
4.2 面向非结构化数据的知识抽取
大量的数据以非结构化数据(即自由文本)的形式存在,如新闻报道、科技文献和政府文件等,面向文本数据的知识抽取一直是广受关注的问题。在前文介绍的知识抽取领域的评测竞赛中,评测数据大多属于非结构化文本数据。本节将对这一类知识抽取技术和方法进行概要介绍,具体包括面向文本数据的实体抽取、关系抽取和事件抽取。
4.2.1 实体抽取
实体抽取又称命名实体识别,其目的是从文本中抽取实体信息元素,包括人名、组织机构名、地理位置、时间、日期、字符值和金额值等。实体抽取是解决很多自然语言处理问题的基础,也是知识抽取中最基本的任务。想要从文本中进行实体抽取,首先需要从文本中识别和定位实体,然后再将识别的实体分类到预定义的类别中去。例如,给定一段新闻报道中的句子“北京时间10月25日,骑士后来居上,在主场以119∶112击退公牛”。实体抽取旨在获取如图4-2所示的结果。例句中的“北京”“10月25日”分别为地点和时间类型的实体,而“骑士”和“公牛”均为组织实体。实体抽取问题的研究开展得比较早,该领域也积累了大量的方法。总体上,可以将已有的方法分为基于规则的方法、基于统计模型的方法和基于深度学习的方法。

图4-2 实体抽取举例
1.基于规则的方法
早期的命名实体识别方法主要采用人工编写规则的方式进行实体抽取。这类方法首先构建大量的实体抽取规则,一般由具有一定领域知识的专家手工构建。然后,将规则与文本字符串进行匹配,识别命名实体。这种实体抽取方式在小数据集上可以达到很高的准确率和召回率,但随着数据集的增大,规则集的构建周期变长,并且移植性较差。
2.基于统计模型的方法
基于统计模型的方法利用完全标注或部分标注的语料进行模型训练,主要采用的模型包括隐马尔可夫模型(Hidden Markov Model)、条件马尔可夫模型(Conditional Markov Model)、最大熵模型(Maximum Entropy Model)以及条件随机场模型(Conditional Random Fields)。该类方法将命名实体识别作为序列标注问题处理。与普通的分类问题相比,序列标注问题中当前标签的预测不仅与当前的输入特征相关,还与之前的预测标签相关,即预测标签序列是有强相互依赖关系的。从自然文本中识别实体是一个典型的序列标注问题。基于统计模型构建命名实体识别方法主要涉及训练语料标注、特征定义和模型训练三个方面。
(1)训练语料标注。为了构建统计模型的训练语料,人们一般采用 Inside–Outside–Beginning(IOB)或 Inside–Outside(IO)标注体系对文本进行人工标注。在 IOB 标注体系中,文本中的每个词被标记为实体名称的起始词(B)、实体名称的后续词(I)或实体名称的外部词(D)。而在IO标注体系中,文本中的词被标记为实体名称内部词(I)或实体名称外部词(D)。表4-1以句子“苹果公司是一家美国的跨国公司”为例,给出了IOB和IO实体标注示例。
表4-1 IOB和IO实体标注示例

(2)特征定义。在训练模型之前,统计模型需要计算每个词的一组特征作为模型的输入。这些特征具体包括单词级别特征、词典特征和文档级特征等。单词级别特征包括是否首字母大写、是否以句点结尾、是否包含数字、词性、词的 n-gram 等。词典特征依赖外部词典定义,例如预定义的词表、地名列表等。文档级特征基于整个语料文档集计算,例如文档集中的词频、同现词等。斯坦福大学的 NER[1] 是一个被广泛使用的命名实体识别工具,具有较高的准确率。Stanford NER 模型中定义的特征包括当前词、当前词的前一个词、当前词的后一个词、当前词的字符n-gram、当前词的词性、当前词上下文词性序列、当前词的词形、当前词上下文词形序列、当前词左侧窗口中的词(窗口大小为4)、当前词右侧窗口中的词(窗口大小为4)。定义何种特征对于命名实体识别结果有较大的影响,因此不同命名实体识别算法使用的特征有所不同。
