
8.3 知识问答系统
8.3.1 NLIDB:早期的问答系统
20世纪六七十年代,早期的NLIDB(Natural Language Interface to Data Base)伴随着人工智能的研发逐步兴起[22] ,以1961年的 BASEBALL 系统[4] 和1972年的 LUNAR 系统[5] (Woods 1973)为代表。BASEBALL 系统回答了有关一年内棒球比赛的问题。LUNAR 在阿波罗月球任务期间提供了岩石样本分析数据的界面。这些系统一般限定在特定领域,使用自然语言问题询问结构化知识库。这些数据库与如今讲的关系数据库不同,更像基于逻辑表达式的知识库。这一类系统通常为领域应用定制,将领域问题语义处理逻辑(自然语言问题转化为结构化数据查询)硬编码为特定的语法解析规则(例如模板或者简单的语法树),同时手工构建特定领域的词汇表,形成语法解析规则,很难转移到其他的应用领域。如图8-10所示为早期NLIDB型问答系统的设计思想。
依据文献[23]的介绍,NLIDB 系统大多采用的模块包括:①实体识别(Named Entity Recognition),通过查询领域词典识别命名实体;②语义理解(Question2Query),利用语法解析(例如词性分析,Part-Of-Speech)、动词分析(包括主动和被动)以及语义映射规则等技术,将问题解析成语义查询语句;③回答问题(Answer Processing),通常通过简单查询和其他复杂操作(例如 Count)获取答案。这些工作中的语义理解部分各具特色,也就此奠定了后续问答系统中问题解析的基本套路,下面详细举例说明。

图8-10 早期NLIDB型问答系统的设计思想
(1)基于模式匹配(Pattern-Matching)。基于模式匹配的语义理解可以直接将问题映射到查询。如图8-11所示,例子“...capital...<country>.....”中,变量“<country>”用来表示 Country 类型的一个实体,例如 Italy,而“capital”是一个字符串。这个模板可以匹配不同的自然语言说法,例如“What is the capital of Italy?”“Could you please tell me what is the capital of Italy?”,然后将问题映射到查询“Report Capital of row where Country = Italy”(查询意大利的首都)。这种语义理解技术简便灵活且不依赖过多的语法分析工具,后来发展为KBQA中基于模板的语义理解方案。

图8-11 基于模板匹配的NLIDB解决方案[23]
(2)基于语法解析(Syntactic-Parsing)。基于语法解析的语义理解将自然语言的复杂语义转化为逻辑表达式。如图8-12所示为展示了 LUNAR 系统利用语法树解析初步解析问题。句法分析器的树状结果仍然需要人工生成的语义规则和领域知识来理解,进而转化成一种中间层的逻辑表达式。通过一个简单的基于 Context-Free Grammar(CFG)的语法,主语(S)由一个名词短语(NP)加上一个动词短语(VP)组成;一个名词短语(NP)由一个确定词(Det)和一个名词(N)组成;确定词(Det)可以是“what”或“which”等。