3.2 常见知识图谱存储方法
本节介绍三类知识图谱数据库:基于关系数据库的存储方案、面向 RDF 的三元组数据库和原生图数据库,多数系统给出了演示操作步骤。
3.2.1 基于关系数据库的存储方案
关系数据库拥有40多年的发展历史,从理论到实践有着一整套成熟体系。在历史上,关系数据库曾经取代了层次数据库和网状数据库;成功吸收容纳了面向对象数据库和XML 数据库,成为现今数据管理的主流数据库产品。商业数据库包括 Oracle、DB2和SQL Server等,开源数据库包括PostgreSQL和MySQL等。因此基于历史上的成功经验,人们容易想到使用关系数据库存储知识图谱。基于关系数据库的存储方案是目前知识图谱采用的一种主要存储方法。本小节将按照时间发展顺序简要介绍各种基于关系表的知识图谱存储结构,包括三元组表、水平表、属性表、垂直划分、六重索引和DB2RDF。
如图3-4所示,下面以摘自 DBpedia 数据集[23] 的 RDF数据作为知识图谱进行讲解和举例。该知识图谱描述了 IBM 公司及其创始人 Charles Flint 和 Google 公司及其创始人Larry Page的一些属性和联系。对于其他格式的知识图谱,这些存储方案同样适用。
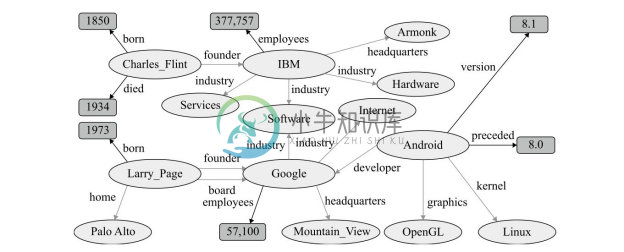
图3-4 摘自DBpedia数据集的RDF知识图谱
1.三元组表
三元组表是将知识图谱存储到关系数据库的最简单、最直接的办法,就是在关系数据库中建立一张具有3列的表,该表的模式为:
三元组表 (主语, 谓语, 宾语)
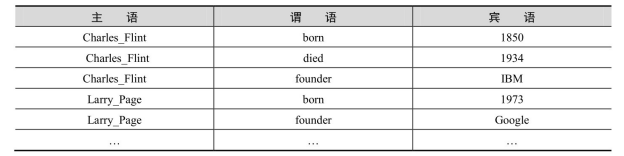
将知识图谱中的每条三元组存储为三元组表中的一行记录。表3-1是图3-4中知识图谱对应的三元组表,由于一共有21行,限于篇幅仅列出了前5行。
表3-1 三元组表
三元组表存储方案虽然简单明了,但三元组表的行数与知识图谱的边数一样,其最大问题在于将知识图谱查询翻译为 SQL 查询后的三元组表自连接。例如,如图3-5所示的SPARQL查询是查找1850年出生且1934年逝世的创办了某公司的人,翻译为等价的SQL查询后如图3-6所示,这里三元组表的表名为 t。一般自连接的数量与SPARQL中三元组模式数量相当。当三元组表规模较大时,多个自连接操作会使 SQL 查询性能低下。采用三元组表存储方案的代表是RDF数据库系统3store[24] 。
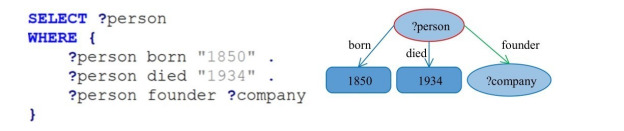
图3-5 一个星形SPARQL查询

图3-6 三元组表方案中SPARQL查询转换为等价的SQL查询
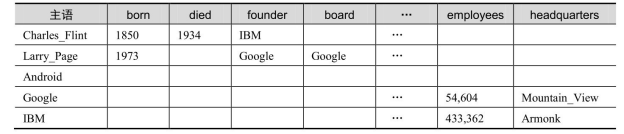
2.水平表
水平表存储方案同样非常简单,与三元组表不同,其每行记录存储一个知识图谱中一个主语的所有谓语和宾语。实际上,水平表就相当于知识图谱的邻接表。表3-2是图3-4中知识图谱对应的水平表,共有5行、13列,限于篇幅省略了若干列。不难看出,水平表的列数是知识图谱中不同谓语的数量,行数是知识图谱中不同主语的数量。
表3-2 水平表
在水平表存储方案中,图3-5所示的SPARQL查询可以等价地翻译为图3-7中的SQL查询。这里水平表的表名为 t。可见,与三元组表相比,水平表的查询大为简化,仅需单表查询即可完成该任务,不用进行连接操作。

图3-7 水平表方案中SPARQL查询转换为等价的SQL查询
但是水平表的缺点在于:所需列的数目等于知识图谱中不同谓语数量,在真实知识图谱数据集中,不同谓语数量可能为几千个到上万个,很可能超出关系数据库允许的表中列数目的上限;对于一行来说,仅在极少数列上具有值,表中存在大量空值,空值过多会影响表的存储、索引和查询性能;在知识图谱中,同一主语和谓语可能具有多个不同宾语,即一对多联系或多值属性,而水平表的一行一列上只能存储一个值,无法应对这种情况(可以将多个值用分隔符连接存储为一个值,但这违反关系数据库设计的第一范式);知识图谱的更新往往会引起谓语的增加、修改或删除,即水平表中列的增加、修改或删除,这是对于表结构的改变,成本很高。采用水平表存储方案的代表是早期的 RDF 数据库系统DLDB[25] 。
3.属性表
属性表(Property Table)存储方案是对水平表的细化,将同类主语分到一个表中,不同类主语分到不同表中。这样就解决了表中列的数目过多的问题。图3-8给出了图3-4中知识图谱对应的属性表存储方案,即把一个水平表分为了 person(人)、os(操作系统)和company(公司)三个表。对于图3-5中的SPARQL查询,在属性表存储方案上等价的SQL查询如图3-9所示;该查询与图3-7中水平表上查询的唯一区别是将表名由t变为了person。
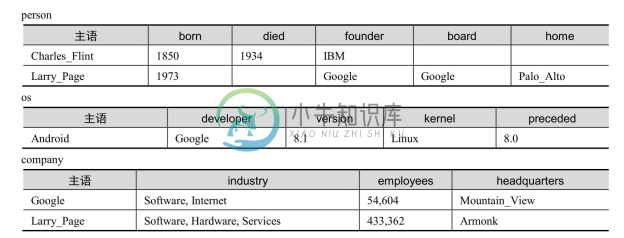
图3-8 属性表

图3-9 属性表方案中SPARQL查询转换为等价的SQL查询
属性表既克服了三元组表的自连接问题,又解决了水平表中列数目过多的问题。实际上,水平表方案是属性表存储方案的一种极端情况,即水平表是将所有主语划归为一类,因此属性表中的空值问题与水平表相比会大为缓解。但属性表方案仍有缺点:对于规模稍大的真实知识图谱数据,主语的类别可能有几千个到上万个,按照属性表方案,需要建立几千个到上万个表,这往往超过了关系数据库的限制;对于知识图谱上稍复杂的查询,属性表方案仍然会进行多个表之间的连接操作,从而影响查询效率;即使在同一类型中,不同主语具有的谓语集合也可能存在较大差异,这样会造成与水平表中类似的空值问题;水平表方案中存在的一对多联系或多值属性存储问题仍然存在。采用属性表存储方案的代表是RDF三元组库Jena[26] 。
4.垂直划分
垂直划分(Vertical Partitioning)存储方案是由美国麻省理工学院的 Abadi 等人在2007年提出的 RDF 数据存储方法[27] 。该方法以三元组的谓语作为划分维度,将 RDF 知识图谱划分为若干张只包含(主语, 宾语)两列的表,表的总数量即知识图谱中不同谓语的数量;也就是说,为每种谓语建立一张表,表中存放知识图谱中由该谓语连接的主语和宾语值。图3-10给出了图3-4中知识图谱对应的垂直划分存储方案,从中可以看到,13种谓语对应着13张表,每张表都只有主语和宾语列。对于图3-5中的SPARQL查询,在垂直划分存储方案中等价的SQL查询如图3-11所示;该查询涉及3张谓语表born、died和founder 的连接操作。由于谓语表中的行都是按照主语列进行排序的,可以快速执行这种以“主语-主语”作为连接条件的查询操作,而这种连接操作又是常用的。