(3)模型训练。隐马尔可夫模型(Hidden Markov Model,HMM)和条件随机场(Conditional Random Field,CRF)是两个常用于标注问题的统计学习模型,也被广泛应用于实体抽取问题。HMM 是一种有向图概率模型,模型中包含了隐藏的状态序列和可观察的观测序列。每个状态代表了一个可观察的事件,观察到的事件是状态的随机函数。HMM 模型结构如图4-3所示,每个圆圈代表一个随机变量,随机变量xt 是 t 时刻的隐藏状态;随机变量yt 是t时刻的观测值,图中的箭头表示条件依赖关系。 HMM模型有两个基本假设:
●在任意 t 时刻的状态只依赖于其前一时刻的状态,与其他观测及状态无关,即
P(xt |xt−1 ,xt−2 ,...,x1 ,yt−1 ,yt−2 ,...,y1 )=P(xt |xt−1 );
●任意时刻的观测只依赖于该时刻的马尔可夫链的状态,与其他观测及状态无关,即
P(yt |xt ,xt−1 ,xt−2 ,...,x1 ,yt−1 ,yt−2 ,...,y1 )=P(yt |xt )。
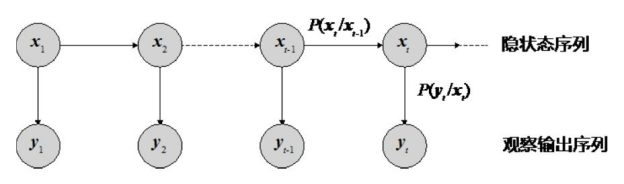
图4-3 HMM模型结构
在应用于命名实体识别问题时,HMM 模型中的状态对应词的标记,标注问题可以看作是对给定的观测序列进行序列标注。基于HMM的有代表性的命名实体识别方法可参考文献[2, 3]。
CRF是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型。在序列标注问题中,线性链 CRF 是常用的模型,其结构如图4-4所示。在序列标注问题中,状态序列变量x对应标记序列,y表示待标注的观测序列。
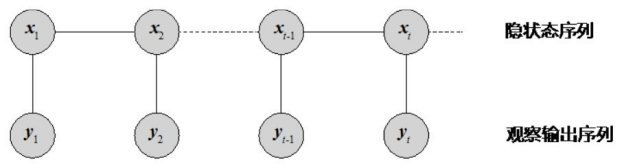
图4-4 线性链CRF模型结构
给定训练数据集,模型可以通过极大似然估计得到条件概率模型;当标注新数据时,给定输入序列 y,模型输出使条件概率P(x|y)最大化的x*。美国斯坦福大学开发的命名实体识别工具Stanford NER是基于CRF的代表性系统[1] 。
3.基于深度学习的方法
随着深度学习方法在自然语言处理领域的广泛应用,深度神经网络也被成功应用于命名实体识别问题,并取得了很好的效果。与传统统计模型相比,基于深度学习的方法直接以文本中词的向量为输入,通过神经网络实现端到端的命名实体识别,不再依赖人工定义的特征。目前,用于命名实体识别的神经网络主要有卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)以及引入注意力机制(Attention Mechanism)的神经网络。一般地,不同的神经网络结构在命名实体识别过程中扮演编码器的角色,它们基于初始输入以及词的上下文信息,得到每个词的新向量表示;最后再通过CRF模型输出对每个词的标注结果。
(1)LSTM-CRF 模型。图4-5展示了 LSTM-CRF 命名实体识别模型,是 Guillaume Lample等人2016年在NAACL-HLT会议论文中提出的[4] 。该模型使用了长短时记忆神经网络(Long Shot-Term Memory Neural Network,LSTM)与CRF相结合进行命名实体识别。该模型自底向上分别是Embedding层、双向LSTM层和CRF层。Embedding层是句子中词的向量表示,作为双向 LSTM 的输入,通过词向量学习模型获得。双向 LSTM 层通过一个正向 LSTM 和一个反向 LSTM,分别计算每个词考虑左侧和右侧词时对应的向量,然后将每个词的两个向量进行连接,形成词的向量输出;最后,CRF层以双向LSTM输出的向量作为输入,对句子中的命名实体进行序列标注。经过实验对比发现,双向LSTM 与 CRF 组合的模型在英文测试数据上取得了与传统统计方法最好结果相近的结果,而传统方法中使用了大量的人工定义的特征以及外部资源;在德语测试数据上,深度学习模型取得了比统计学习方法更优的结果。