这样,“which rock contains magnesium”就可以解析为后面的语法分析结果,进而通过一系列转换规则,例如“which”映射到 for_every X,“rock”映射到(is rock X),形成最终的数据库查询。不少后来的系统也在系统的可移植性上有一些进展,包括允许为某一个新领域重新定制词典,构建通用知识表示语言来表达语义规则。有些系统甚至还可以允许用户通过交互界面添加新词汇和映射规制,包括 LUNAR系统后期提出的 MRL 语言[23] ,将自然语言问题转化为一种基于中间表示语言的逻辑查询表达式。这种中间表示语言承载了高层次世界概念以及用户问题的含义,独立于数据库存储结构,可以进一步转换成数据查询的表达式从而获取答案。这一类方案后来演进为 KBQA 中基于语义解析(Semantic Parsing)的语义理解方法。语法树分析为处理更为复杂的问题以及简单问题的语法变形提供了便利,但是这也同时依赖语法分析工具的正确性(包括词性分析、语法依存分析)。另外,当词汇具有多重词性时,也存在潜在问题。所以,还需要附加一些规则调整语法解析出来的查询。
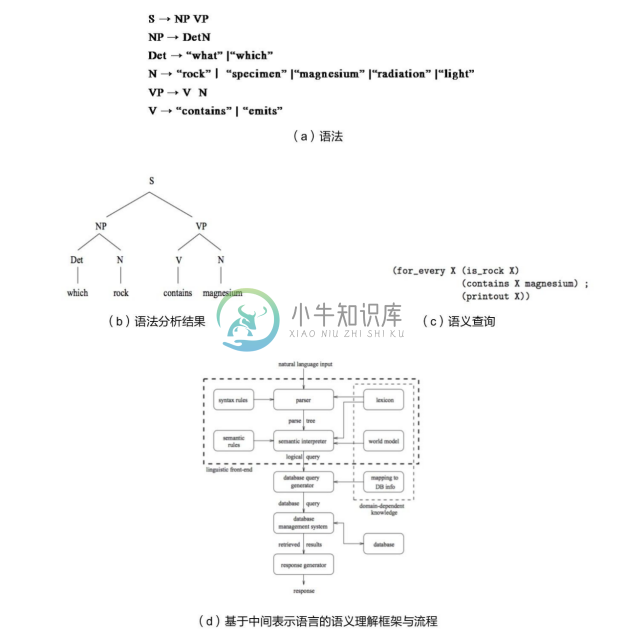
图8-12 LUNAR系统利用语法树解析初步解析问题[23]
8.3.2 IRQA:基于信息检索的问答系统
基于信息检索的问答系统(Information Retrieval based Question-Answering System, IRQA)[6] 的核心思想是根据用户输入的问题,结合自然语言处理以及信息检索技术,在给定文档集合或者互联网网页中筛选出相关的文档,从结果文档内容抽取关键文本作为候选答案,最后对候选答案进行排序返回最优答案。如图8-13所示,参考斯坦福 IRQA 的基本架构[13] ,问答流程大致分三个阶段:
(1)问题处理(Question Processing)。从不同角度理解问题的语义,明确知识检索的过滤条件(Query Formulation,即问句转化为关键词搜索)和答案类型判定(Answer Type Detection,例如“谁发现了万有引力?”需要返回人物类实体;“中国哪个城市人口数最多?”需要返回城市类实体)。
(2)段落检索与排序(Passage Retrieval And Ranking)。基于提取出的关键词进行信息检索,对检索出的文档进行排序,把排序之后的文档分割成合适的段落,并对新的段落进行再排序,找到最优答案。
(3)答案处理(Answer Processing)。最后根据排序后的段落,结合问题处理阶段定义的答案类型抽取答案,形成答案候选集;最终对答案候选集排序,返回最优解。此方法以文档为知识库,没有预先的知识抽取工作。
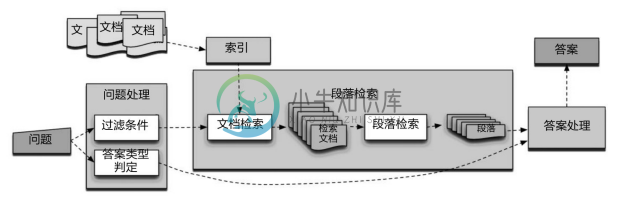
图8-13 IRQA的基本架构 [13]
8.3.3 KBQA:基于知识库的问答系统
基于知识库的问答系统(Knowledge-Based Question Answering,KBQA)特指使用基于知识图谱解答问题的问答系统。KBQA 实际上是20世纪七八十年代对 NLIDB 工作的延续,其中很多技术都借鉴和沿用了以前的研究成果。其中,主要的差异是采用了相对统一的基于 RDF 表示的知识图谱,并且把语义理解的结果映射到知识图谱的本体后生成SPARQL 查询解答问题。通过本体可以将用户问题映射到基于概念拓扑图表示的查询表达式,也就对应了知识图谱中某种子图。KBQA 的核心问题 Question2Query 是找到从用户问题到知识图谱子图的最合理映射。
