
2.3 互联网时代的语义网知识表示框架
随着语义网的提出,知识表示迎来了新的契机和挑战,契机在于语义网为知识表示提供了一个很好的应用场景,挑战在于面向语义网的知识表示需要提供一套标准语言可以用来描述Web的各种信息。早期Web的标准语言HTML和XML无法适应语义网对知识表示的要求,所以W3C提出了新的标准语言RDF、RDFS和OWL。这两种语言的语法可以跟XML兼容。下面详细介绍这几种语言。
2.3.1 RDF和RDFS
RDF是W3C的RDF工作组制定的关于知识图谱的国际标准。RDF是W3C一系列语义网标准的核心,如图2-4所示。
●表示组(Representation)包括URI/IRI、XML和RDF。前两者主要是为RDF提供语法基础。
●推理组(Reasoning)包括RDF-S、本体OWL、规则RIF和统一逻辑。统一逻辑目前还没有定论。
●信任组和用户互动组。
图2-4对W3C的语义网标准栈做了分组。目前,跟知识图谱最相关的有:
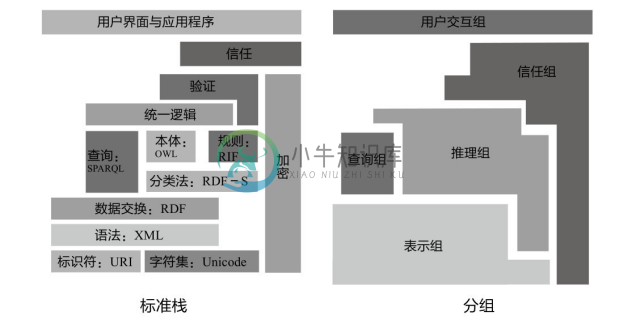
图2-4 W3C的语义网标准栈及其分组
2006年,人们开始用 RDF 发布和链接数据,从而生成知识图谱,比较知名的有DBpedia、Yago和Freebase。2009年,Tim Berners-Lee为进一步推动语义网开放数据的发展,进一步提出了开放链接数据的五星级原则,如表2-3所示。
表2-3 开放链接数据的五星级原则
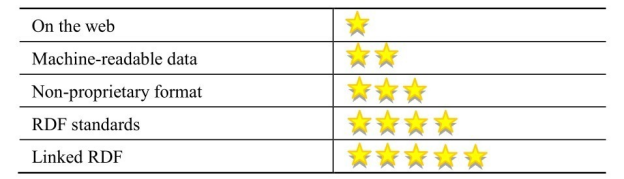
Tim Berners-Lee提出了实现五星级原则的四个步骤:
●使用URIs对事物命名;
●使用HTTP URIs,以方便搜索;
●使用RDF 描述事物并提供SPARQL端点,以方便对RDF图谱查询;
●链接不同的图谱(例如通过owl:sameAs),以方便数据重用。
2007年,不少开放图谱实现与DBpedia链接。如图2-5为开放链接数据早期的发展。
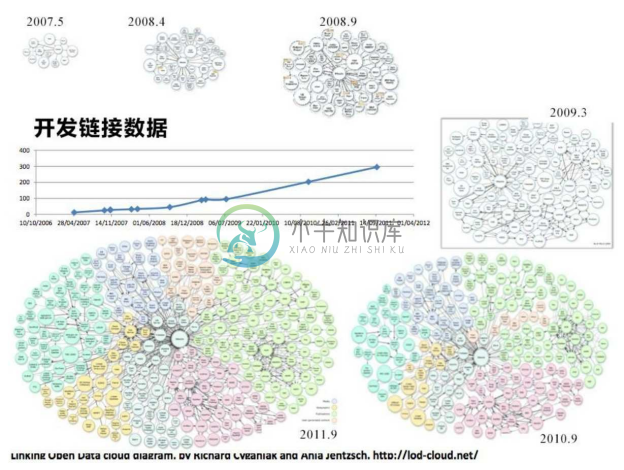
图2-5 开放链接数据早期的发展
1.RDF简介
在 RDF 中,知识总是以三元组的形式出现。每一份知识可以被分解为如下形式:(subject,predicate,object)。例如,“IBM邀请Jeff Pan作为讲者,演讲主题是知识图谱”可以写成以下 RDF 三元组:(IBM-Talk,speaker,Jeff),(IBM-Talk,theme,KG)。RDF 中的主语是一个个体(Individual),个体是类的实例。RDF 中的谓语是一个属性。属性可以连接两个个体,或者连接一个个体和一个数据类型的实例。换言之,RDF 中的宾语可以是一个个体,例如(IBM-Talk,speaker,Jeff)也可以是一个数据类型的实例,例如(IBM-Talk,talkDate,“05-10-2012”^xsd:date)。
如果把三元组的主语和宾语看成图的节点,三元组的谓语看成边,那么一个 RDF 知识库则可以被看成一个图或一个知识图谱,如图2-6所示。三元组则是图的单元。