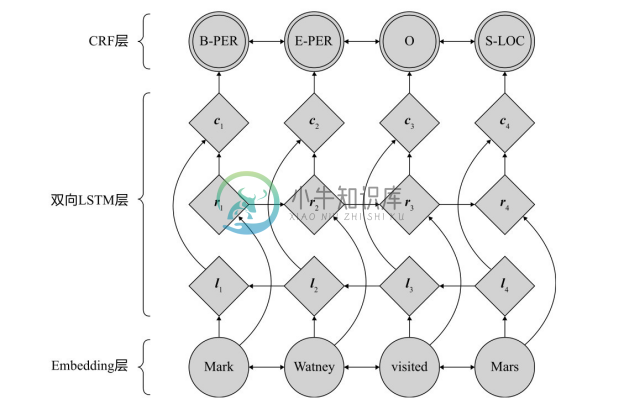
图4-5 LSTM-CRF命名实体识别模型[4]
(2)LSTM-CNNs-CRF模型。MA Xuezhe等人发表于ACL2016的论文提出了将双向LSTM、CNN 和 CRF 相结合的序列标注模型[5] ,并成功地应用于命名实体识别问题中。该模型与 LSTM-CRF 模型十分相似,不同之处是在 Embedding 层中加入了每个词的字符级向量表示。图4-6展示了获取词语字符级向量表示的 CNN 模型,该模型可以有效地获取词的形态信息,如前缀、后缀等。模型Embedding层中每个词的向量输入由预训练获得的词向量和 CNN 获得的字符级向量连接而成,通过双向 LSTM 和 CRF 层获得词的标注结果。LSTM-CNNs-CRF序列标注模型框架如图4-7所示。在CoNLL-2003命名实体识别数据集上,该模型获得了91.2%的F1值。
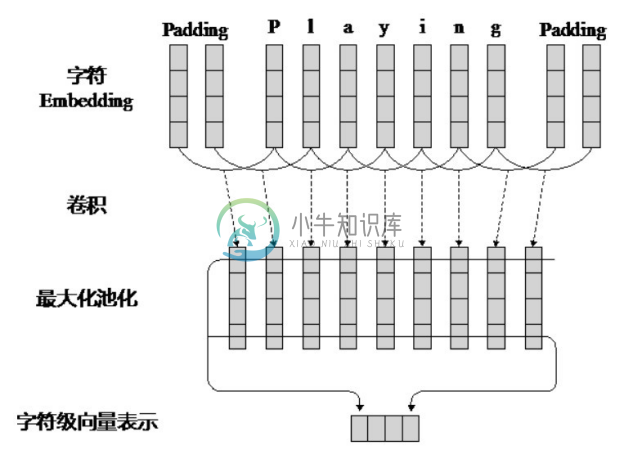
图4-6 获取词语字符级向量表示的CNN模型[5]
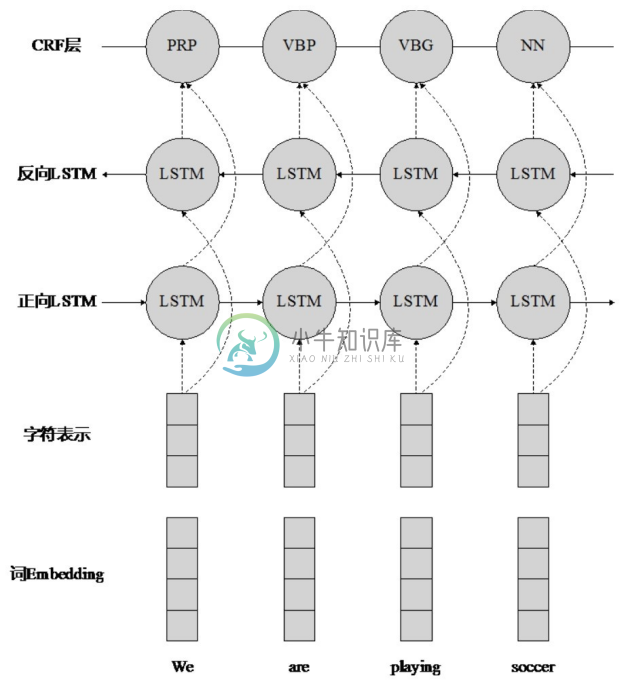
图4-7 LSTM-CNNs-CRF序列标注模型框架[5]
(3)基于注意力机制的神经网络模型。在自然语言处理领域,基于注意力机制的神经网络模型最早应用于解决机器翻译问题,注意力机制可以帮助扩展基本的编码器-解码器模型结构,让模型能够获取输入序列中与下一个目标词相关的信息。在命名实体识别问题方面,Marek Rei等人在COLING2016的论文中提出了基于注意力机制的词向量和字符级向量组合方法[6] 。该方法认为除了将词作为句子基本元素学习得到的特征向量,命名实体识别还需要词中的字符级信息。因此,该方法除了使用双向 LSTM 得到词的特征向量,还基于双向LSTM计算词的字符级特征向量。图4-8展示了基于注意力机制的词向量和字符级向量的组合方法。假设输入词为“big”,该方法将词中的字符看作一个序列,然后通过正、反向的 LSTM 计算字符序列的最终状态![]() 和
和![]() ,两者相连得到词“big”的字符级向量h∗ 。h∗ 通过一个非线性层得到m之后,与“big”的词向量x进行加权相加,而两者相加的权重z是通过一个两层的神经网络计算获得的。在得到句子中每个词的新向量
,两者相连得到词“big”的字符级向量h∗ 。h∗ 通过一个非线性层得到m之后,与“big”的词向量x进行加权相加,而两者相加的权重z是通过一个两层的神经网络计算获得的。在得到句子中每个词的新向量![]() 之后,模型使用 CRF 对句子中的命名实体进行序列标注。注意力机制的引入使得模型可以动态地确定每个词的词向量和字符级向量在最终特征中的重要性,有效地提升了命名识别的效果。与基于词向量和字符级向量拼接的方法相比,基于注意力机制的方法在八个数据集上都获得了最好的实验结果。
之后,模型使用 CRF 对句子中的命名实体进行序列标注。注意力机制的引入使得模型可以动态地确定每个词的词向量和字符级向量在最终特征中的重要性,有效地提升了命名识别的效果。与基于词向量和字符级向量拼接的方法相比,基于注意力机制的方法在八个数据集上都获得了最好的实验结果。