与之前基于关系数据库的知识图谱存储方案相比,垂直划分有一些突出的优点:谓语表仅存储出现在知识图谱中的三元组,解决了空值问题;一个主语的一对多联系或多值属性存储在谓语表的多行中,解决了多值问题;每个谓语表都按主语列的值进行排序,能够使用归并排序连接(Merge-sort Join)快速执行不同谓语表的连接查询操作。
与之前基于关系数据库的知识图谱存储方案相比,垂直划分有一些突出的优点:谓语表仅存储出现在知识图谱中的三元组,解决了空值问题;一个主语的一对多联系或多值属性存储在谓语表的多行中,解决了多值问题;每个谓语表都按主语列的值进行排序,能够使用归并排序连接(Merge-sort Join)快速执行不同谓语表的连接查询操作。
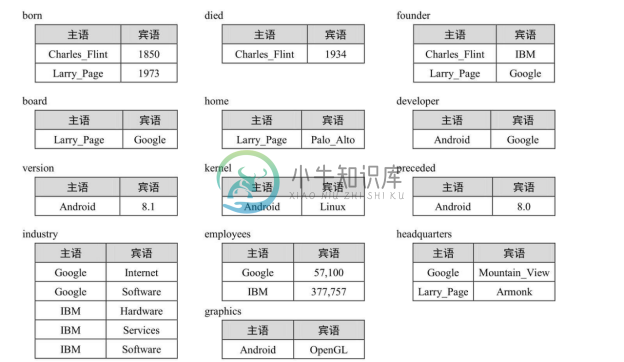
图3-10 垂直划分存储方案

图3-11 垂直划分方案中等价的SQL查询
不过,垂直划分存储方案依然存在几个缺点:需要创建的表的数目与知识图谱中不同谓语数目相等,而大规模的真实知识图谱(如 DBpedia、YAGO、Wikidata 等)中谓语数目可能超过几千个,在关系数据库中维护如此规模的表需要很大的开销;越是复杂的知识图谱查询操作,需要执行的表连接操作数量越多,而对于未指定谓语的三元组查询,将发生需要连接全部谓语表进行查询的极端情况;谓语表的数量越多,数据更新维护代价越大,对于一个主语的更新将涉及多张表,产生很高的更新时 I/O 开销。采用垂直划分存储方案的代表数据库是SW-Store[28] 。
5.六重索引
六重索引(Sextuple Indexing)存储方案是对三元组表的扩展,是一种典型的“空间换时间”策略,其将三元组全部6种排列对应地建立为6张表,即 spo (主语, 谓语, 宾语)、pos (谓语, 宾语, 主语)、osp (宾语, 主语, 谓语)、sop (主语, 宾语, 谓语)、pso (谓语,主语, 宾语)和ops (宾语, 谓语, 主语)。不难看出,其中spo表就是原来的三元组表。六重索引通过6张表的连接操作不仅缓解了三元组表的单表自连接问题,而且加速了某些典型知识图谱查询的效率。使用六重索引方法的典型系统有RDF-3X[28] 和Hexastore[29] 。
具体来说,六重索引方案的优点有:知识图谱查询中的每种三元组模式查询都可以直接使用相应的索引表进行快速的前缀范围查找,表3-3给出了全部8种三元组模式查询能够使用的索引表;可以通过不同索引表之间的连接操作直接加速知识图谱上的连接查询,如图3-12所示的链式SPARQL查询“查找生于1850年的人创立的公司的营业领域”,可以通过 spo 和 pso 表的连接快速执行三元组模式“?person founder ?company”与“?company industry ?ind”的连接操作,避免了单表的自连接。
表3-3 三元组模式查询能够使用的索引表
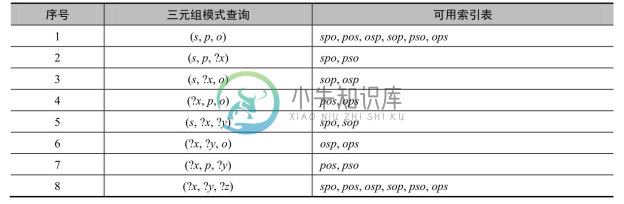

图3-12 一个链式SPARQL查询
六重索引存储方案存在的问题包括:虽然部分缓解了三元组表的单表自连接问题,但需要花费6倍的存储空间开销、索引维护代价和数据更新时的一致性维护代价,随着知识图谱规模的增大,该问题会愈加突出;当知识图谱查询变得复杂时,会产生大量的连接索引表查询操作,索引表的自连接依然不可避免。
6.DB2RDF
DB2RDF是由 IBM 研究中心于2013年提出的一种面向实体的RDF知识图谱存储方案[30] ,该方案是以往 RDF 关系存储方案的一种权衡折中,既具备了三元组表、属性表和垂直划分方案的部分优点,又克服了这些方案的部分缺点。三元组表的优势在于“行维度”上的灵活性,即存储模式不会随行的增加而变化;DB2RDF方案将这种灵活性扩展到“列维度”上,即将表的列作为谓语和宾语的存储位置,而不将列与谓语进行绑定。当插入数据时,将谓语动态地映射存储到某列;方案能够确保将相同的谓语映射到同一组列上。
DB2RDF存储方案由4张表组成,即dph表、rph表、ds表和rs表;图3-13给出了图3-4中知识图谱对应的DB2RDF存储方案。dph(direct primary hash)是存储方案的主表,该表中一行存储一个主语(主语列)及其全部谓语(predi 列)和宾语(vali 列), 0≤i≤k,k 为图着色结果值或某个给定值。如果一个主语的谓语数量大于 k,则一行不足以容纳下一个实体,将在下一行存储第 k+1到2k 个谓语和宾语,以此类推,这种情况叫作溢出。spill列是溢出标志,即对于一行能存储下的实体,该行spill列为0,对于溢出的实体,该实体所有行的 spill 列为1。例如,在图3-13的 dph 表中,除实体 Android 溢出外,其余实体均存储为一行。
对于多值谓语的处理,引入ds(direct secondary hash)表。当dph表中遇到一个多值谓语时,则在相应的宾语处生成一个唯一的id值;将该id值和每个对应的宾语存储为ds表的一行。例如,在图3-13的dph表中,主语Google的谓语industry(pred1列)是多值谓语,则在其宾语列(val1)存储 id 值 lid:1;在 ds 表中存储 lid:1关联的两个宾语Software和Internet。
实际上,dph 表实现了列的共享:一方面,不同实体的相同谓语总是会被分配到相同的列上;另一方面,同一列中可以存储多个不同的谓语。例如,主语 Charles_Flint 和Larry_Page的谓语founder都被分配到pred3列,该列也存储了主语Android的谓语kernel和graphics。正是由于DB2RDF方案具备“列共享”机制,才使得在关系表中最大列数目上限的情况下可以存储远超出该上限的谓语数目,也能够有效地解决水平表方案中存在的谓语稀疏性空值问题。在真实的知识图谱中,不同主语往往具有不同的谓语集合,例如,谓语born只有人才具有,谓语employees只有公司才具有,这也是能够实现列共享的原因所在。
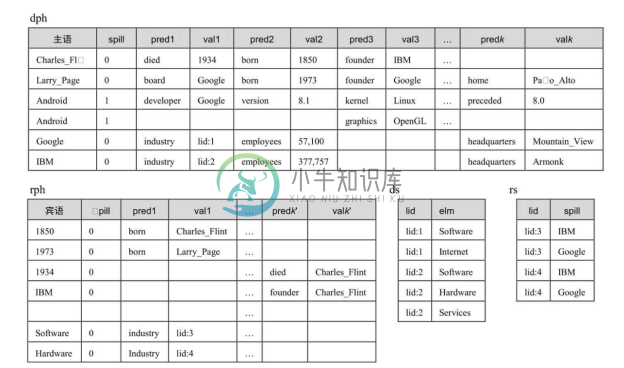
图3-13 DB2RDF方案
