
5.3 本体概念层的融合方法与技术
5.3.1 本体映射与本体集成
解决本体异构的通用方法是本体集成与本体映射[6-9] 。本体集成直接将多个本体合并为一个大本体,本体映射则寻找本体间的映射规则,这两种方法最终都是为了消除本体异构,达到异构本体间的互操作。如图5-1所示的本体映射和本体集成的示意图,图中不同的异构本体分别对应着不同的信息源。为了实现基于异构本体的系统间的信息交互,本体映射的方法在本体之间建立映射规则,信息借助这些规则在不同的本体间传递;而本体集成的方法则将多个本体合并为一个统一的本体,各个异构系统使用这个统一的本体,这样一来,它们之间的交互可以直接进行,从而解决了本体异构问题。
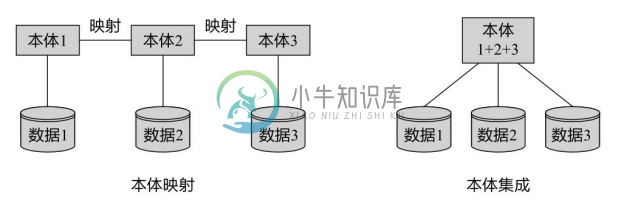
图5-1 本体映射和本体集成的示意图
既然不同系统间的互操作问题是本体异构造成的,因此,将这些异构本体集成为一个统一的本体是解决此类问题的一种自然想法。对于本体集成,根据实施过程的不同,又可以将其分为单本体的集成和全局本体-局部本体的集成两种形式。
1.基于单本体的集成
这种本体集成方法是直接将多个异构本体集成为一个统一的本体,该本体提供统一的语义规范和共享词汇。不同的系统都使用这个本体,这样便消除了由本体异构导致的互操作问题。显然,在本体集成的过程中产生了新的本体,因此也有人将本体集成看作一种生成新本体的过程。此外,集成过程通常利用了多个现有本体,因此这还是一种本体的重用[10] 。Pinto H S 等人将本体集成划分成一系列的活动[11] ,主要包括:决定本体集成的方式,即需要判断消除异构的单本体是应该从头建立,还是应该利用现有的本体来集成,这需要评估两种方法的代价和效率来进行取舍;识别本体的模块,即明确集成后的本体应该包含哪些模块,以便于在集成过程中对于不同的模块选择相关的本体;识别每个模块中应该被表示的知识,即需要明确不同模块中需要哪些概念、属性、关系和公理等;识别候选本体,即从可能的本体中选择可用于集成的候选本体;执行集成过程,基于上面的基础,根据一定的集成步骤完成本体集成。
这样的集成方法虽然看起来很有效,但在实际应用中往往存在明显的缺点。首先,使用这些异构本体的系统往往有着不同的功能和侧重点,这些系统之间通常不是等价或可相互替代的,某些系统能处理一些特定和深入的问题,某些系统则可能处理全面和基础的问题。这样,集成后的本体对于其中的一些系统来说可能过于庞大,况且它们往往只使用该集成本体的一部分。因此,这样的本体不方便系统使用,而且在涉及本体操作(如推理和查询)时会降低系统的效率。其次,单个本体的方法容易受到其中某个系统变化的影响[6] ,当某个系统要求改变本体以适应它的新需求时,集成的本体需要重新进行修改,这种修改往往并不简单,因为它很可能会影响到与之进行交互的其他系统,还需要与其他系统进行反复协商。所以,从这些方面能看出单本体的集成缺乏灵活性。
2.基于全局本体-局部本体的集成
为了克服单本体的本体集成方法的缺陷,另一种途径是采用全局本体-局部本体来达到本体集成。这种方法首先抽取异构本体之间的共同知识,根据它建立一个全局本体。全局本体描述了不同系统之间一致认可的知识。同时,各个系统可以拥有自己的本体,称为局部本体。局部本体既可以在全局本体的基础上根据自己的需要进行扩充,也可以直接建立自己特有的本体,但无论哪种方式,都需要建立局部本体与全局本体之间的映射[12,13] 。这样,局部本体侧重于特定的知识,而全局本体则保证不同系统间异构的部分能进行交互。这种方法既避免了局部本体存在过多的冗余,本体规模不会过于庞大,同时也达到了解决本体间异构的目的。每个局部本体可以独立开发,对它们进行修改不会影响其他的系统,只要保证与全局本体一致就可以。