QALD(Question Answering on Linked Data)[38] 是2011年开始针对KBQA问答系统的评测活动。文献[14]分析了参与QALD 的数十个问答系统,并从问题解析、词汇关联、歧义消解、构建查询以及分布式知识库五个阶段做了对比,而前四个问题都是Question2Query的关键步骤。
(1)问题分析。主要利用词典、词性分析、分词、实体识别、语法解析树分析、句法依存关系分析等传统 NLP 技术提取问题的结构特征,并且基于机器学习和规则提取分析句子的类型和答案类型。知识图谱通常可以为 NLP 工具提供领域词典,支持实体链接;同时,知识图谱的实体和关系也可以分别用于序列化标注和远程监督,支持对文本领域语料的结构化抽取,进一步增补领域知识图谱。
(2)词汇关联。主要针对在问题分析阶段尚未形成实体链接的部分形成与知识库的链接,包括关系属性、描述属性、实体分类的链接。例如“cities”映射到实体分类“城市”,“is married to”映射到关系“spouse”。也包括一些多义词,例如“Apple”(公司还是水果)。
(3)歧义消解。一方面是对候选的词汇、查询表达式排序选优,一方面通过语义的容斥关系去掉不可能的组合。例如,苹果手机是不能吃的,所以吃苹果中苹果的“电器”选项应去掉。在很多系统中,歧义消解与构建查询紧密结合:先生成大量可能的查询,然后通过统计方法和机器学习选优。
(4)构建查询。基于问题解析结果,可以通过自定义转化规则或者特定(语义模型+语法规则)将问题转化为查询语言表达式,形成对知识库的查询。QALD 的大多系统使用SPARQL 表达查询。注意查询语言不仅能表达匹配子图的语义,还能承载一些计算统计功能(average、count函数)。
8.3.4 CommunityQA/FAQ-QA:基于问答对匹配的问答系统
基于常见问答对(Frequently Asked Question,FAQ-QA[24] )以及社区问答(Community Question Answering,CQA)[25] 都依赖搜索问答FAQ库(许多问答对<Q,A>的集合)来发现以前问过的类似问题,并将找到的问答对的答案返回给用户。FAQ 与CQA 都是以问答对来组织知识,而且问答对的质量很高,不但已经是自然语言格式,而且受到领域专家或者社区的认可。二者的差异包括:答案的来源是领域专家还是社区志愿者,答案质量分别由专家自身的素质或者社区答案筛选机制保障。
基于 FAQ-QA 的核心是计算问题之间的语义相似性。重复问题发现(Duplicate Question Detection,DQD)仅限于疑问句,这是短文本相似度计算的一个特例。事实上,语义相似性面临两个挑战:
(1)“泛化”。相同的语义在自然语言表达中有众多的表示方式,不论从词汇还是语法结构上都可以有显著差异,例如 “How do I add a vehicle to this policy?” 和 “What should I do to extend this policy for my new car?”。