从图数据模型的角度来看,dph表和ds表实际上存储了实体节点(主语)的出边信息(从主语经谓语到宾语);为了提高查询处理效率,还需要存储实体节点的入边信息(从宾语经谓语到主语)。为此,DB2RDF 方案提供了 rph(reverse primary hash)表和 rs (reverse secondary hash)表,如图3-13所示。
DB2RDF 方案中 SPARQL 查询转换为等价的 SQL 查询如图3-14所示。从中可以看出,对于知识图谱的星型查询,DB2RDF存储方案只需要查询dph表即可完成,无须进行连接操作。

图3-14 DB2RDF方案中SPARQL查询转换为等价的SQL查询
在 DB2RDF 方案中,谓语到列的映射是需要重点考虑的问题。因为关系表中最大列的数目是固定的,该映射的两个优化目标是:使用的列的数目不要超过某个值 m;尽量减少将同一主语的两个不同谓语分配到同一列的情况,从而减少溢出现象,因为溢出会导致查询时发生自连接。
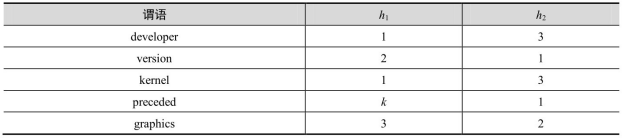
谓语到列映射的一种方法是使用一组散列函数,将谓语映射到一组列编号,并将谓语及其宾语存储到这组列中的第一个空列上;在一个主语对应的一行中,如果存储某谓语(及其宾语)时,散列函数计算得出的这组列中的所有列都被之前存储的该主语的谓语占用了,则产生溢出,到下一行存储该谓语。例如,表3-4给出了谓语到列映射的散列函数表,其中包括 h1 和 h2 两个散列函数,映射了5个谓语到列编号组。现在开始存储以Android 作为主语的三元组:当存储 (Android, developer, Google)时,在 dph 表中为主语Android 插入一个新行,根据 h1 的值将谓语 developer 存入列 pred1;当存储 (Android, version, 8.1)时,根据h1 的值将谓语version存储列pred2;当存储 (Android, kernel, Linux)时,谓语kernel被h1 映射到列pred1,但该列已被占用,因而接着被h2 映射到列pred3;当存储 (Android, preceded, 8.0)时,谓语preceded被h1 映射到列predk;当存储 (Android, graphics, OpenGL)时,谓语 graphics被 h1 映射到列 pred3,被 h2 映射到列 pred2,但这两列都已被占用,这时产生溢出,将谓语graphics溢出到下一行的列pred3中存储,如图3-13的dph表所示。
表3-4 谓语到列映射的散列函数表
如果可以事先获取知识图谱的一个子集,则可以利用知识图谱的内在结构优化谓语到列的映射。方法是将谓语到列的映射转化为图着色(Graph Coloring)问题[31] 。将一个主语上出现的不同谓语称为共现谓语(Co-occurrence Predicates),目标是让共现谓语着上不同颜色(映射到不同列中),非共现谓语可以着上相同颜色(映射到同一列中)。为此,构建图着色算法的冲突图(Interference Graph):图中节点为知识图谱中的所有谓语;每对共现谓语节点之间由一条边相连。图着色问题的要求是为冲突图中的节点着上颜色,使得每个节点的颜色不同于其任一邻接节点的颜色,并使所用颜色数最少;对应到谓语映射问题,即为冲突图中的谓语节点分配列,使得每个谓语映射到的列不同于其任一共现谓语映射到的列,并使所用的列数目最少。图3-15给出了图3-4中知识图谱的冲突图。可见,对于13个谓语,仅使用了5种颜色,即只需使用5列。需要指出的是,图着色是经典的NP难问题,对于规模较大的冲突图可用贪心算法(如Welsh-Powell算法)[32] 求得近似解。
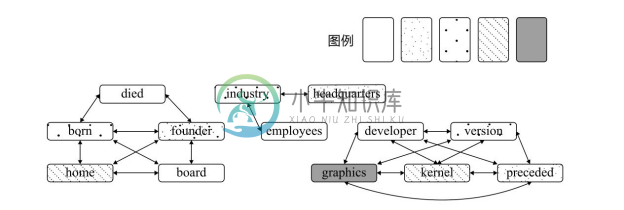
图3-15 冲突图
如果在大规模真实知识图谱(如 DBpedia)中,图着色所需颜色数量超过了关系数据表的列数上限m,则根据某种策略(如最频繁使用的前k个谓语)选取一个谓语子集,使得该谓语子集到列的映射满足图着色要求;对于不在该子集中的谓语,再使用前面提到的散列函数组策略进行映射。
3.2.2 面向RDF的三元组数据库
由于 RDF 是 W3C 推荐的表示语义网上关联数据(Linked Data)的标准格式,RDF也是表示和发布 Web上知识图谱的最主要数据格式之一。面向 RDF的三元组数据库是专门为存储大规模 RDF 数据而开发的知识图谱数据库,其支持 RDF 的标准查询语言SPARQL。本节将分别介绍几种主要的开源和商业RDF三元组数据库。
主要的开源 RDF三元组数据库包括:Apache 旗下的 Jena、Eclipse 旗下的 RDF4J 以及源自学术界的 RDF-3X 和 gStore;主要的商业 RDF 三元组数据库包括:Virtuoso、AllegroGraph、GraphDB和BlazeGraph。Apache Jena将以实践形式进行详细介绍;下面分别介绍RDF4J、RDF-3X、gStore、Virtuoso、AllegroGraph、GraphDB和BlazeGraph。
1.开源RDF三元组数据库RDF4J
RDF4J目前是Eclipse基金会旗下的开源孵化项目,其前身是荷兰软件公司Aduna开发的Sesame框架。Sesame框架的历史可以追溯到1999年,当时作为Aduna公司的一个语义Web项目进行开发,后来发展成为语义Web领域一个非常有名的管理和处理RDF的开源Java框架,功能包括RDF数据的解析、存储、推理和查询等。2016年5月,Sesame框架改名为RDF4J,并迁移为Eclipse开源项目继续开发。
RDF4J 本身提供内存和磁盘两种 RDF 存储机制,支持全部的 SPARQL 1.1查询和更新语言,可以使用与访问本地 RDF 库相同的 API 访问远程 RDF 库,支持所有主流 RDF数据格式,包括RDF/XML、Turtle、N-Triples、N-Quads、JSON-LD、TriG和TriX。
RDF4J框架的重要特点是其模块化的软件架构设计。图3-16给出了RDF4J的高层架构图,其设计采取典型的层次结构。
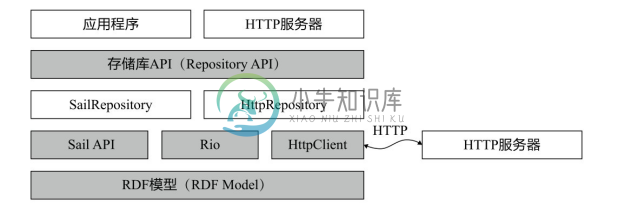
图3-16 RDF4J的高层架构图
(1)底层的 RDF 模型定义了 URI、空节点(Blank Node)、字面值(Literal)和语句(Statement)等RDF基本元素。