但是全局本体—局部本体的本体集成方法也并不完美。除了需要维护全局本体和各个系统中的局部本体,为了保证全局本体和局部本体始终一致,还需要建立和维护它们之间的映射。但总的来说,全局本体—局部本体的集成方法较单本体的集成方法灵活。
本体映射和集成都是为了解决本体间的异构问题,虽然它们的事实过程存在着差别,但相互之间也存在着联系。一方面,在很多本体集成过程中,映射可看作集成的子过程。在单本体的本体集成中,需要分析不同本体之间的映射,才能够将它们集成为一个新的本体;在基于全局本体—局部本体的集成过程中,需要在局部本体和全局本体之间建立映射。另一方面,通过本体映射在异构本体间建立联系规则后,本体就能根据映射规则进行交互,因此,建立映射后的多本体又可视为一种虚拟的集成。
然而,集成本体的工作耗时费力,而且缺乏自动方法支持;随着多本体的变化,集成过程需要不断地重复进行,代价过高。此外,集成的本体对于不同的应用不具有通用性,缺乏灵活性。因此,本体集成不适合解决语义 Web 中分布和动态的多本体应用问题。实际上,大多应用只需要实现本体间的互操作就可以满足需求,完全的集成是没有必要的。本体映射通过建立本体间的映射规则达到本体互操作,其形式比较灵活,更能适应分布动态的环境。
5.3.2 本体映射分类
明确本体映射的分类是建立异构本体间映射的基础。虽然本体间的不匹配揭示了本体异构的原因,但通常的本体映射并不直接以各种不匹配准则来划分,因为那样的映射分类过于抽象和宽泛,不方便实现。尽管很多研究者在本体映射上做了大量的相关工作[9] ,但对于本体映射的分类这个基本问题却缺少系统的总结、分析和论述。这里在总结前人研究的基础上,从三个角度来探讨本体映射的分类问题,即映射的对象、映射的功能以及映射的复杂程度。
1.映射的对象角度
通过这个角度的分类,明确映射应该建立在异构本体的哪些成分之间。
本体间的不匹配是造成本体异构的根本原因,这种不匹配可分为语言层和模型层两个层次。从语言层来说,目前大多数的本体采用几种流行的本体语言表示,如 OWL 或RDF(S),很多本体工具都具有在这些语言之间进行相互转换的功能。由于不同本体语言之间表达能力上的差异,这种转换有时会造成本体信息的损失。因此,语言间的转换应该尽可能指向表达能力强的语言,以减少信息的损失。而实际上,通常的本体映射很少考虑语言层次上的异构。将不同语言表示的本体转换为相同的表示形式能方便映射处理。通常,这种转换带来的信息损失不应该对映射结果造成明显的影响。而从模型层来说,虽然模型层的不匹配划分能方便对本体映射进行统一处理,但对实际应用来说,依据模型层的不匹配来划分本体映射过于抽象。实际上,大多映射研究直接从组成本体的成分出发,即由于本体主要由概念、关系、实例和公理组成,本体间的映射应建立在这些基本成分之上。
建立异构本体的概念之间的映射是最基本的映射,因为概念是本体中最基本的成分,没有概念,其他的本体成分无从谈起。所以,概念间的映射是最基本的和必需的。对于本体中的关系来说,由于它可表示不同概念之间的关系或描述某个对象的赋值,对于很多应用来说(如查询),往往需要借助这些关系之间的映射进行信息交互。因此,关系之间的映射也很重要。需要注意的是,由于有些关系连接两个对象,而有些关系连接对象和它的赋值(即概念的属性),这两类关系的映射处理方法可能会有所不同。
不同本体之间的实例也会出现异构,例如不同的实例名实际上表示同一个对象。由于语义 Web 包含大量的实例,在有些情况下往往需要考虑实例的异构,并需要建立异构实例之间的映射。为了检查实例之间是否等价,目前的方法基于属性匹配或逻辑推理[14] 。但是,逻辑推理的方法通常很耗时,而属性匹配的方法又很可能得到不确定的答案。Xu Baowen 等人提出了一种检查实例等价的框架[15] ,这种方法同时使用了属性匹配和逻辑推理两种方法,并利用一种基于不相交集合并的算法来加速推理过程。但总的来说,由于实例之间的映射情况比其他对象的映射简单,但是实例的数目太多,处理起来非常耗时,因此很多映射工作并不着重考虑实例上的映射。