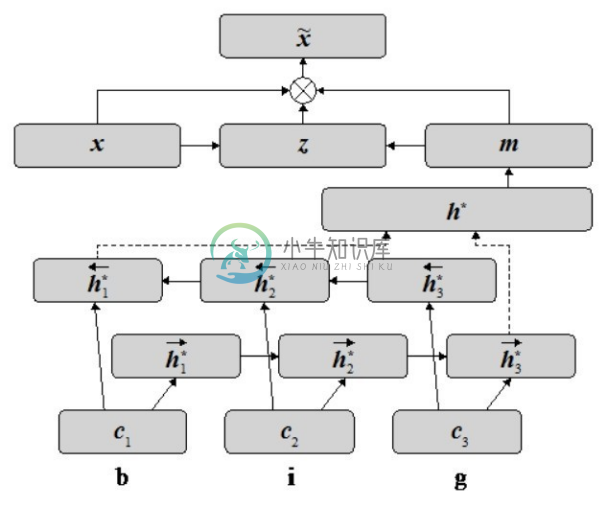
图4-8 基于注意力机制的词向量和字符级向量组合方法[6]
4.2.2 关系抽取
关系抽取是知识抽取的重要子任务之一,面向非结构化文本数据,关系抽取是从文本中抽取出两个或者多个实体之间的语义关系。关系抽取与实体抽取密切相关,一般在识别出文本中的实体后,再抽取实体之间可能存在的关系。目前,关系抽取方法可以分为基于模板的关系抽取方法、基于监督学习的关系抽取方法和基于弱监督学习的关系抽取方法。
1.基于模板的关系抽取方法
早期的实体关系抽取方法大多基于模板匹配实现。该类方法基于语言学知识,结合语料的特点,由领域专家手工编写模板,从文本中匹配具有特定关系的实体。在小规模、限定领域的实体关系抽取问题上,基于模板的方法能够取得较好的效果。
假设想从文本中自动抽取具有“夫妻”关系的实体,并且观察到包含“夫妻”关系的例句。
●例句1:[姚明]与妻子[叶莉]还有女儿姚沁蕾并排坐在景区的游览车上,画面十分温馨
●例句2:[徐峥]老婆[陶虹]晒新写真
可以简单地将上述句子中的实体替换为变量,从而得到如下能够获取“夫妻”关系的模板:
●模板1:[X]与妻子[Y] ……
●模板2:[X]老婆[Y] ……
利用上述模板在文本中进行匹配,可以获得新的具有“夫妻”关系的实体。为了进一步提高模板匹配的准确率,还可以将句法分析的结果加入模板中。
基于模板的关系抽取方法的优点是模板构建简单,可以比较快地在小规模数据集上实现关系抽取系统。但是,当数据规模较大时,手工构建模板需要耗费领域专家大量的时间。此外,基于模板的关系抽取系统可移植性较差,当面临另一个领域的关系抽取问题时,需要重新构建模板。最后,由于手工构建的模板数量有限,模板覆盖的范围不够,基于模板的关系抽取系统召回率普遍不高。
2.基于监督学习的关系抽取方法
基于监督学习的关系抽取方法将关系抽取转化为分类问题,在大量标注数据的基础上,训练有监督学习模型进行关系抽取。利用监督学习方法进行关系抽取的一般步骤包括:预定义关系的类型;人工标注数据;设计关系识别所需的特征,一般根据实体所在句子的上下文计算获得;选择分类模型(如支持向量机、神经网络和朴素贝叶斯等),基于标注数据训练模型;对训练的模型进行评估。
在上述步骤中,关系抽取特征的定义对于抽取的结果具有较大的影响,因此大量的研究工作围绕关系抽取特征的设计展开。根据计算特征的复杂性,可以将常用的特征分为轻量级、中等量级和重量级三大类。轻量级特征主要是基于实体和词的特征,例如句子中实体前后的词、实体的类型以及实体之间的距离等。中等量级特征主要是基于句子中语块序列的特征。重量级特征一般包括实体间的依存关系路径、实体间依存树结构的距离以及其他特定的结构信息。
例如,对于句子“Forward [motion] of the vehicle through the air caused a [suction] on the road draft tube”,轻量级的特征可以是实体[motion]和[suction]、实体间的词{of,the,vehicle,through,the,air,caused,a}等;重量级的特征可以包括依存树中的路径“caused→nsubj→实体1”“caused→dobj→实体2”等。
传统的基于监督学习的关系抽取是一种依赖特征工程的方法,近年来有多个基于深度学习的关系抽取模型被研究者们提出。深度学习的方法不需要人工构建各种特征,其输入一般只包括句子中的词及其位置的向量表示。目前,已有的基于深度学习的关系抽取方法主要包括流水线方法和联合抽取方法两大类。流水线方法将识别实体和关系抽取作为两个分离的过程进行处理,两者不会相互影响;关系抽取在实体抽取结果的基础上进行,因此关系抽取的结果也依赖于实体抽取的结果。联合抽取方法将实体抽取和关系抽取相结合,在统一的模型中共同优化;联合抽取方法可以避免流水线方法存在的错误积累问题。