(2)Rio 代表“RDF I/O”,即 RDF 输入/输出,包括各种 RDF 文件格式的解析器(Parser)和编写器(Writer),解析器负责将RDF文件解析为RDF模型中的三元组语句,编写器负责将三元组语句写为RDF文件。
(3)Sail API代表“存储和推理层API”(Storage And Inference Layer API),是实现RDF 存储和推理的底层系统(System)API(即 SPI),其作用是将 RDF 存储和推理功能从底层实现细节中抽象出来,使得底层存储和推理实现模块可以透明地被替换;Sail API是 SAIL 底层存储开发者需要实现的 API,普通用户无须关心;RDF4J 自带了两种 Sail API实现,即基于内存的MemoryStore和基于磁盘的NativeStore。
(4)存储库 API(Repository API)是用户使用的 RDF 管理和处理高层 API,提供RDF 的存储、查询和推理等服务,面向终端用户,简单易用;存储库 API 的一种实现是基于本地 SAIL 实现的 SailRepository,另一种是基于远程 HTTP 服务器实现的HttpRepository。
(5)架构图的顶层是用户开发的应用程序和HTTP服务器,用户应用程序直接调用存储库 API;HTTP 服务器实现了通过 HTTP 访问存储库 API 的 Web 服务,可通过HttpClient库与HTTP服务器进行远程通信,从而访问远程RDF4J存储库。
RDF4J可以通过其官方网站下载。下面给出部署RDF4J服务器和工作台的步骤。
步骤1。下载RDF4J SDK zip压缩包,解压并安装到本机的任意位置。
步骤2。开启Tomcat Web服务器,将RDF4J安装目录下的war子目录中的rdf4j-server.war和rdf4j-workbench.war复制到Tomcat的Web应用程序部署目录webapps中。
步骤3。打开浏览器,访问 http://localhost:8080/rdf4j-workbench,出现 RDF4J 工作台管理Web界面。
步骤4。选择左侧栏菜单项【Repositories】/【New repository】,Type 选择“Native Java Store”,即基于磁盘的本地RDF存储(默认是In Memory Store,即基于内存的RDF存储),单击【Next】按钮,进入下一个页面。
步骤5。输入新建存储库的 ID 为 testds,其他接受默认设置,单击【Create】按钮,创建存储库。
步骤6。选择左侧栏菜单项【Modify】/【Add】,右侧出现 Add RDF 页面,在 RDF Data File一栏,单击【选择文件】按钮,选择3.4节中的RDF知识图谱文件music_1000_triples.nt,单击【Upload】按钮,将RDF文件上传至RDF4J存储库。
步骤7。选择左侧栏菜单项【Explore】/【Summary】,右侧的Summary页面中显示存储库位置(Repository Location)和存储库规模(Repository Size)等信息。
步骤8。选择左侧栏菜单项【Explore】/【Query】,出现查询界面 Query Repository,查询语言选择 SPARQL,在 Query 文本框中输入 SPARQL 查询,单击 Action 一栏中的【Execute】按钮,获得查询结果,如图3-17所示。
正是由于 RDF4J 规范的模块化设计,使其成为很多其他 RDF 三元组数据库(如GraphDB)的上层标准框架,这些三元组库只需要实现各自的 SAIL API,依赖于 RDF4J存储库API的应用程序而无须修改,便可以在不同的三元组库之间实现透明切换。
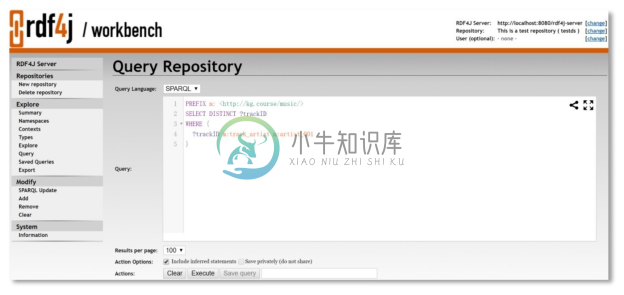
图3-17 使用RDF4J工作台执行SPARQL查询
2.开源RDF三元组数据库RDF-3X
RDF-3X 是由德国马克斯·普朗克计算机科学研究所研发的 RDF 三元组数据库系统,其最初成果发表于2008年的数据库国际会议 VLDB[28] ,后经功能扩展和完善,最新版本是GH-RDF3X,源代码可以从GitHub上下载。目前,RDF-3X只支持Linux系统。
RDF-3X 的最大特点在于其为 RDF 数据精心打造的压缩物理存储方案、查询处理和查询优化技术。在逻辑存储上,虽然以简单的三元组表为基础,但首次提出全索引方案:建立6种三元组索引 spo、sop、osp、ops、pso 和 pos;建立6种二元聚合索引 sp、ps、so、os、po 和 op;建立3种一元聚合索引 s、p、o。在物理存储上,采用基于 B+树的压缩方案:使用字典快速查找表建立 RDF字符串到整数 id 的映射;使用面向字节的增量编码压缩技术,实现三元组的压缩存放;三元组压缩限于 B+树页面内部,不会跨越不同页面,避免了不必要的解压缩操作,能够提高查询效率。借助巧妙设计的三元组压缩技术,全索引方案的空间开销是可以接受的,全索引为查询处理和优化带来了巨大便利。
对于利用全索引方案的查找,仅以spo索引为例进行举例。如图3-18所示,利用spo索引查找三元组模式 (Albert_Einstein, invented, ?x),spo 索引中存储的是已经进行字典编码之后的由整数id值组成的 (s, p, o)三元组,并且已按照s、p、o值由小到大的顺序进行了排序。查找步骤如下:
步骤1。查找字典编码表,将主语Albert_Einstein映射为16,将invented映射为24,将三元组模式查询变为 (16, 24, ?x)。
步骤2。利用B+树进行前缀为 (16, 24)的范围查找,该查找在B+树中可以快速完成。
步骤3。返回匹配的索引项三元组 (16, 24, 567)和 (16, 24, 876)。
步骤4。最后再查找字典编码表,将整数id映射回字符串。
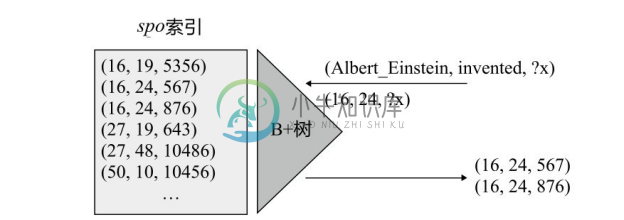
图3-18 使用spo索引进行三元组模式查找
RDF-3X的查询处理器首先对SPARQL查询进行转化,生成若干查询执行计划;对于仅包含一个三元组模式的查询,可以通过一次相应索引查找操作完成;对于由多个三元组模式组成的查询,需要对多个连接的顺序进行优化。RDF-3X 采用的是一种自底向上的动态规划优化算法,其优化过程充分考虑了 SPARQL 查询的特点,并且最大限度地保持了有利于用全索引方案进行归并连接的连接顺序。同时,RDF-3X 还开发了基于代价模型的选择度评估(Selectivity Estimates)机制,采用选择度直方图和频繁连接路径相结合的方法进行查询执行计划的选择度评估。