公理是本体中的一个重要成分,它是对其他本体成分的约束和限制。通常,一个公理由一些操作符和本体成分组合而成。因此,如果两个本体使用的表示语言都支持同样的操作符,那么公理之间的映射便可以转换为其他成分之间的映射。因此,通常并不需要考虑公理之间的映射。
综上所述,从映射的对象来看,可将本体映射分为概念之间的映射和关系之间的映射两类,其中概念之间的映射是最基本的映射。除非有特殊的要求,一般不考虑针对实例或公理之间的映射。
2.映射的功能角度
通过这个角度的分类,进一步明确应该建立具有何种功能的本体映射。
确定在本体的何种成分之间建立映射并不足够,还需要进一步明确这样的映射具有什么功能。例如,一些映射声明不同本体间的两个概念是相等的,而一些则声明不同本体间的两个关系是互逆的。现有大多数本体映射研究的问题在于只考虑几种最基本和常见的映射功能,如概念间的等价和包含,以及关系间的等价等,而没有充分考虑异构本体间各种有用的映射功能。实际上,本体的概念或关系之间可能存在的映射功能种类很多,Wang Peng 等人以概念间的映射和关系间的映射为基础,从功能上归纳出11种主要的本体映射,并称这些映射为异构本体间的桥[16] :表示概念间映射的桥包括等价(Equal)、同形异义(Different)、上义(Is-a)、下义(Include)、重叠(Overlap)、部分(Part-of)、对立(Opposed)和连接(Connect)共8种;表示关系间映射的桥等价(Equal)、包含(Subsume)和逆(Inverse)3种。这11种桥基本能描述异构本体间具有的映射功能。
最基本的映射功能是等价映射,是为了建立不同本体的成分之间的等价关系。等价映射声明了概念之间和关系之间的对应,异构本体的等价成分之间在互操作过程中可以直接相互替代。同形异义的映射能够指出表示名称相同的本体成分实际上含义是不同的。上义和下义映射则说明了概念之间和属性之间的继承关系,关系间的包含映射对于关系来说也具有同样的功能。重叠映射表示概念之间的相似性。对立映射表示概念之间的对立。同样,逆映射表示关系之间的互逆。概念上的部分映射则表示了来自不同概念间的个体具有整体—部分关系。此外,通过一些特殊的连接映射,还能将不同的本体概念相互联系起来。
从功能上归纳和区分上述映射具有重要的意义。首先,不同功能的映射,其发现的方法和建立的难度都具有差别,即使是同一成分之间的映射,不同的映射功能都会影响着寻找映射的方法和过程;有的映射功能同时适用于概念和关系,在不同成分上发现这样的映射所使用的方法可能有相似性;有的映射功能则只针对特定的成分,发现这样的映射可能需要借助特殊的方法。其次,区分具体的映射功能对于实际应用来说非常重要,不同功能的映射在处理本体互操作中扮演的角色会有不同,有的映射仅仅为了建立本体之间的数据转换的规则,有的映射还能用于进行跨本体的推理和查询应用。
3.映射的复杂程度角度
通过这个角度的分类,明确什么形式的映射是简单的,什么形式的映射是复杂的。
本体间的映射还具有复杂和简单之分,这需要同时考虑映射涉及的对象和映射具有的功能。实际上,复杂映射和简单映射的界限很难界定。通常,将那些基本的、必要的、组成简单的和发现过程相对容易的映射称作简单映射;将那些不直观的、组成复杂并且发现过程相对困难的映射称为复杂映射。
这里的复杂映射同时考虑映射对象和映射功能。从映射对象上,将那些包含复杂概念的映射看作是复杂映射,这里的复杂概念指通过概念的并、交和非等算子构成的复合概念,涉及这一类复杂概念的映射寻找方法相对单个的原子概念来说较为困难。而由于关系的映射发现方法通常都不容易,因此无论是原子关系还是复杂关系上的映射均看作复杂映射。从功能上看,除概念和关系上的等价映射以及概念上的上义和下义外,其余的映射功能都属于复杂映射。基于这种思想,本体映射的分类如表5-1所示,其中“+”表示这种映射存在,“×”表示这种映射不存在,背景为深色表示这种映射是复杂映射。从表中可以看出,存在的本体映射中大部分都属于复杂映射。然而,目前的研究表明,大多数的本体映射工作都是针对简单映射的,针对复杂映射的探讨并不多。