在 RDF 中,三元组中的主谓宾都有一个全局标识 URI,包括以上例子中的 Jeff、IBM_Talk 和KG,如图2-7所示。
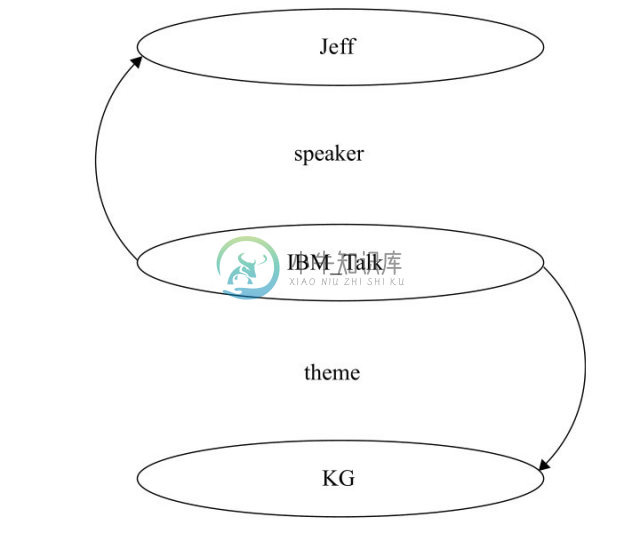
图2-6 一个RDF知识库可以被看成一个图
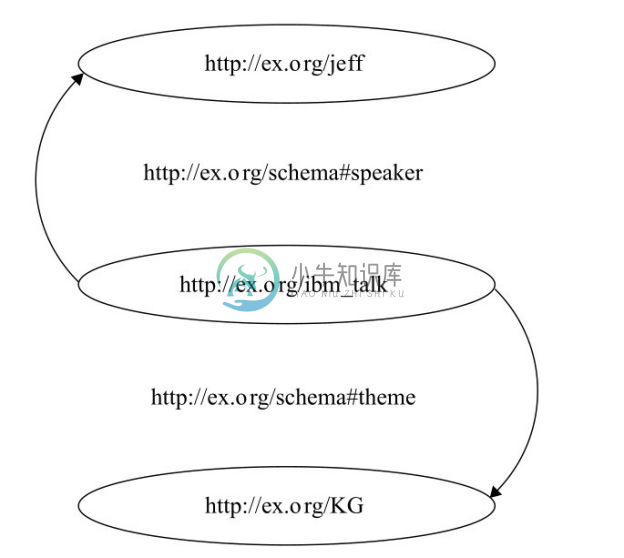
图2-7 三元组的全局标识URI
全局标识 URI 可以被简化成前缀 URI,如图2-8所示。RDF 允许没有全局标识的空白节点(Blank Node)。空白节点的前缀为“_”。例如,Jeff 是某一次关于 KG 讲座的讲者,如图2-9所示。
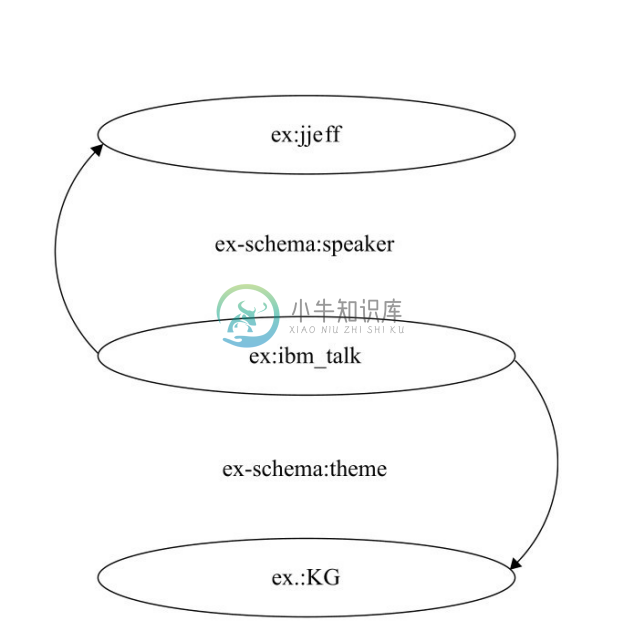
图2-8 前缀URI
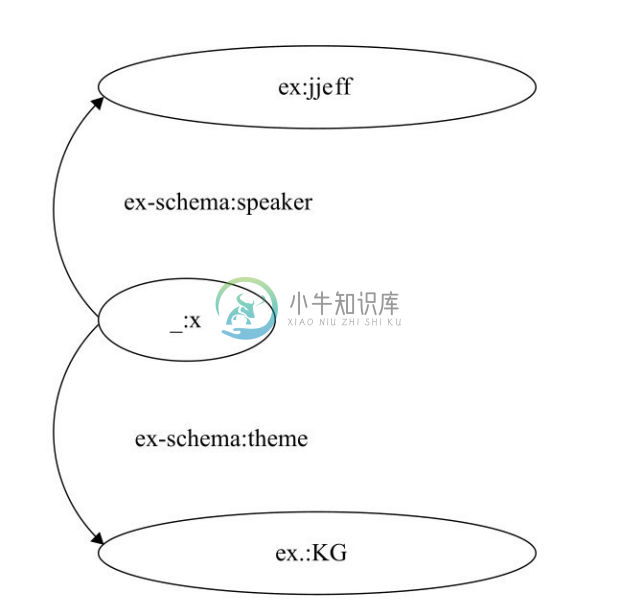
图2-9 没有全局标识的空白节点
RDF 是抽象的数据模型,支持不同的序列化格式,例如 RDF/XML、Turtle 和 N-Triple,如图2-10所示。
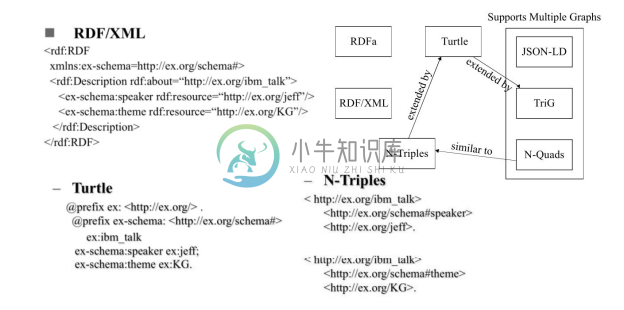
图2-10 不同的序列化格式
2.开放世界假设
不同于经典数据库采用封闭世界假设,RDF采用的是开放世界假设。也就是说,RDF图谱里的知识有可能是不完备的,这符合 Web 的开放性特点和要求。(IBM-Talk,speaker,Jeff)并不意味着 IBM 讲座只有一位讲者。换一个角度,(IBM-Talk,speaker,Jeff)意味着 IBM 讲座至少有一位讲者。采用开放世界假设意味着 RDF 图谱可以被分布式储存,如图2-11所示。
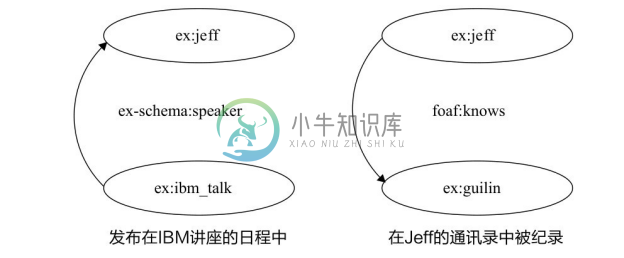
图2-11 RDF图谱可以被分布式储存
同时,分布式定义的知识可以自动合并,如图2-12所示。
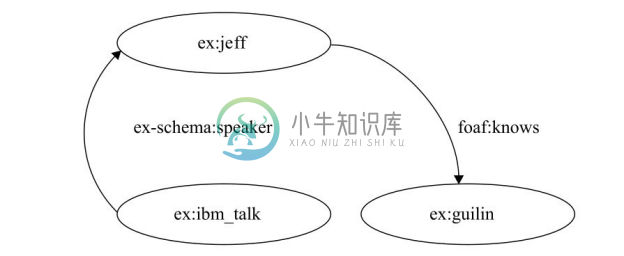
图2-12 分布式定义的知识可以自动合并3.RDFS 简介
RDF 用到了类以及属性描述个体之间的关系。这些类和属性由模式(schema)定义。RDF Schema(RDF 模式,简称 RDFS)提供了对类和属性的简单描述,从而给 RDF数据提供词汇建模的语言。更丰富的定义则需要用到OWL本体描述语言。
RDFS提供了最基本的对类和属性的描述元语:
●rdf:type :用于指定个体的类;
●rdfs:subClassOf:用于指定类的父类;
●rdfs:subPropertyOf:用于指定属性的父属性;
●rdfs:domain:用于指定属性的定义域;
●rdfs:range:用于指定属性的值域。
举例来说,下面的三元组表示用户自定义的元数据 Author 是 Dublin Core 的元数据Creator的子类,如图2-13所示。