(2)“歧义”。两个近似的句子可以具有完全不同的语义,例如“教育部/长江学者”和“教育部长/江学者”。语义相似度计算一直是 NLP 研究的前沿。一种类型的方法试图通过利用语义词典(例如 WordNet)计算词汇相似度,这些语义相似网络来自语言学家的经验总结,受限于特定的语言;另一种方法将此任务作为统计机器翻译问题处理,并采用平行语料学习逐字或短语翻译概率,这种方法需要大量的平行问题集学习翻译概率,通常很难或成本高昂。Rodrigues J A 等人[26] 基于两个测试数据集(AskUbnuntu领域相关问题集,和Quora领域无关)对比了基于规则(JCRD Jacard)、基于传统机器学习以及基于深度学习的方法。发现基于深度学习的方法在领域问题上效果显著,但是开放领域问题中效果与传统方法接近(甚至有所下降)。SemEval 2017年[27] 评测结果指出,英文句子相似度计算的最佳结果已经达到F1=0.85。
8.3.5 Hybrid QA Framework 混合问答系统框架
从结构化数据出发的 KBQA 侧重精准的问题理解和答案查询,但是结构化的知识库总是有限;从非结构化文本出发的 IRQA侧重于利用大量来自文本的答案,但是文本抽取存在精度问题且不容易支持复杂查询与推理。所以,在工业应用中,为了满足领域知识问答的体验,结合有限的高度结构化的领域数据与大量相关的文本领域知识,需要更通用的问答框架,以取长补短。
1.DeepQA:IRQA主导的混合框架
如图8-14所示的 DeepQA[28] 综合 IRQA 和 KBQA 形成混合问答系统的架构图, Watson系统的问题处理大致分成四阶段:
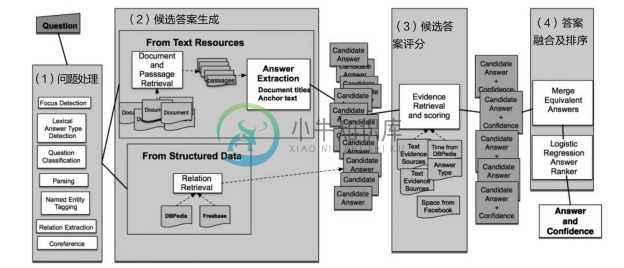
图8-14 DeepQA综合IRQA和KBQA形成混合问答系统的架构图 [13]
(1)问题处理(Question Processing)。主要是理解问题的类型,解析问题语义元素等。
(2)候选答案生成(Candidate Answer Generation)。不仅从网络上搜索相关文档并抽取答案,还从知识库直接查询答案,然后合并构成答案候选集。
(3)候选答案评分(Candidate Answer Scoring)。针对每个候选答案选取一些重要特征,并对各个特征打分并形成答案的特征向量。Watson 会利用很多信息源的佐证对候选答案进行打分,例如答案类型(Lexical Answer Type)、答案中的时空信息等。以答案类型的人的问答为例,如果已知每个历史人物的出生日期和去世日期(从百科知识图谱获取),同时要求查找一个历史人物并且提到时间范围,则候选答案中非同时期的人物可以被认为是无关的。
(4)答案融合及排序(Confidence Merging And Ranking)。首先把相同的答案进行融合(例如两个候选人名 J.F.K.和 John F.Kemedy 会被合并成为一个候选答案),形成新的答案候选集,然后对新的答案候选集进行再排序,最终由训练好的逻辑回归分类器模型对每个候选答案计算置信度,并返回置信度最高的答案作为最终答案。总之,Watson 架构的创新点是同时从 IRQA 和 KBQA 获取大量候选答案,并以大量答案佐证作为特征形成答案特征评分向量,这一点正是单独IRQA系统和KBQA系统没有做到的。
2.QALD-Hybrid-QA:KBQA主导的混合框架