表5-1 本体映射的分类

Noy N F将基于本体的语义集成研究划分为三个层次[17] :①发现映射,即给定两个本体,怎样寻找它们之间的映射;②表示映射,即对于找到的映射,应该能够进行合理表示,这种表示要方便推理和查询;③使用映射,即一旦映射被发现和表示后,需要将它使用起来,如进行异构本体间的推理和查询等。接下来从这些层次入手,逐步阐述映射的发现、表示和应用问题。
5.3.3 本体映射方法和工具
在确定本体映射的分类后,最重要也是最困难的任务在于如何发现异构本体间的映射。尽管本体间的映射可以通过手工建立,但非常耗时,而且很容易出错[18] 。因此,目前的研究侧重于开发合理的映射发现方法和工具,采用自动或半自动的方式来构建。
尽管不同的本体映射方法使用的技术不同,但过程基本是相似的。图5-2描述了本体映射生成的过程,为了简化起见,图中只使用两个不同的本体 O1 和 O2 。总的来说,本体映射的过程可分为三步:

图5-2 本体映射生成的过程
① 导入待映射的本体。待映射的本体不一定都要转换为统一的本体语言格式,但是要保证本体中需要进行映射的成分能够被方便获取。
② 发现映射。利用一定的算法,如计算概念间的相似度等,寻找异构本体间的联系,然后根据这些联系建立异构本体间的映射规则。当然,如果映射比较简单或者难以找到合适的映射发现算法,也可以通过人工来发现本体间的映射。
③ 表示映射。当本体之间的映射被找到后,需要将这些映射合理地表示起来。映射的表示格式是事先手工制定的。在发现映射后,需要根据映射的类型,借助工具将发现的映射合理表示和组织。
这三个步骤是一个粗略但却通用的本体映射过程,实际应用中的很多映射算法对于每一个阶段都有更详细的描述。
为了建立本体映射,不同的研究者从不同角度出发,采用不同的映射发现方法来寻找本体间的映射。同时,不同的映射发现方法能处理的映射类型和具体过程都有很大差别[17] 。从已有的映射方法以及相关的工具来看,发现本体映射的方法可分为四种[19,20] :①基于术语的方法,即借助自然语言处理技术,比较映射对象之间的相似度,以发现异构本体间的联系;②基于结构的方法,即分析异构本体之间结构上的相似,寻找可能的映射规则;③基于实例的方法,即借助本体中的实例,利用机器学习等技术寻找本体间的映射;④综合方法,即在一个映射发现系统中同时采用多种寻找本体映射的方法,一方面能弥补不同方法的不足,另一方面还能提高映射结果的质量。
根据使用技术的不同,下面分别介绍一些典型的本体映射工作。很多映射工作可能同时采用了多种映射发现技术,如果其中的某一种技术较为突出,则将这个工作划分到这一种技术的分类下;如果几种技术的重要程度比较均衡,则将这样的工作划分为综合方法。此外,实际的研究和应用表明,仅仅是用基于术语的方法很难取得满意的映射结果,为此,很多方法进一步考虑了本体结构上的相似性来提高映射质量,所以将基于术语和基于结构的映射发现方法放在一处进行讨论。
1.基于术语和结构的本体映射
从本体中术语和结构的相似性来寻找本体映射是比较直观和基础的方法。这里先介绍这种方法的思想,然后探讨一些典型和相关的工作。
(1)技术综述
1)基于术语的本体映射技术。 这类本体映射方法从本体的术语出发,比较与本体成分相关的名称、标签或注释,寻找异构本体间的相似性。比较本体间的术语的方法又可分为基于字符串的方法和基于语言的方法。
① 基于字符串的方法。 基于字符串的方法直接比较表示本体成分的术语的字符串结构。字符串比较的方法有很多,Cohen W 等人系统地分析和比较了各种字符串比较技术[21] 。主要的字符串比较技术如下。