(1)基于深度学习的流水线关系抽取方法
●CR-CNN 模型[7] 。图4-9展示了一个典型的基于神经网络的流水线关系抽取方法CR-CNN模型。给定输入的句子,CR-CNN模型首先将句子中的词映射到长度为dw 的低维向量,每个词的向量包含了词向量和位置向量两部分。然后,模型对固定大小滑动窗口中的词的向量进行卷积操作,为每个窗口生成新的长度为 dc 的特征向量;对所有的窗口特征向量求最大值,模型最终得到整个句子的向量表示dx 。在进行关系分类时,CR-CNN 模型计算句子向量和每个关系类型向量的点积,得到实体具有每种预定义关系的分值。CR-CNN模型在SemEval-2010 Task 8数据集上获得了84.1%的F1值,这个结果优于当时最好的非深度学习方法。
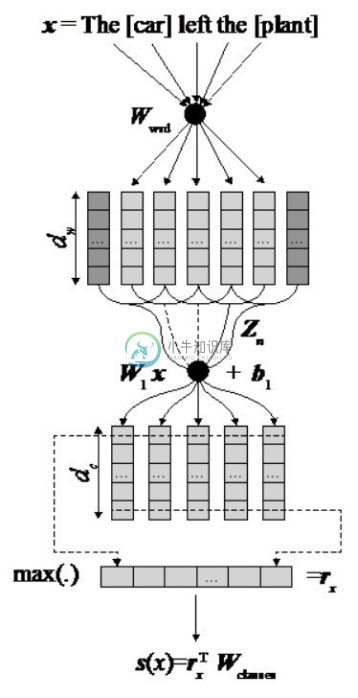
图4-9 CR-CNN模型[7]
●Attention CNNs 模型[8] 。Wang 等人提出的多层注意力卷积神经网络(Multi-level Attention CNN),将注意力机制引入到神经网络中,对反映实体关系更重要的词语赋予更大的权重,借助改进后的目标函数提高关系提取的效果。其模型的结构如图4-10所示,在输入层,模型引入了词与实体相关的注意力,同时还在池化和混合层引入了针对目标关系类别的注意力。在 SemEval-2010 Task 8数据集上,该模型获得了88%的F1值。
●Attention BLSTM 模型[9] 。Attention BLSTM 模型如图4-11所示,它包含两个LSTM 网络,从正向和反向处理输入的句子,从而得到每个词考虑左边和右边序列背景的状态向量;词的两个状态向量通过元素级求和产生词的向量表示。在双向 LSTM 产生的词向量基础上,该模型通过注意力层组合词的向量产生句子向量,进而基于句子向量将关系分类。注意力层首先计算每个状态向量的权重,然后计算所有状态向量的加权和得到句子的向量表示。实验结果表明,增加注意力层可以有效地提升关系分类的结果。
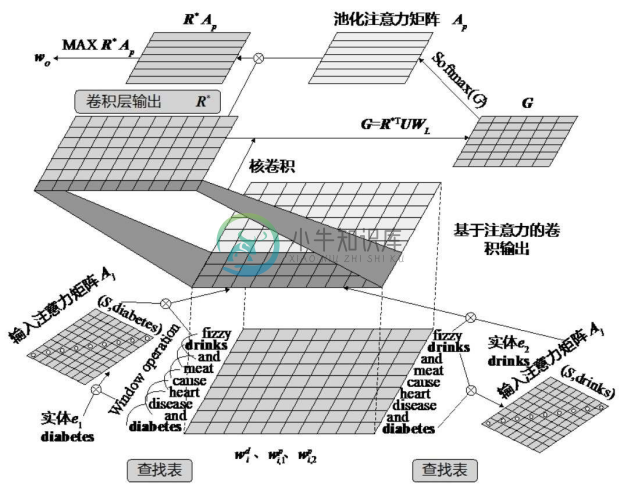
图4-10 Attention CNNs模型的结构[8]
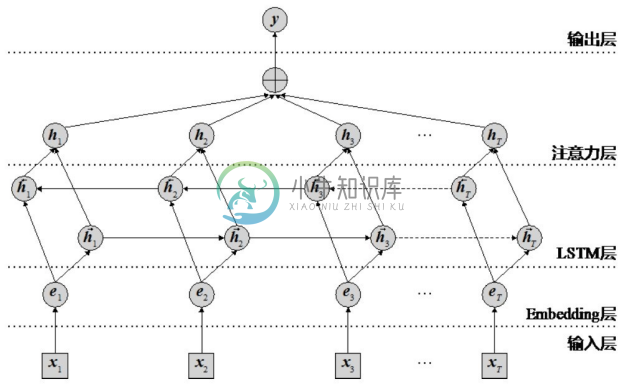
图4-11 Attention BLSTM模型[9]
在关系抽取问题方面,还有许多其他属于流水线方法的深度学习模型。图4-12列出了一些具有代表性的流水线方法在 SemEval-2010 Task 8数据集上的结果对比(Att-BLSTM[9] , Att-Pooling-CNN[8] , depLCNN+NS[ 10 ] , DepNN[ 11 ] , CR-CNN[7] , CNN+Softmax[12] )。
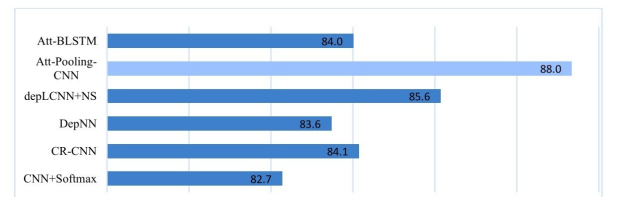
图4-12 关系抽取模型在SemEval-2010 Task 8数据集F1值对比(%)