在QALD-6启动的Hybrid QA 要求KBQA可以同时利用知识图谱数据和文本数据。自然语言先转化为 SPARQL 查询,但是并非所有 SPARQL 查询中的三元组特征(Triple Pattern)都可以对应到知识图谱中的词汇,也并非所有知识都可以从掌握的知识图谱中查到,有一部分知识还需要从文档中抽取关系得到解答。这样可以避免前期过度的文本抽取工作,也能适应现实中更常见的图谱和文本混合的知识库。如图8-15所示[29] ,当遇到包含“is the front man of”关系的三元组特征时,系统首先通过基于知识图谱的关系抽取技术,结合DBpedia[30] 和OpenIE[31] 从Wikipedia中抽取相关三元组。注意,在OpenIE抽取的三元组中,大量谓语 predicate 是没有经过归一融合的。然后利用平行语料模型将问句中的关系映射到抽取三元组的谓语上。例如,“front man of”映射到“lead vocalist of”上。
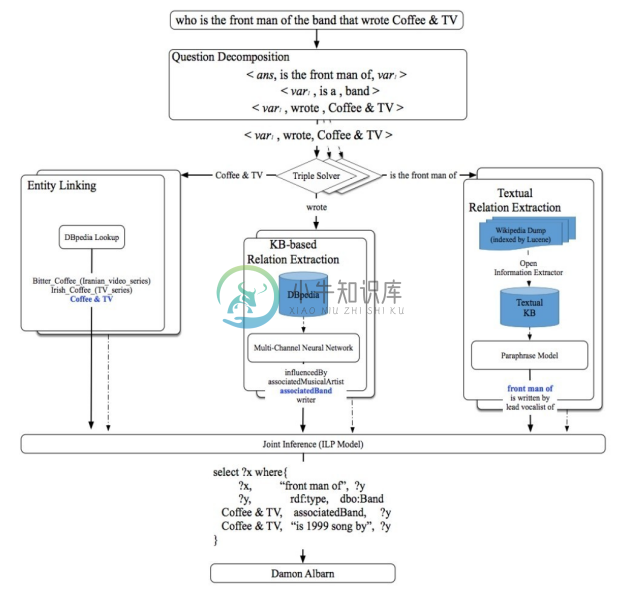
图8-15 基于SPARQL的混合问答系统的架构[29]
3.Frankenstein:问答系统的流水线架构
Frankenstein[32] 通过对60多种 KBQA 系统的研究,将 KBQA 分成基于四类核心模块的流水线,其架构如图8-16所示。模块化的流水线设计有利于将复杂的 QA 系统分解为细粒度可优化的部分,而且形成了可插拔的体系,便于系统优化更新。但是这样的流水线有两点要求:尽量使用统一的知识表示,例如基于 RDF 的知识库以及通用的Ontology/Schema,这样才能保证各模块在接口上可以复用;模块的分解目前只考虑了Question2Query 中针对结构化查询的部分,未覆盖非结构化文本的问答。这个框架首先制定了一个可配置的流水线框架,并且分解出KBQA的四个主要模块:
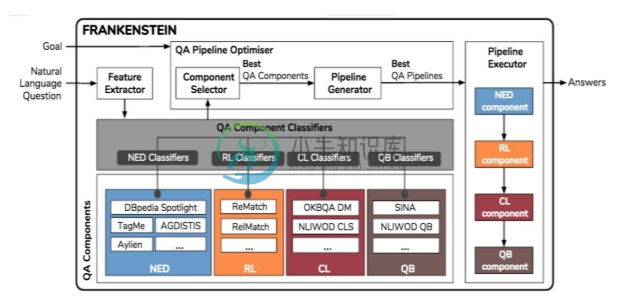
图8-16 问答系统流水线的架构[32]
(1)命名实体识别与消解歧义(Named Entity Disambiguation,NED)。从问题的文本中标记其中涉及的实体。
(2)实体关系映射(Relation Linking,RL)。将问题文本提及的关系映射到知识库的实体属性或实体关系上。
(3)实体分类映射(Class Linking,CL)。将问题所需答案的类型映射到知识库的实体分类上。
(4)构建查询(Query Building,QB)。基于上述语义理解的结果综合后形成SPARQL查询。同时,框架也利用分类器技术(QA Pipeline Classifier)支持流水线自动配置,也就是说从29个不同的模块(18个NED、5个RL、2个CL、2个QB),针对每一个特定的KBQA问答系统选取最优的流水线组合。
如图8-17所示,对于“What is the capital of Canada?”,理想的NED组件应该将关键字“Canada”识别为命名实体,并将其映射到相应的 DBpedia 资源,即 dbr:Canada。然后,RL 模块需要找到知识图谱中对应的实体关系,因此“capital”映射到 dbo:capital。最后,QB 模块综合上述结果形成 SPARQL 查询 SELECT DISTINCT?uri WHERE{dbr:Canada dbo:capital ?uri.}。
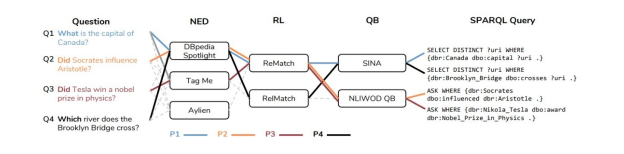
图8-17 问答系统流水线举例说明[32]