(a)规范化。 在进行严格字符串比较之前,需要对字符串进行规范化,这能提高后续比较的结果。规范化操作主要包括:大小写规范化,即将字符串中的每个符号转换为大写字母或小写字母的形式;消除变音符,即将字符串中的变音符号替换为它的常见形式,如Montréal 替换为 Montreal;空白正规化,即将所有的空白字符(如空格、制表符和回车等)转换为单个的空格符号;连接符正规化,包括正规化单词的换行连接符等;消除标点,在不考虑句子的情况下要去除标点符号;消除无用词,去除一些无用的词汇,如“to”和“a”等。
这些规范化操作主要针对拉丁语系,对于其他的语言来说,规范化过程会有所不同。
(b)相似度量方法。 在规范字符串的基础上,能进一步度量不同字符串间的相似程度。常用的字符串度量方法有:汉明距离、子串相似度、编辑距离和路径距离等。
如果两个字符串完全相同,它们间的相似度为1;如果字符串间不存在任何相似,则相似度为0;如果字符串间存在部分相似,则相似度为区间(0,1)中的某个值。
一种常用来比较两个字符串的直接方法是汉明距离,它计算两个字符中字符出现位置的不同。
定义5.1 对于给定的任意两个字符串s和t,它们的汉明距离相似度定义为:
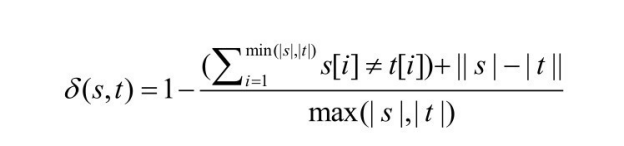
相似的字符串间往往具有相同的子串,子串检测就是从发现子串来计算字符串间的相似度,它的定义如下。
定义5.2 任意两字符串s和t,如果存在两个字符串p和q,且s=p+t+q或t=p+s+q,那么称t是s的子串或s是t的子串。
还可进一步精确度量两字符串包含共同部分的比例,即子串相似度。
定义5.3 子串相似度度量任意两个字符串s和t间的相似度δ,令x为s和t的最大共同子串,则它们的子串相似度为:
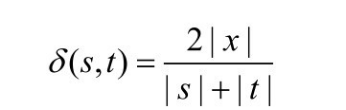
字符串间的相似度还能通过编辑距离来度量。两字符串之间的编辑距离是指修改其中一个使之与另一个相同所需要的最小操作代价。这些编辑操作包括插入、删除和替代字符。
定义5.4 给定一个字符串操作集合 op 和一个代价函数 w,对于任意一对字符串 s 和t,存在将 s转换为 t的操作序列集合,两字符串间的编辑距离δ(s,t)是将 s转换为 t 的最小操作序列的代价和:
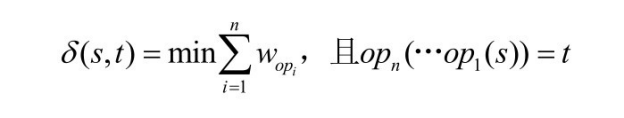
注意,这里给出的编辑距离没有正规化,即δ的值可能不在区间[0,1]。显然,编辑距离越大,表示两字符串的相似程度越小。编辑距离是最基本的判断字符串间相似度的指标,以它为基础,能构造出很多更复杂的相似度度量公式,这里不一一介绍。
除了直接比较单个术语的字符串相似,还可以在比较时考虑与之相关的一系列的字符串。路径比较便是这类方法中的一种。例如,比较两个概念的相似度时,可以将它们的所有父概念集中起来,并在相似度计算中考虑这些路径上的概念。
定义5.5 给定两个字符串序列![]() 和
和![]() ,它们之间的路径距离计算如下:
,它们之间的路径距离计算如下:
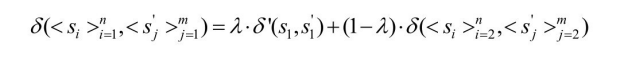
式中,δ’是某种字符串度量函数,并且λ∈[0,1];当比较的两条路径出现空路径时,有![]() 。
。
②基于语言的方法。 基于语言的方法依靠自然语言处理技术寻找概念或关系之间的联系。这类方法又可分为内部方法和外部方法,前者使用语言的内部属性,如形态和语法特点,后者则利用外部的资源,如词典等。
内部方法在寻找术语间的映射时利用词语形态和语法分析来保证术语的规范化。它寻找同一字符串的不同语言形态,如 Apple 和 Apples 等。寻找词形变化的算法很多,最著名的是Porter M F提出的Stemming算法[22] 。
外部方法利用词典等外部资源来寻找映射。基于词典的方法使用外部词典匹配语义相关的术语。例如,使用WordNet能判断两个术语是否有同义或上下义关系。