RDF Schema 通过这样的方式描述不同词汇集的元数据之间的关系,从而为网络上统一格式的元数据交换打下基础。下面用图2-14说明 RDFS,为了简便,边的标签省略了RDF 或者 RDFS。知识被分为两类,一类是数据层面的知识,例如 haofen type Person (haofen 是 Person 类的一个实例),另外一类是模式层面的知识,例如 speaker domain Person(speaker属性的定义域是Person类)。
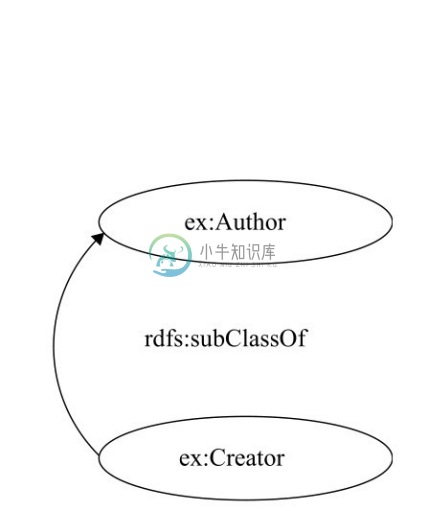
图2-13 Author是Creator的子类
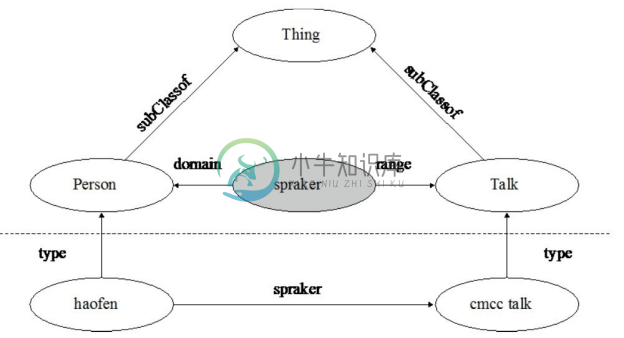
图2-14 RDFS示例
2.3.2 OWL和OWL2 Fragments
前面介绍了RDF和RDFS,通过RDF(S)可以表示一些简单的语义,但在更复杂的场景下,RDF(S)语义的表达能力显得太弱,还缺少常用的特征:
(1)对于局部值域的属性定义。 RDF(S)中通过rdfs:range定义了属性的值域,该值域是全局性的,无法说明该属性应用于某些具体的类时具有的特殊值域限制,如无法声明父母至少有一个孩子。
(2)类、属性、个体的等价性。 RDF(S)中无法声明两个类或多个类、属性和个体是等价还是不等价,如无法声明Tim-Berns Lee和T.B.Lee是同一个人。
(3)不相交类的定义。 在 RDF(S)中只能声明子类关系,如男人和女人都是人的子类,但无法声明这两个类是不相交的。
(4)基数约束。 即对某属性值可能或必需的取值范围进行约束,如说明一个人有双亲(包括两个人),一门课至少有一名教师等。
(5)关于属性特性的描述。 即声明属性的某些特性,如传递性、函数性、对称性,以及声明一个属性是另一个属性的逆属性等,如大于关系的逆关系是小于关系。
为了得到一个表达能力更强的本体语言,W3C 提出了 OWL 语言扩展 RDF(S),作为在语义网上表示本体的推荐语言。W3C 于2002年7月31日发布了 OWL Web 本体语言(OWL Web Ontology Language)工作草案的细节,是为了更好地开发语义网。
1.OWL的语言特征
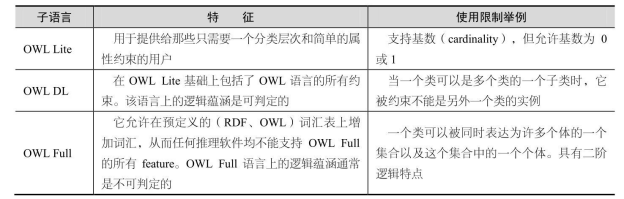
如图2-15所示,OWL1.0有 OWL Lite、OWL DL、OWL Full 三个子语言,三个子语言的特征和使用限制举例如表2-4所示。
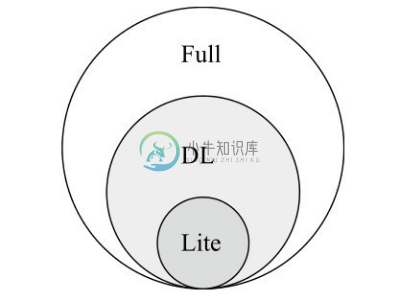
图2-15 OWL 1.0的主要子语言
表2-4 三个子语言的特征和使用限制举例
可以采用以下原则选择这些语言:
●选择OWL Lite还是OWL DL主要取决于用户需要整个语言在多大程度上给出约束的可表达性;
●选择OWL DL还是OWL Full主要取决于用户在多大程度上需要RDF的元模型机制,如定义类型的类型以及为类型赋予属性;
●当使用OWL Full而不是OWL DL时,推理的支持可能不能工作,因为目前还没有完全支持OWL Full的系统实现。