(2)基于深度学习的联合关系抽取方法。在流水线关系抽取方法中,实体抽取和关系抽取两个过程是分离的。联合关系抽取方法则是将实体抽取和关系抽取相结合,图4-13展示的是一个实体抽取和关系抽取的联合模型[13] 。该模型主要由三个表示层组成:词嵌入层(嵌入层)、基于单词序列的 LSTM-RNN 层(序列层)以及基于依赖性子树的 LSTM-RNN 层(依存关系层)。在解码过程中,模型在序列层上构建从左到右的实体识别,并实现依存关系层上的关系分类,其中每个基于子树的 LSTM-RNN 对应于两个被识别实体之间的候选关系。在对整个模型结构进行解码之后,模型参数通过基于时间的反向传播进行更新。在依存关系层堆叠在序列层上,因此嵌入层和序列层被实体识别和关系分类任务共享,共享参数受实体和关系标签的共同影响。该联合模型在 SemEval-2010 Task 8数据集上获得了84.4%的F1值;将WordNet作为外部知识后,该模型可以获得85.6%的F1值。
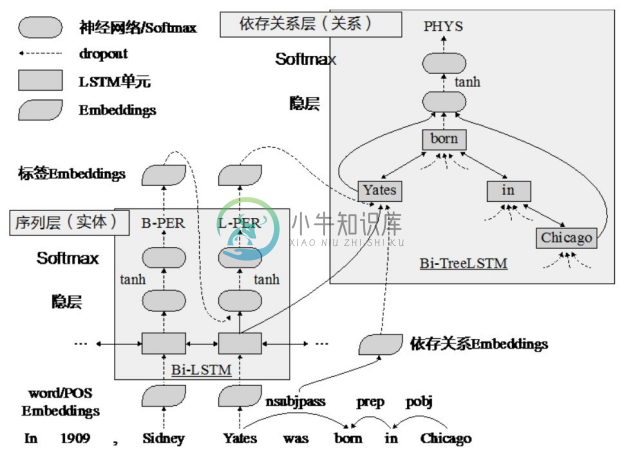
图4-13 实体抽取和关系抽取的联合模型[13]
3.基于弱监督学习的关系抽取方法
基于监督学习的关系抽取方法需要大量的训练语料,特别是基于深度学习的方法,模型的优化更依赖大量的训练数据。当训练语料不足时,弱监督学习方法可以只利用少量的标注数据进行模型学习。基于弱监督学习的关系抽取方法主要包括远程监督方法和Bootstrapping方法。
(1)远程监督方法。远程监督方法通过将知识图谱与非结构化文本对齐的方式自动构建大量的训练数据,减少模型对人工标注数据的依赖,增强模型的跨领域适应能力。远程监督方法的基本假设是如果两个实体在知识图谱中存在某种关系,则包含两个实体的句子均表达了这种关系。例如,在某知识图谱中存在实体关系创始人(乔布斯,苹果公司),则包含实体乔布斯和苹果公司的句子“乔布斯是苹果公司的联合创始人和 CEO”则可被用作关系创始人的训练正例。因此,远程监督关系抽取方法的一般步骤为:
●从知识图谱中抽取存在目标关系的实体对;
●从非结构化文本中抽取含有实体对的句子作为训练样例;
●训练监督学习模型进行关系抽取。
远程监督关系抽取方法可以利用丰富的知识图谱信息获取训练数据,有效地减少了人工标注的工作量。但是,基于远程监督的假设,大量噪声会被引入到训练数据中,从而引发语义漂移的现象。
为了改进远程监督实体关系抽取方法,一些研究围绕如何克服训练数据中的噪声问题展开。最近,多示例学习、采用注意力机制的深度学习模型以及强化学习等模型被用来解决样例错误标注的问题,取得了较好的效果。下面介绍两个具有代表性的模型。
Guoliang Ji等人在发表于AAAI2017的论文中提出了基于句子级注意力和实体描述的神经网络关系抽取模型 APCNNs[14] 。模型结构如图4-14所示,图4-14(a)是 PCNNs (Piecewise Convolutional Neural Networks)模型,用于提取单一句子的特征向量;其输入是词向量和位置向量,通过卷积和池化操作,得到句子的向量表示。图4-14(b)展示的是句子级注意力模型,该模型是克服远程监督训练噪声的关键;该模型以同一关系的所有样例句子的向量作为输入,学习获得每个句子的权重,最后通过加权求和得到所有句子组成的包特征(bag features)。关系的分类是基于包特征上的 Softmax 分类器实现的。APCNNs 模型实际采用了多示例学习的策略,将同一关系的样例句子组成样例包,关系分类是基于样例包的特征进行的。实验结果表明,该模型可以有效地提高远程监督关系抽取的准确率。
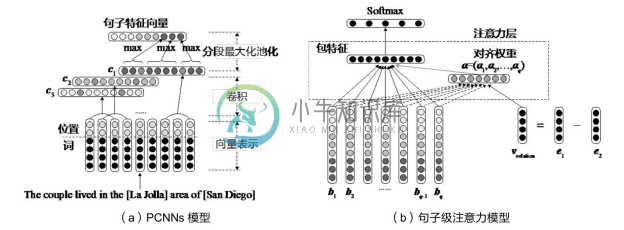
图4-14 APCNNs模型[14]
在采用多示例学习策略时,有可能出现整个样例包都包含大量噪声的情况。针对这一问题,Jun Feng等人提出了基于强化学习的关系分类模型CNN-RL[15] 。CNN-RL模型框架如图4-15所示,模型有两个重要模块:样例选择器和关系分类器。样例选择器负责从样例包中选择高质量的句子,然后由关系分类器从句子级特征对关系进行分类。整个模型采用强化学习的方式,样例选择器基于一个随机策略,在考虑当前句子的选择状态情况下选择样例句子;关系分类器利用卷积神经网络对句子中的实体关系进行分类,并向样例选择器反馈,帮助其改进样例选择策略。在实验对比中,该模型获得了比句子级卷积神经网络和样例包级关系分类模型更好的结果。