RDF-3X是命令行程序,使用RDF-3X装载RDF文件music_1000_triples.nt的命令如图3-19所示,其中的rdf3xload是命令名称,testds是数据库名称;进行SPARQL查询的命令如图3-20所示,rdf3query是命令名称,sparql.rq是SPARQL查询文件名称。
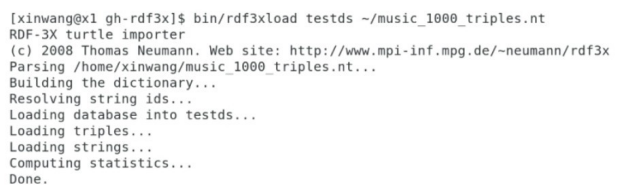
图3-19 使用RDF-3X装载RDF文件

图3-20 使用RDF-3X进行SPARQL查询
3.开源RDF三元组数据库gStore
gStore是基于图的RDF三元组数据库。gStore将RDF图G中的每个实体节点及其邻居属性和属性值编码成一个二进制位串,由这些位串作为节点组成一张与 RDF图 G 对应的标签图 G* 。在执行 SPARQL 查询时,将查询图 Q 也转化为一张查询的标签图 Q* 。gStore 的研究工作已经证明了 Q* 在 G* 上的匹配是 Q 在 G 上匹配的超集。为了支持在 G* 上快速地查找到 Q* 的匹配位置,gStore 系统提出建立“VS 树”索引,其基本思想实际上是为标签图 G*建立不同详细程度的摘要图(summary graph);利用“VS”树索引提供的摘要图,gStore系统提出可以大幅削减SPARQL查询的搜索空间,加快查询速度。
目前,gStore 已经作为开源项目发布,源代码和文档可以从其 GitHub 项目网站下载。与RDF-3X一样,gStore只能在Linux系统上运行。关于gStore内部实现的详细信息可参见文献[33]。
使用gStore提供的gconsole交互式命令行客户端装载RDF图数据和执行SPARQL查询的步骤如下:
步骤1。在编译成功的gStore目录下,运行bin/gconsole,进入交互式命令行客户端。
步骤2。执行命令build testds music_1000_triples.nt,构建数据库testds,并将RDF文件music_1000_triples.nt装载到testds数据库。
步骤3。执行命令load testds,加载testds数据库。
步骤4。执行命令query sparql.rq,执行文件sparql.rq中的SPARQL查询。
4.商业RDF三元组数据库Virtuoso
Virtuoso 虽然是可以支持多种数据模型的混合数据库管理系统,但其基础源自开发了多年的传统关系数据库管理系统,因此具备较为完善的事务管理、并发控制和完整性机制。Virtuoso同时发布了商业版本Virtuoso Universal Server(Virtuoso统一服务器)和开源版本 OpenLink Virtuoso。其开源版本可在其 GitHub 网站下载。在 Windows 系统上, Virtuoso可安装为 Windows 服务的形式,启动 OpenLink Virtuoso Server 服务。在浏览器中,打开http://localhost:8890/,进入Virtuoso的Web管理界面Conductor。操作步骤如下:
步骤1。以默认用户名密码dba登录。
步骤2。单击菜单项【Linked Data】/【Quad Store Upload】,进入RDF文件上传页面。
步骤3。在 File 栏选择文件 music_1000_triples.nt,在 Named Graph IRI 栏输入http://localhost:8890/DAV/music,单击【Upload】按钮,上传RDF文件。
步骤4。单击菜单项【Linked Data】/【SPARQL】,进入SPARQL查询页面。
步骤5。在Default Graph IRI栏中输入http://localhost:8890/DAV/music。
步骤6。在 Query 文本框中输入要执行的 SPARQL 查询,单击【Execute】按钮执行,如图3-21所示。
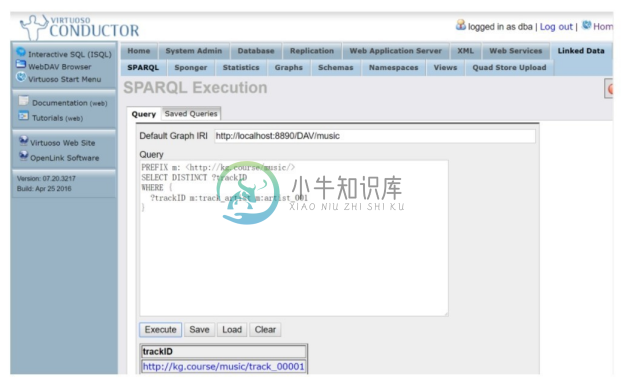
图3-21 使用Virtuoso进行SPARQL查询
5.商业RDF三元组数据库AllegroGraph
AllegroGraph是Franz公司开发的RDF三元组数据库。由于Franz公司有着深厚的人工智能背景,早期一直开发 Common Lisp 和 Prolog 语言的实现工具,这使得AllegroGraph 对语义推理功能具有较为完善的支持。AllegroGraph 除了三元组数据库的基本功能外,还支持动态物化的 RDFS++推理机、OWL2 RL 推理机、Prolog 规则推理系统、时空推理机制、社会网络分析库、可视化 RDF 图浏览器等。同时,AllegroGraph 支持Java、Python、C#、Ruby、Clojure/Scala、Lisp等多种语言的编程访问接口。图3-22所示为AllegroGraph的系统架构。

图3-22 AllegroGraph的系统架构
下面演示 AllegroGraph 的安装、RDF 知识图谱导入与 SPARQL 查询。从官方网站下载 AllegroGraph 服务器免费版(存储的 RDF 三元组数量不能超过500万条)。AllegroGraph要求操作系统为64位Linux。
步骤1。解压缩下载的安装包文件:
tar zxf agraph-6.4.1-linuxamd64.64.tar.gz。
解压缩后的目录为agraph-6.4.1。
步骤2。进入 agraph-6.4.1目录,执行安装脚本:install-agraph/home/xinwang/agraph。
将 AllegroGraph 安装到指定目录/home/xinwang/agraph 中。在安装过程中,需要回答一系列系统配置问题,作为测试环境,只需要输入两次管理员用户 super 的密码,对于其他问题直接按Enter键,接受默认值即可。
步骤3。执行脚本,启动AllegroGraph服务器:
/home/xinwang/agraph/bin/agraph-control--config/home/xinwang/agraph/lib/agraph.cfg start
输出如下,表示服务器启动成功:
Daemonizing...