OWL 的子语言与 RDF 有以下关系。首先,OWL Full 可以看成是 RDF 的扩展;其次,OWL Lite 和 OWL Full 可以看成是一个约束化的 RDF 的扩展;再次,所有的 OWL文档(Lite、DL、Full)都是一个RDF文档,所有的RDF文档都是一个OWL Full文档;最后,只有一些RDF文档是一个合法的OWL Lite和OWL DL文档。
2.OWL的重要词汇
(1)等价性声明。声明两个类、属性和实例是等价的。如:
exp:运动员 owl:equivalentClass exp:体育选手
exp:获得 owl:equivalentProperty exp:取得
exp:运动员A owl:sameIndividualAs exp:小明
以上三个三元组分别声明了两个类、两个属性以及两个个体是等价的,exp 是命名空间 http://www.example.org 的别称,命名空间是唯一识别的一套名字,用来避免名字冲突,在OWL中可以是一个URL。
(2)属性传递性声明。声明一个属性是传递关系。例如,exp:ancestor rdf:type owl:TransitiveProperty 指的是 exp:ancestor 是一个传递关系。如果一个属性被声明为传递,则由 a exp:ancestor b 和 b exp:ancestor c 可以推出 a exp:ancestor c。例如 exp:小明exp:ancestor exp:小林;exp:小林 exp:ancestor exp:小志,根据上述声明,可以推出exp:小明exp:ancestor exp:小志。
(3)属性互逆声明。声明两个属性有互逆的关系。例如,exp:ancestor owl:inverseOf exp:descendant 指的是 exp:ancestor 和 exp:descendant 是互逆的。如果 exp:小明exp:ancestor exp:小林,根据上述声明,可以推出exp:小林 exp:descendant exp:小明。
(4)属性的函数性声明。声明一个属性是函数。例如,exp:hasMother rdf:type owl:FunctionalProperty指的是exp:hasMother是一个函数,即一个生物只能有一个母亲。
(5)属性的对称性声明。声明一个属性是对称的。例如 exp:friend rdf:type owl:SymmetricProperty 指的是 exp:friend 是一个具有对称性的属性;如果 exp:小明exp:friend exp:小林,根据上述声明,有exp:小林 exp:friend exp:小明。
(6)属性的全称限定声明。声明一个属性是全称限定。如:
exp:Person owl:allValuesFrom exp:Women
exp:Person owl:onProperty exp:hasMother
这个说明 exp:hasMother 在主语属于 exp:Person 类的条件下,宾语的取值只能来自exp:Women类。