尽管基于术语的相似度度量方法很多,但是根据它很难得到比较好的映射结果,一般仅能判断概念或关系之间等价的可能程度,而对于发现其他功能的映射来说,基于术语的方法难以达到满意的效果。
2)基于结构的本体映射技术。 在寻找映射的过程中,同时考虑本体的结构能弥补只进行术语比较的不足,提高映射结果的精度。基于结构的方法又可分为内部结构和外部结构,前者考虑本体的概念或关系的属性和属性值的数据类型等,后者则考虑与其他成分间的联系。
① 内部结构。 基于内部结构的方法利用诸如属性或关系的定义域、它们的基数、传递性或对称性来计算本体成分之间的相似度。通常,具有相同属性或者属性的数据类型相同的概念之间的相似度可能性较大。
② 外部结构。 比较两本体的成分之间的相似也可以考虑与它们相关的外部结构,例如,如果两个概念相似,它们的邻居也很可能是相似的。从本体外部结构上判断本体成分的相似主要借助人们在本体使用过程中所获得的一些经验。有一些常用来判断本体成分相似的准则,这些准则包括:(C1)直接超类或所有的超类相似;(C2)兄弟相似;(C3)直接子类或所有的子类相似;(C4)所有或大部分后继(不一定是子类,可能通过其他关系连接)相似;(C5)所有或大部分的叶子成分相似;(C6)从根节点到当前节点的路径上的实体都相似。
对于通过 Part-of 关系或 Is-a 关系构成的本体,本体成分之间的关系比较特殊和常见,可以利用一些特定的方法来判断结构上的相似[23] 。
计算概念之间的相似也可以考虑它们之间的关系。如果概念 A 和 B 通过关系 R 建立联系,并且概念A’和B’间具有关系R',如果已知B和B’以及R和R’分别相似,则可以推出概念 A 和A’也相似[24] 。然而,这种方法的问题在于如何判断关系的相似性。关系的相似性计算一直是一个很困难的问题。
外部结构的方法无法解决由于本体建模的观点不同而造成的异构,如对于同一个概念“Human”,本体 O1 将它特化为两个子类“Man”和“Woman”,而本体 O2 却将它划分为“Adult”和“Young_Person”。基于结构的方法难以解决这种不同划分下的子类之间的相似度问题。
(2)方法和工具
1)AnchorPROMPT。 PROMPT 是 Stanford 大学开发的一套本体工具集[25] ,其中包括:①一个交互式本体集成工具 iPROMPT,它帮助用户进行本体集成操作,能够提供什么成分能被合并的建议,能识别集成操作中造成的不一致问题和其他潜在的错误,并建议可能的策略来解决这些问题,为了达到集成本体的目的,iPROMPT 需要发现本体间的映射;②一个寻找本体间相似映射的工具AnchorPROMPT,它扩展了iPROMPT发现映射的性能,能发现更多 iPROMPT 不能识别的本体间的相似;③一个本体版本工具PROMPTDiff,它比较本体的两个版本,识别它们之间结构上的不同;④一个从大本体抽取语义完全的子本体工具 PROMPTFactor,它从现有本体创建一个新本体,并能保证结果子本体是良构的。除 AnchorPROMPT 直接处理映射外,其他工具都并非为了发现本体映射,但本体映射在每个工具中具有重要作用。PROMPT 的各个工具之间并非孤立存在,而是相互联系的,它们共享数据结构,并在需要时能相互借用算法。目前,PROMPT 的这些工具已集成到Protégé系统中。
本体映射是解决很多多本体问题的基础。为了发现本体间的映射,Noy N F 等人于1999年就开发了SMART算法[26,27] ,该方法通过比较概念名的相似性,识别异构本体间的等价概念。AnchorPROMPT算法正是以SAMRT为基础,通过扩展SMART而得到的[28] ;它采用有向图表示本体,图中包括本体中的概念继承和关系继承等信息;算法输入两个本体和它们的相关术语对集合,然后利用本体的结构和用户反馈来判断这些术语对之间的映射。