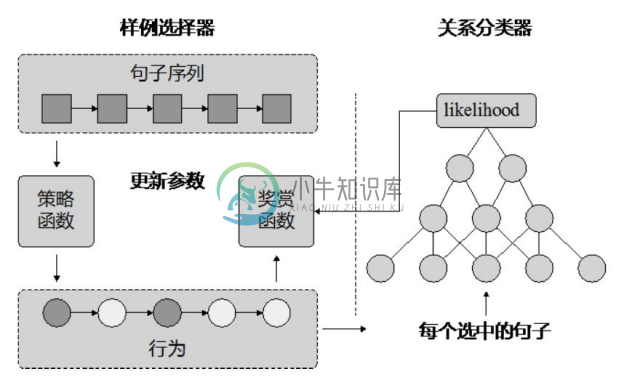
图4-15 CNN-RL模型[15]
(2)Bootstrapping 方法。Bootstrapping 方法利用少量的实例作为初始种子集合,然后在种子集合上学习获得关系抽取的模板,再利用模板抽取更多的实例,加入种子集合中。通过不断地迭代,Bootstrapping方法可以从文本中抽取关系的大量实例。
有很多实体关系抽取系统都采用了Bootstrapping方法。Brin等人[16] 构建的DIPER利用少量实体对作为种子,从 Web 上大量非结构化文本中抽取新的实例,同时学习新的抽取模板,迭代地获取实体关系,是较早使用 Bootstrapping 方法的系统。Agichtein 等人[17] 设计实现了 Snowball 关系抽取系统,该系统在 DIPER 系统基础上提出了模板生成和关系抽取的新策略。在关系抽取过程中,Snowball 可以自动评价新实例的可信度,并保留最可靠的实例加入种子集合。Etzioni 等人[18] 构建了 KnowItAll 抽取系统,从 Web 文本中抽取非特定领域的事实信息,该系统关系抽取的准确率能达到90%。此后,一些基于Bootstrapping 的系统加入了更合理的模板描述、限制条件和评分策略,进一步提高了关系抽取的准确率。例如 NELL 系统[19] ,它以初始本体和少量种子作为输入,从大规模的Web文本中学习,并对学习到的内容进行打分来提升系统性能。
Bootstrapping 方法的优点是关系抽取系统构建成本低,适合大规模的关系抽取任务,并且具备发现新关系的能力。但是,Bootstrapping 方法也存在不足之处,包括对初始种子较为敏感、存在语义漂移问题、结果准确率较低等。
4.2.3 事件抽取
事件是指发生的事情,通常具有时间、地点、参与者等属性。事件的发生可能是因为一个动作的产生或者系统状态的改变。事件抽取是指从自然语言文本中抽取出用户感兴趣的事件信息,并以结构化的形式呈现出来,例如事件发生的时间、地点、发生原因、参与者等。图4-16给出了一个事件抽取的例子。基于一段苹果公司举办产品发布会的新闻报道,可以通过事件抽取方法自动获取报道事件的结构化信息,包括事件类型、涉及公司、发生时间及地点、所发布的产品。
一般地,事件抽取任务包含的子任务有:
●识别事件触发词及事件类型;
●抽取事件元素的同时判断其角色;
●抽出描述事件的词组或句子;
●事件属性标注;
●事件共指消解。
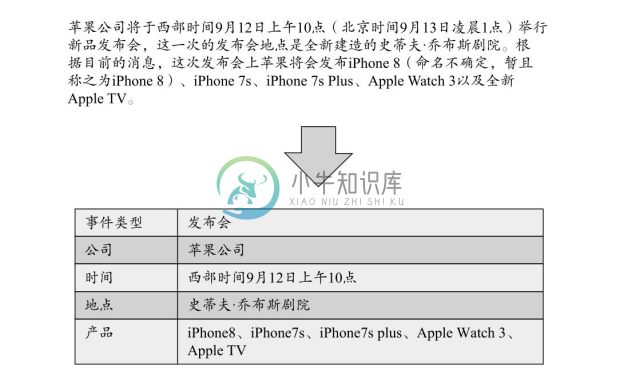
图4-16 事件抽取示例
已有的事件抽取方法可以分为流水线方法和联合抽取方法两大类。
1.事件抽取的流水线方法
流水线方法将事件抽取任务分解为一系列基于分类的子任务,包括事件识别、元素抽取、属性分类和可报告性判别;每一个子任务由一个机器学习分类器负责实施。一个基本的事件抽取流水线需要的分类器包括:
(1)事件触发词分类器。判断词汇是否为事件触发词,并基于触发词信息对事件类别进行分类。
(2)元素分类器。判断词组是否为事件的元素。
(3)元素角色分类器。判定事件元素的角色类别。
(4)属性分类器。判定事件的属性。
(5)可报告性分类器。判定是否存在值得报告的事件实例。
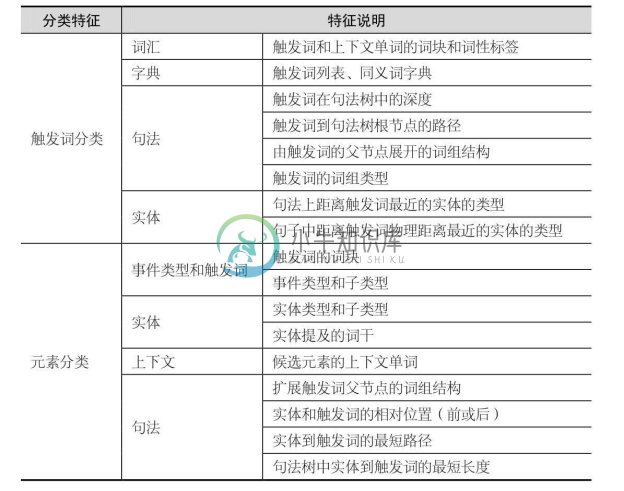