Server started normally: Running with free license of 5,000,000 triples; no-expiration.
Access AGWebView at http://127.0.0.1:10035
步骤4。在浏览器中访问 http://127.0.0.1:10035,打开 AllegroGraph 服务器的 Web 管理界面AGWebView。以super身份登录。
步骤5。创建数据库。在“Create new repository”部分的“Name”文本框中输入testds,单击【Create】按钮创建数据库,如图3-23所示。
图3-23 AllegroGraph创建数据库
步骤6。导入RDF知识图谱。在“Repository testds”页面中,选择【Load and Delete Data】/【Import RDF】/【from an uploaded file】,在该页面上方出现选择RDF文件的对话框,在“File:”字段中浏览并选择 music_1000_triples.nt 文件,单击对话框右下方的【OK】按钮。
步骤7。查询知识图谱。选择页面上方菜单栏中的【Query】/【New】菜单项;转到【Edit query】页面,输入 SPARQL 查询,单击页面下方的【Execute】按钮执行查询,如图3-24所示,该查询的执行结果如图3-25(a)所示。单击查询结果中的第一个实体track_00001,得到以其为主语的全部三元组详细信息,如图3-25(b)所示。
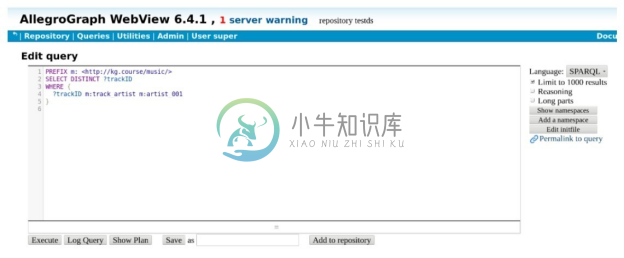
图3-24 AllegroGraph执行SPARQL查询

图3-25 AllegroGraph执行SPARQL查询的结果
步骤8。执行脚本,停止AllegroGraph服务器:
/home/xinwang/agraph/bin/agraph-control--config/home/xinwang/agraph/lib/agraph.cfg stop。
6.商业RDF三元组数据库GraphDB
GraphDB是RDF三元组数据库,其前身OWLIM一直是支持W3C语义Web标准的主流产品。GraphDB目前有社区免费版、标准版和企业版,其中企业版支持多台机器的集群分布式部署。
GraphDB的高层架构如图3-26所示。
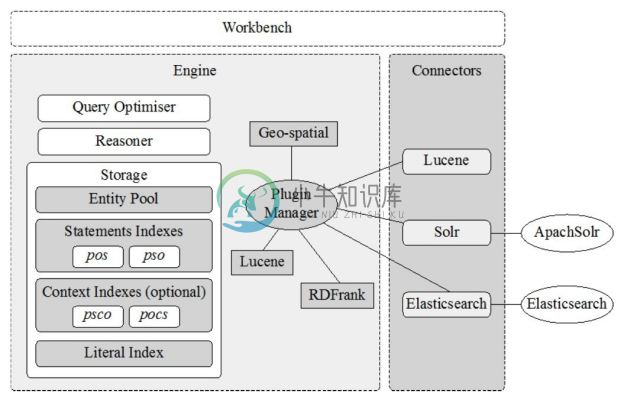
图3-26 GraphDB的高层架构
对于GraphDB的各部分组件自顶向下进行介绍:
(1)Workbench是GraphDB的Web管理工具;
(2)Engine 是查询处理和推理引擎,由查询优化器(Query Optimiser)、推理机(Reasoner)、存储层(Storage)和插件管理器(Plugin Manager)组成;
●查询优化器能够在多种查询执行计划中挑选出较高效的一种,查询经过解析后会交由查询优化器进行优化;
●推理机执行基于 RDF 规则的前向链推理,由显式三元组推导出全部导出三元组,导出三元组会随显式三元组的更新而同步更新;
●存储层使用 pos 和 pso 两种三元组索引、psco 和 pocs 两种带有上下文信息的四元组索引以及字面值(Literal)索引存储 RDF 数据;实体池(Entity Pool)是GraphDB 存储层的核心部件,起到将 RDF 实体(URI、空节点和字面值)映射到内部整数ID的字典编码器的作用,同时还实现了对事务管理的支持机制。
(3)Connectors 是 GraphDB 连接外部工具的桥梁,包括用于建立快速关键字查找功能的Lucene和用于建立搜索引擎的Solr和Elasticsearch。
(4)插件管理器在 Engine 内起到插件管理作用,既包括 GraphDB内部实现的插件,也包括各种外部工具连接器。
7.商业RDF三元组数据库Blazegraph
Blazegraph在1.5版本之前叫作Bigdata,但众所周知的“大数据”的兴起使得这个不温不火的 RDF 三元组库软件被淹没其中。但这个软件在“大数据”兴起前很多年就叫Bigdata,迫不得已改名叫 Blazegraph 之后,其开发理念也有所调整。原来仅仅是支持RDF 三元组存储和 SPARQL,现在已经定位为全面支持 Blueprints 标准的图数据库。不过,其内部实现技术仍是面向RDF三元组和SPARQL的,因而可以理解为是“基于RDF三元组库的图数据库”。
从2006年发布至今,Blazegraph 一直由 SYSTAP 公司开发,虽然它既不是最知名的RDF 三元组库,也不是最流行的图数据库,但开发进展稳扎稳打,积累了相对全面的功能。
Blazegraph 可以通过其官方网站下载。既可以将 Blazegraph 作为 War 包部署为 Web程序,也可以将其配置为单机或分布式数据库服务器。下面给出通过可执行 jar 包配置单机服务器的步骤。
步骤1。下载bigdata-bundled.jar。
步骤2。在命令行中执行java -server -Xmx4g -jar bigdata-bundled.jar。
步骤3。在浏览器中打开http://localhost:9999,进入Blazegraph的Web用户界面。
在Blazegraph Web用户界面中执行SPARQL查询并返回结果的效果,如图3-27所示。
图3-27 Blazegraph的Web用户界面
8.商业RDF三元组数据库Stardog
Stardog是由美国Stardog Union公司开发的RDF三元组数据库,其首个公开发布版本是2012年2月发布的Stardog 0.9。Stardog支持RDF图数据模型、SPARQL查询语言、属性图模型、Gremlin 图遍历语言、OWL2标准、用户自定义的推理与数据分析规则、虚拟图、地理空间查询以及多种编程语言与网络接口支持。虽然 Stardog 发布较晚,但其对OWL2推理机制具有良好的支持,同时具备全文搜索、GraphQL查询、路径查询、融合机器学习任务等功能,能够支持多种不同编程语言和Web访问接口,使得Stardog成为一个知识图谱数据存储和查询平台。