(7)属性的存在限定声明。声明一个属性是存在限定。如:
exp:SemanticWebPaper owl:someValuesFrom exp:AAAI
exp:SemanticWebPaper owl:onProperty exp:publishedIn
这个说明exp:publishedIn在主语属于exp:SemanticWebPaper类的条件下,宾语的取值部分来自exp:AAAI类。上面的三元组相当于:关于语义网的论文部分发表在AAAI上。
(8)属性的基数限定声明。声明一个属性的基数。如:
exp:Person owl:cardinality “1”^^xsd:integer
exp:Person owl:onProperty exp:hasMother
指的是 exp:hasMother 在主语属于 exp:Person 类的条件下,宾语的取值只能有一个,“1”的数据类型被声明为xsd:integer,这是基数约束,本质上属于属性的局部约束。
(9)相交的类声明。声明一个类是等价于两个类相交。如:
exp:Mother owl:intersectionOf _tmp
_tmp rdf:type rdfs:Collection
_tmp rdfs:member exp:Person
_tmp rdfs:member exp:HasChildren
指_tmp 是临时资源,它是 rdfs:Collection 类型,是一个容器,它的两个成员是exp:Person 和 exp:HasChildren。上述三元组说明 exp:Mother 是 exp:Person 和exp:HasChildren两个类的交集。
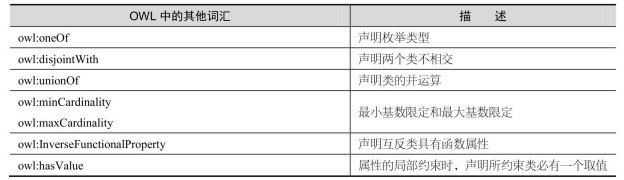
此外,OWL还有如表2-5所示词汇扩展。
表2-5 OWL词汇扩展
3.OWL版本
目前,OWL2 是OWL的最新版本,老的OWL版本也被称为OWL1。OWL2定义了一些 OWL 的子语言,通过限制语法使用,使得这些子语言能够更方便地实现,以及服务不同的应用。OWL2的三大子语言是OWL 2 RL、OWL 2 QL和OWL 2 EL。
OWL 2 QL是OWL2子语言中最为简单的,QL代表Query Language,所以OWL 2 QL 是专为基于本体的查询设计的。它的查询复杂度是 AC0 ,非常适合大规模处理。它是基于描述逻辑DL-Lite定义的。表2-6给出了OWL 2 QL词汇总结。
表2-6 OWL 2 QL词汇总结
另外一个能够提供多项式推理的OWL是OWL 2 EL。与OWL 2 QL不同,OWL 2 EL专为概念术语描述、本体的分类推理而设计,广泛应用在生物医疗领域,如临床医疗术语本体SNOMED CT。OWL 2 EL的分类复杂度是Ptime-Complete,它是基于描述逻辑语言EL++定义的。表2-7给出了OWL 2 QL词汇总结。
表2-7 OWL 2 QL词汇总结
例如,OWL 2 EL 允许表达如下复杂的概念:
Female ⊓ ∃likes.Movie ⊓ ∃hasSon.(Student ⊓ ∃attends.CSCourse)
指的是所有喜欢电影、儿子是学生且参加计算机课程的女性。
下面给出一个例子。假设有一个本体,包含以下公理:
公理1.Apple ⊑ ∃beInvestedBy.(Fidelity ⊓BlackStone):苹果由富达和黑石投资。
公理2.∃beFundedBy.Fidelity ⊑ InnovativeCompanies:借助富达融资的公司都是创新企业。
公理3.∃beFundedBy.BlackStone ⊑ InnovativeCompanies:借助黑石融资的公司都是创新企业。
公理4.beInvestedBy ⊑ beFundedBy:投资即是帮助融资。
由公理1可以推出公理5:Apple ⊑ ∃beInvestedBy.Fidelity;由公理5和公理4可以推出公理6:Apple ⊑ ∃beFundedBy.Fidelity;最后,由公理6和公理2可以推出公理7:Apple ⊑ InnovativeCompanies。
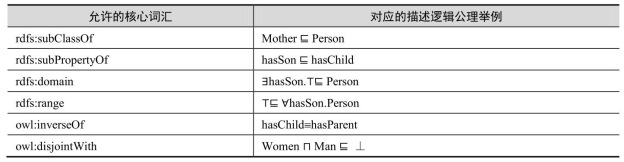
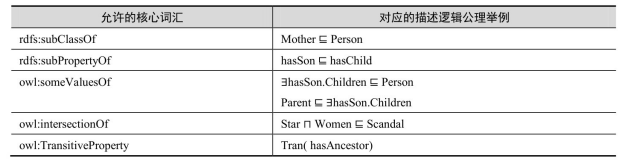
还有一个推理复杂度是多项式时间的OWL2子语言叫OWL 2 RL。OWL 2 RL扩展了RDFS 的表达能力,在 RDFS 的基础上引入属性的特殊特性(函数性、互反性和对称性),允许声明等价性,允许属性的局部约束。OWL 2 RL 的推理是一种前向链推理,即将推理规则应用到OWL 2 RL本体,得到新的知识,即OWL 2 RL推理是针对实例数据的推理。下面给出两个OWL 2 RL上的推理规则:
p rdfs:domain x, spo ⇒ s rdf:type x
p rdfs:range x, spo ⇒ o rdf:type x
其中,s、p、o、x 为变量。第一条规则表示如果属性 p 的定义域是类 x,而且实例 s和o有关系p(这里把属性与关系看成是一样的),那么实例s是类x的一个元素。第二条规则表示如果属性p的值域是类x,而且实例s和o有关系p,那么实例o是类x的一个元素。例如exp:hasChild rdfs:domain exp:Person, exp:Helen exp:hasChild exp:Jack,由第一条规则可以推出 exp:Helen rdf:type exp:Person。OWL 2 RL允许的核心词汇有:
●rdfs:subClassOf;
●rdfs:subPropertyOf;
●rdfs:domain;
●rdfs:range;
●owl:TransitiveProperty;
●owl:FunctionalProperty;
●owl:sameAs;
●owl:equivalentClass;
●owl:equivalentProperty;
●owl:someValuesFrom;
●owl:allValuesFrom。