表4-2列出了在事件抽取过程中,触发词分类和元素分类常用的分类特征。各个阶段的分类器可以采用机器学习算法中的不同分类器,例如最大熵模型、支持向量机等。
表4-2 触发词分类和元素分类常用的分类特征
2.事件的联合抽取方法
事件抽取的流水线方法在每个子任务阶段都有可能存在误差,这种误差会从前面的环节逐步传播到后面的环节,从而导致误差不断累积,使得事件抽取的性能急剧衰减。为了解决这一问题,一些研究工作提出了事件的联合抽取方法。在联合抽取方法中,事件的所有相关信息会通过一个模型同时抽取出来。一般地,联合事件抽取方法可以采用联合推断或联合建模的方法,如图4-17所示。联合推断方法首先建立事件抽取子任务的模型,然后将各个模型的目标函数进行组合,形成联合推断的目标函数;通过对联合目标函数进行优化,获得事件抽取各个子任务的结果。联合建模的方法在充分分析子任务间的关系后,基于概率图模型进行联合建模,获得事件抽取的总体结果。
具有代表性的联合建模方法是Qi Li等人在ACL2013论文中提出的联合事件抽取模型[20] 。该模型将事件触发词、元素抽取的局部特征和捕获任务之间关联的结构特征结合进行事件抽取。在图4-18所示的事件触发词和事件元素示例中,“fired”是袭击(Attack)事件的触发词,但是由于该词本身具有歧义性,流水线方法中的局部分类器很容易将其错误分类;但是,如果考虑到“tank”很可能是袭击事件的工具(Instrument)元素,那么就比较容易判断“fired”触发的是袭击事件。此外,在流水线方法中,局部的分类器也不能捕获“fired”和“died”之间的依赖关系。为了克服局部分类器的不足,新的联合抽取模型在使用大量局部特征的基础上,增加了若干全局特征。例如,在图4-18的句子中,事件死亡(Die)和事件(Attack)的提及“died”和“fired”共享了三个参数;基于这种情况,可以定义形如图4-19所示的事件抽取全局特征。这类全局特征可以从整体的结构中学习得到,从而使用全局的信息来提升局部的预测。联合抽取模型将事件抽取问题转换成结构预测问题,并使用集束搜索方法进行求解。
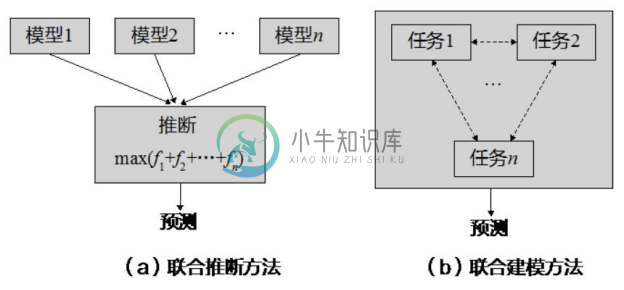
图4-17 联合事件抽取方法
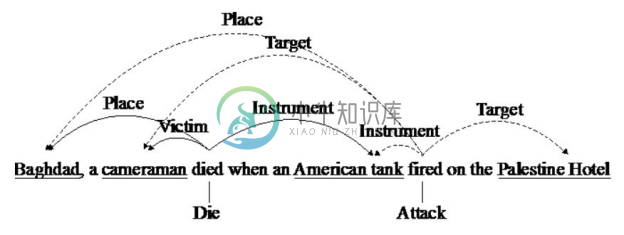
图4-18 事件触发词和事件元素示例
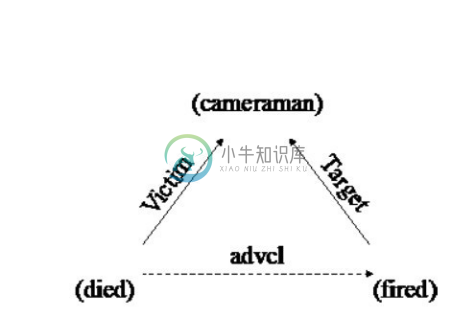
图4-19 事件抽取全局特征
在事件抽取任务上,同样有一些基于深度学习的方法被提出。传统的事件抽取方法通常需要借助外部的自然语言处理工具和大量的人工设计的特征;与之相比,深度学习方法具有以下优势:
●减少了对外部工具的依赖,甚至不依赖外部工具,可以构建端到端的系统;
●使用词向量作为输入,词向量蕴涵了丰富的语义信息;
●神经网络具有自动提取句子特征的能力,避免了人工设计特征的烦琐工作。
图4-20展示了一个基于动态多池化卷积神经网络的事件抽取模型。该模型由 Yubo Chen 等人于2015年发表在 ACL 会议上[21] 。模型总体包含词向量学习、词汇级特征抽取、句子级特征抽取和分类器输出四个部分。其中,词向量学习通过无监督方式学习词的向量表示;词汇级特征抽取基于词的向量表示获取事件抽取相关的词汇线索;句子级特征抽取通过动态多池化卷积神经网络获取句子的语义组合特征;分类器输出产生事件元素的角色类别。在 ACE2005英文数据集上的实验表明,该模型获得了优于传统方法和其他CNN方法的结果。
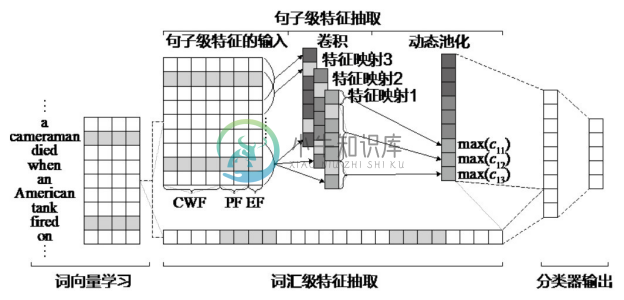
图4-20 基于动态多池化卷积神经网络的事件抽取模型