Stardog分为企业版和社区版,社区版可以免费用于非商业用途。下面演示Stardog社区版的安装与使用方法。在 Stardog 官方网站中填写邮箱等必要信息,通过邮件中的链接下载许可证文件stardog-license-key.bin。按照Stardog用户手册,推荐在Linux操作系统下安装。
步骤1。使用如下命令在CentOS Linux系统上安装Stardog:

默认安装位置为/var/opt/stardog。
步骤2。设置STARDOG_HOME和PATH环境变量:
![]()
步骤3。将许可证文件复制到STARDOG_HOME目录:
![]()
步骤4。启动Stardog服务器,默认端口为HTTP 5820:
![]()
步骤5。创建数据库并导入RDF文件:
![]()
输出结果如下:

表示创建数据库并导入RDF数据成功。
步骤6。执行SPARQL查询,运行命令:
![]()
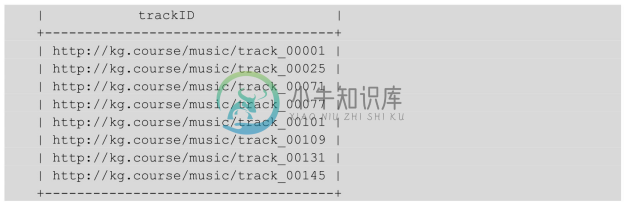
返回结果为:
![]()
还可以更方便地使用Web管理客户端Stardog Studio进行数据库管理和查询。在浏览器中访问 http://localhost:5820,使用默认的管理员账号,用户名和密码均为 admin。登录成功后,如图3-28所示。
图3-28 Stardog Studio管理客户端
选择 testds 数据库,单击【Query】按钮,进入查询界面,输入相应的 SPARQL 语句进行查询,如图3-29所示。
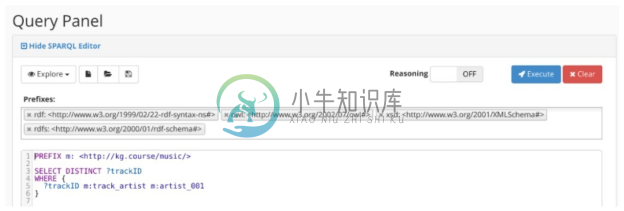
图3-29 使用Stardog Studio执行SPARQL查询
3.2.3 原生图数据库
1.最流行的图数据库Neo4j
Neo4j的1.0版本发布于2010年。Neo4j基于属性图模型,其存储管理层为属性图结构中的节点、节点属性、边、边属性等设计了专门的存储方案。这使得Neo4j 在存储层对于图数据的存取效率天生就优于关系数据库。同时,Neo4j 还具备 OLTP 数据库必需的ACID事务处理功能。
Neo4j 的不足之处在于其社区版是单机系统,虽然 Neo4j 企业版支持高可用性(High Availability)集群,但其与分布式图存储系统的最大区别在于每个节点上存储图数据库的完整副本(类似于关系数据库镜像的副本集群),不是将图数据划分为子图进行分布式存储,并非真正意义上的分布式数据库系统。如果图数据超过一定规模,系统性能就会因为磁盘、内存等限制而大幅降低。
开发者注册信息后可以免费下载 Neo4j 桌面打包安装版(Neo4j Desktop),其中包括Neo4j 企业版的全部功能,即 Neo4j 服务器、客户端及全部组件。安装之后的 Neo4j Desktop数据库管理界面如图3-30所示。
图3-30 Neo4j Desktop数据库管理界面
在Neo4j Desktop管理界面中选择【Open Browser】,打开Neo4j浏览器。Neo4j浏览器是功能完善的Neo4j可视化交互式客户端工具,可以用于执行Cypher语言。使用Neo4j内置的 Movie 图数据库执行 Cypher 查询,返回“Tom Hanks”所出演的全部电影,如图3-31所示。此外,成功启动Neo4j服务器之后,会在7474和7473端口分别开启HTTP和HTTPS服务。例如,使用浏览器访问http://localhost:7474/进入Web界面,执行Cypher查询,其功能与Neo4j浏览器是一致的。

图3-31 Neo4j浏览器界面
2.分布式图数据库JanusGraph
JanusGraph借助第三方分布式索引库Elasticsearch、Solr和Lucene实现各种类型数据的快速检索功能,包括地理信息数据、数值数据和全文搜索。JanusGraph 的前身 Titan 是由 Aurelius 公司开发的,而该公司的创始人 Rodriguez 博士恰恰就是 Blueprints 标准及Gremlin 语言的主要开发者,Titan 对于 Blueprints 标准和 Gremlin 语言的全面支持便不难理解,JanusGraph 基本上继承了 Titan 的这一特性。同时,JanusGraph 也是 OLTP 图数据库,其支持多用户并发访问和实时图遍历查询。另一方面,JanusGraph 还具备基于Hadoop MapReduce的图分析引擎,其可以将Gremlin导航查询自动转化为MapReduce任务。从这个角度看,JanusGraph也可作为图计算引擎使用。
3.图数据库OrientDB
OrientDB 对于数据模式的支持也相对灵活,可以管理无模式数据(Schema-less),也可以像关系数据库那样定义完整的模式(Schema-full),还可以适应介于两者之间的混合模式(Schema-mixed)数据。在查询语言方面,OrientDB 支持扩展的 SQL 和 Gremlin 用于图上的导航式查询;值得注意的是,在2.2版本引入的 MATCH 语句实现了声明式的模式匹配,这类似于Cypher语言查询模式。
从数据管理角度来看,OrientDB 是一个功能上相对全面的数据库管理系统,除对图数据基本的存储和查询外,还支持完整的事务处理 ACID 特性、基于多主机复制模式(Multi-Master Replication)的分布式部署、对于多种操作系统的支持(由于使用 Java 开发)和数据库安全性支持等。根据2018年2月DB-Engines的排名,OrientDB排在最流行图数据库的第3位。
下面演示在Windows系统下使用OrientDB的Studio可视化管理界面建立和查询属性图的步骤:
步骤1。进入 OrientDB 安装目录,执行命令 bin\server.bat,启动 OrientDB 服务器;如果是第一次启动,则需要输入root用户的密码。