OWL 2 RL的前向链推理复杂度是PTIME完备的,PTIME复杂度是针对实例数据推理得到的结果。
2.3.3 知识图谱查询语言的表示
RDF 支持类似数据库的查询语言,叫作 SPARQL [1] ,它提供了查询 RDF 数据的标准语法、处理SPARQL查询的规则以及结果返回形式。
1.SPARQL知识图谱查询基本构成
●变量,RDF中的资源,以“?”或者“$”指示;
●三元组模板,在WHERE子句中列出关联的三元组模板,之所以称为模板,因为三元组中允许存在变量;
●SELECT子句中指示要查询的目标变量。
下面是一个简单的SPARQL查询例子:

这个 SPARQL 查询指的是查询所有选修 CS328课程的学生,PREFIX 部分进行命名空间的声明,使得下面查询的书写更为简洁。
2.常见的SPARQL查询算子
(1)OPTIONAL。可选算子,指的是在这个算子覆盖范围的查询语句是可选的。例如:
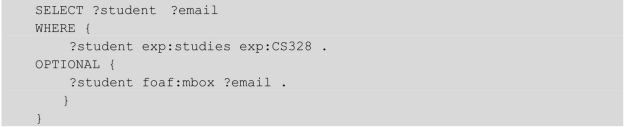
指的是查询所有选修 CS328课程的学生姓名,以及他们的邮箱。OPTIONAL 关键字指示如果没有邮箱,则依然返回学生姓名,邮箱处空缺。
(2)FILTER。过滤算子,指的是这个算子覆盖范围的查询语句可以用来过滤查询结果。例如:
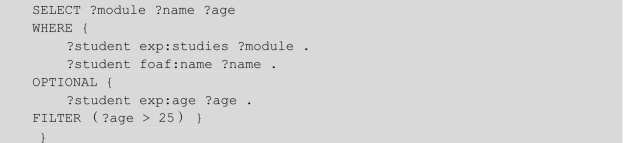
指的是查询学生姓名、选修课程以及他们的年龄;如果有年龄,则年龄必须大于25岁。
(3)UNION。并算子,指的是将两个查询的结果合并起来。例如:

指的是查询选修课程CS328或CS909的学生姓名以及邮件。注意,这里的邮件是必须返回的,如果没有邮件值,则不返回这条记录。需要注意UNION和OPTIONAL的区别。
下面给出一个SPARQL查询的例子。给定一个RDF数据集:


以及一个SPARQL查询:

这个SPARQL查询期望查询所有的收购关系,可以得到查询结果如表2-8所示。
表2-8 查询结果

给定论文一个SPARQL查询:

这个查询期望查询所有具备关联交易的公司。假设有下面两条规则:
hold_share(X, Y):- control(X, Y)
conn_trans(Y,Z):- hold_share(X, Y), hold_share(X, Z)
第一条规则指的是如果X控制了Y,那么X控股Y;第二条规则指的是如果X同时控股Y和Z,那么Y和Z具备关联交易。通过查询重写技术,可以得到下面的SPARQL查询:


但是这个查询比较复杂,可以通过下面的SPARQL查询简化:

在这个查询中,SPARQL允许嵌套查询,即WHERE子句中包含SELECT子句。
2.3.4 语义Markup表示语言
语义网进一步定义了在网页中嵌入语义 Markup 的方法和表示语言。被谷歌知识图谱以及 Schema.Org 采用的语义 Markup 语言主要包括 JSON-LD、RDFa 和 HTML5 MicroData。
1.JSON-LD
