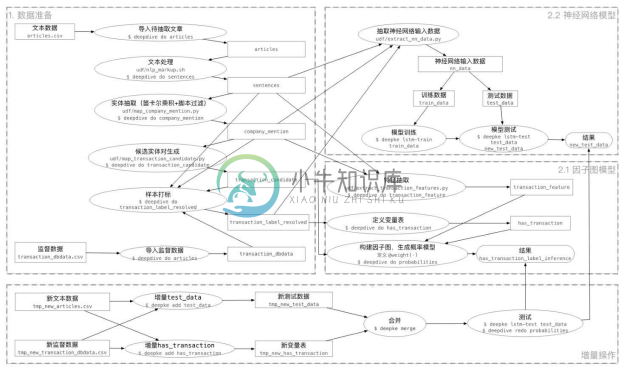
图4-41 DeepDive的整体处理流程
图中浅色字体部分是股权交易关系抽取实例在框架中对应的文件名、命令或需要配置的脚本文件。执行上述流程需要注意以下几点:
1.环境配置
运行该框架需要配置的DeepDive、PostgreSQL和中文Standford NLP环境。DeepDive可以从OpenKG网站下载。可选择配置deepke的扩展功能。
2.数据准备
数据准备阶段需要进行的处理包括导入结构化的监督数据、导入文本数据、利用NLP模块进行文本处理、实体抽取、候选实体对生成及样本打标。
文本处理阶段可能会非常慢,可通过减少articles的行数来缩短时间。
3.因子图模型
在构建因子图模型之前,需要先进行特征抽取。
4.深度学习
深度学习模型需要准备训练和测试数据。模型输入的 train_data 和 test_data 需要符合神经网络的输入。
5.增量操作
并或清空操作。其他类似工具增量操作必须在原工作流程定下来之后进行。
对于添加新数据部分 input 文件下的所有初始数据,都需要做一份增量。如果没有增量的需要,则定义空文件。如果需要使用原数据,则复制原有文件。
需要先合并再进行新的测试或训练步骤,即增量只是数据准备过程中的增量。
若想单独测试新的测试数据,直接在合并之前执行deepke lstm-test tmp_new_test_data tmp_new_new_test_data。查看结果后再执行合并或清空操作。
4.6.2 其他类似工具
Reverb是华盛顿大学Turing center研发的开放三元组抽取工具,可以从英文句子中抽取形如(augument1, relation, argument2)的三元组。它不需要提前指定关系,支持全网规模的信息抽取。目前用于华盛顿大学开发的KnowItAll知识库系统。
OLLIE 和 Reverb 类似,都是华盛顿大学研发的知识库 KnowItAll 的三元组抽取组件,OLLIE 是第二代提取系统。Reverb 的抽取建立在文本序列上,而 OLLIE 则支持基于语法依赖树的关系抽取,对于长线依赖效果更好。
Wandora是封装好的知识抽取桌面程序,支持主题图、RDF、OBO等多种输入输出格式。它内置了HTTP服务器,有完整的交互界面,支持输出可视化。