步骤2。在浏览器中访问http://localhost:2480,打开OrientDB Studio界面;如果弹出对话框,要求输入用户名和密码,可输入用户名admin、密码admin,以管理员身份登录。
步骤3。单击【NEW DB】按钮,新建数据库;在弹出的对话框中 Name 栏内输入要新建的数据库名称testgraph,单击【CREATE DATABASE】按钮。
步骤4。返回 Studio 首页,在“Database”下拉列表中选择刚刚新建的“testgraph”数据库,在“User”栏中输入用户名 root,在“Password”栏中输入 root 用户的密码,单击【CONNET】按钮;进入Studio管理操作界面。
步骤5。单击上方菜单栏的“GRAPH”菜单项,打开图编辑器(Graph Editor),在文本框中输入如图3-32所示的语句,构建图3-3中的属性图,建立的属性图的可视化展示如图3-33所示。

图3-32 OrientDB中建立属性图的语句
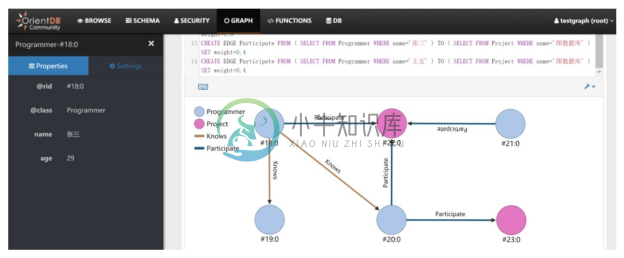
图3-33 OrientDB Studio的图编辑器
步骤6。单击上方菜单栏的“BROWSE”菜单项,要“查询张三(节点编号#18:0)认识(Knows)的程序员”,在文本框中输入 Gremlin 查询语句 g.v('#18:0').out('Knows'),单击【RUN】按钮执行查询,返回查询结果,如图3-34所示。
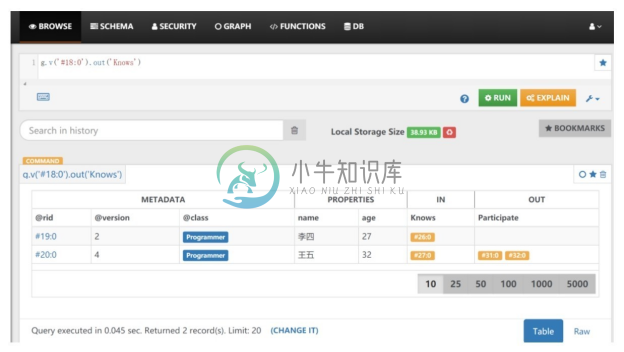
图3-34 OrientDB Studio中执行Gremlin查询
4.图数据库Cayley
Cayley使用Go语言开发,可以作为Go类库使用;对外提供REST API;具有内置的查询编辑器和可视化界面;支持多种查询语言,包括基于Gremlin的Gizmo、GraphQL和MQL;支持多种存储后端,包括键值数据库 Bolt、LevelDB,NoSQL 数据库 MongoDB、CouchDB、PouchDB、ElasticSearch,关系数据库PostgreSQL、MySQL等;具有良好的模块化设计,易于扩展,对新语言和存储后端有良好的支持。
Cayley的最新发布版本可以从其GitHub网站下载。下面演示在Windows系统中,使用Cayley的Web界面将RDF数据装载到默认的内存存储后端并进行查询的步骤。
步骤1。打开“命令提示符”,进入Cayley Windows版本的安装目录。
步骤2。执行命令cayley http,该命令将启动Cayley服务,以内置的内存存储作为后端数据库,并对外提供HTTP服务。
步骤3。在浏览器中打开 http://127.0.0.1:64210,进入 Cayley 的 Web 可视化查询界面。
步骤4。单击左侧栏的【Write】菜单项,在右侧的【Write an N-Quads file】栏选择要装载的RDF文件music_1000_triples.nt,单击【Write file】,如装载成功,右上方将出现提示。
步骤5。单击左侧栏的【Query】菜单项,在右侧上方文本框中输入查询:
g.V("<http://kg.course/music/artist_001>").In("<http://kg.course/music/track_artist>").All()
单击左侧栏上方的【Run Query】,如查询执行成功,则在右侧下方文本框返回JSON格式的查询结果。注意,这里使用的是基于Gremlin扩展的Gizmo查询语言,函数名称与标准Gremlin不尽相同。
步骤6。单击左侧栏的Visualize菜单项,在右侧上方文本框输入查询:
g.V("<http://kg.course/music/track_00001>").Tag("source").Out("<http://kg.course/music/track_album>").Tag("target").All()。
单击左侧栏上方的 Run Query,如查询执行成功,则在右侧下方显示查询结果的可视化图形:从源节点(source 标签)<http://kg.course/music/track_00001>出发,链接到目标节点(target标签),即查询结果节点,如图3-35所示。
需要指出的是,Cayley 虽然可以存储 N-Quads 格式的 RDF 文件,但目前尚不支持SPARQL查询。
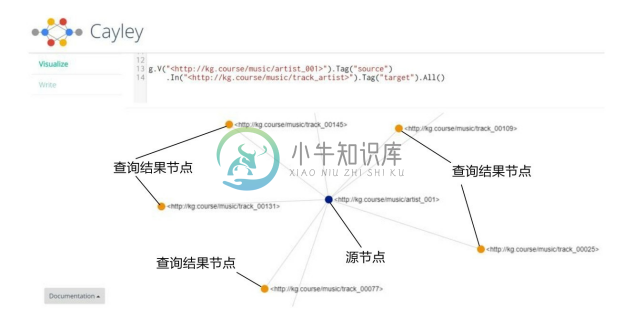
图3-35 Cayley查询结果的可视化
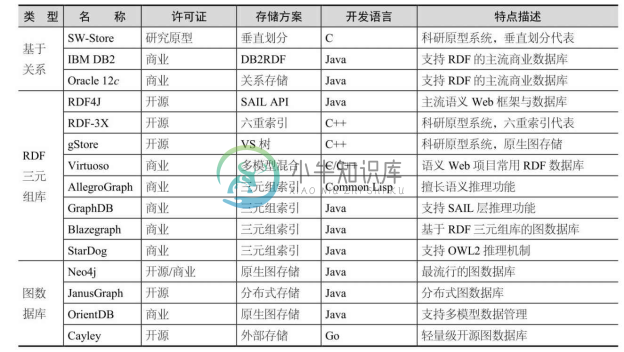
3.2.4 知识图谱数据库比较
下面对常用的知识图谱数据库进行比较,如表3-5所示。总体来讲,基于关系的存储系统继承了关系数据库的优势,成熟度较高,在硬件性能和存储容量满足的前提下,通常能够适应千万到十亿级三元组规模的管理。官方测评显示,关系数据库Oracle 12c配上空间和图数据扩展组件(Spatial and Graph)可以管理的三元组数量高达1.08万亿条[34] !当然,这样的性能效果是在 Oracle 专用硬件上获得的,所需软硬件成本投入很大。对于一般在百万到上亿级三元组的管理,使用稍高配置的单机系统和主流 RDF 三元组数据库(如Jena、RDF4J、Virtuoso等)完全可以胜任。如果需要管理几亿到十几亿以上大规模的RDF 三元组,则可尝试部署具备分布式存储与查询能力的数据库系统(如商业版的GraphDB和BlazeGraph、开源的JanusGraph等)。近年来,以Neo4j为代表的图数据库系统发展迅猛,使用图数据库管理 RDF 三元组也是一种很好的选择;但目前大部分图数据库还不能直接支持RDF三元组存储,对于这种情况,可采用数据转换方式,先将RDF预处理为图数据库支持的数据格式(如属性图模型),再进行后续管理操作。
表3-5 主要知识图谱数据库的比较

续表