JSON-LD(JavaScript Object Notation for Linked Data)是一种基于JSON表示和传输链接数据的方法。JSON-LD 描述了如何通过 JSON 表示有向图,以及如何在一个文档中混合表示链接数据及非链接数据。JSON-LD 的语法和 JSON 兼容。JSON-LD 处理算法和API(JSON-LD Processing Algorithms and API)描述了处理JSON-LD数据所需的算法及编程接口,通过这些接口可以在 JavaScript、Python 及 Ruby 等编程环境中直接对 JSON-LD文档进行转换和处理。
下面是一个简单的JSON例子:

JSON 文档表示一个人。人们很容易推断这里的含义:“name”是人的名字,“homepage”是其主页,“image”是其某种照片。当然,机器不理解“name”和“image”这样的术语。JSON-LD 通过引入规范的术语表示,例如统一化表示“name”、“homepage”和“image”的URI,使得数据交换和机器理解成为基础。如下所示:

可以看出,JSON-LD 呈现出语义网技术的风格,它们有着类似的目标:围绕某类知识提供共享的术语。例如,每个数据集不应该围绕“name”重复发明概念。但是,JSON-LD的实现没有选择大部分语义网技术栈(TURTLE/SPARQL/Quad Stores),而是以简单、不复杂以及面向一般开发人员的方式推进。
2.RDFa
RDFa(Resource Description Framework in attributes)是一种早期网页语义标记语言。RDFa 也是 W3C 推荐标准。它扩充了 XHTML 的几个属性,网页制作者可以利用这些属性在网页中添加可供机器读取的资源。与RDF的对应关系使得RDFa可以将RDF的三元组嵌入在 XHTML 文档中,它也使得符合标准的使用端可以从 RDFa 文件中提取出这些RDF三元组。
RDFa 通过引入名字空间的方法,在已有的标签中加入 RDFa 相应的属性,以便解析支持RDFa技术的浏览器或者搜索引擎,从而达到优化的目的。

上面的代码示例中用到了RDFa 属性中的 about属性和 property属性。这段代码示例说明了一篇文章,然后描述了和这篇文章相关的信息,例如标题、创建者和创建日期,就可以让支持 RDFa 的机器识别这些属性。RDFa 可以从机器可理解的层面优化搜索,提升访问体验以及网页数据的关联。
3.HTML5 Microdata
Microdata(微数据)是在网页标记语言中嵌入机器可读的属性数据。微数据使用自定义词汇表、带作用域的键值对给 DOM 做标记,用户可以自定义微数据词汇表,在自己的网页中嵌入自定义的属性。微数据是给那些已经在页面上可见的数据施加额外的语义,当HTML的词汇不够用时,使用微数据可以取得较好的效果。下面是一个HTML5 Microdata的示例。

这个例子给出了Person类下一个叫Andy的人的照片和URL地址。
通过 HTML5 Microdata,浏览器可以很方便地从网页上提取微数据实体、属性及属性值。