① AnchorPROMPT 的思想。 AnchorPROMPT 的目标是在术语比较的基础上利用本体结构进一步判断和发现可能相似的本体成分。AnchorPROMPT 的输入是一个相关术语对的集合,其中每对术语分别来自两个不同本体,这样的术语对称为“锚”。术语对可以利用iPROMPT工具中的术语比较算法自动生成,也可以由用户提供。AnchorPROMPT算法的目标是根据所提供的初始术语对集合,进一步分析异构本体的结构,产生新的语义相关术语对。
AnchorPROMPT将每个本体O视为一个带边有向图G。O中的每个概念C表示图中的节点,每个关系 S 是连接相关概念 A 和 B 之间的边。图中通过一条边连接的两节点称为相邻节点。如果从节点 A 出发,经过一系列边能到达节点 B,那么 A 和 B 之间就存在一条路径。路径的长度是边的数目。
为发现新的语义相关术语对,AnchorPROMPT 遍历异构本体中由“锚”限定的对应路径。AnchorPROMPT 沿着这些路径进行比较,以寻找两个本体间更多的语义相关术语。例如,假设现有两对相关术语对:概念对(A, B)和概念对(G, H)。它表示本体 O1 中的概念 A 和本体 O2 中的概念 B 相似;同样,O1 中的 G 和 O2 中的 H 也相似,如图5-3所示。图中显示了本体O1 中概念A到G之间存在一条路径以及本体O2 中概念B到H之间存在一条路径;两本体间的实线箭头表示初始的“锚”,虚线箭头表示路径上可能相关的术语对。AnchorPROMPT 算法并行遍历两条路径,对于在同样的步骤下到达的概念对,算法同时增加它们之间的相似度分数。例如,当遍历图5-3中的路径后,算法会增加概念对(C, D)之间和(E, F)之间的相似度分数。对所有起始节点和终止节点间的全部路径,算法重复这个过程,并累计概念对上的相似度分数。可见,AnchorPROMPT 算法基于这样的直觉:如果两对术语相似,并且存在着连接它们的路径,那么这些路径中的节点成员通常也是相似的。因此,根据最初给定的相关术语对的小集合,AnchorPROMPT 算法能够产生本体间大量可能的语义相似术语对。
② AnchorPROMPT算法。 为说明 AnchorPROMPT 的工作原理,这里以两个描述病人就诊的异构本体为例,如图5-4所示。对于这样的两个本体,假设输入的初始相关术语对是(TRIAL, Trial)和(PERSON, Person)。这样的术语对利用基本的术语比较技术能很容易识别出来。
根据输入的相关术语对,算法能寻找到相关术语对之间的路径集合。对于上面的两对相关术语,在本体 O1 中存在一条“TRIAL”和“PERSON”之间的路径,在本体 O2 中也存在二条从“Trial”到“Person”之间的路径。在实际应用中,这样的路径数目可能有很多,为了减少大量的比较操作,可以通过预先定义路径长度来限制路径的总数,如规定只考虑长度小于5的路径等。
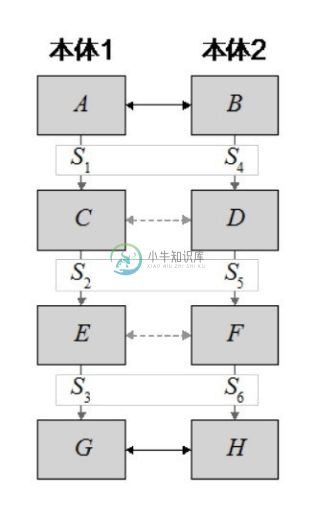
图5-3 遍历术语对间的路径
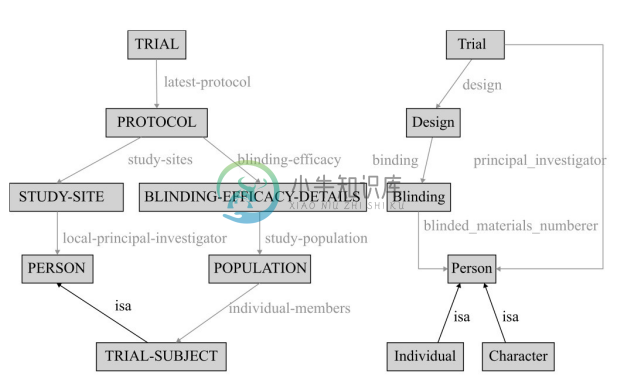
图5-4 两个描述病人就诊的异构本体
这里考虑 O1 中的路径 Path1:TRIAL→PROTOCOL→STUDY-SITE→PERSON 和 O2 中的路径Path2:Trial→Design→Blinding→Person。
当 AnchorPROMPT 遍历这两条路径时,它增加路径中同一位置的一对术语的相似度分数。在这个例子中,算法增加这两对概念的相似度分数,即概念对(PROTOCOL, Design)和(STUDY-SITE, Blinding)。
AnchorPROMPT 算法重复以上过程,直到并行遍历完相关术语对之间的这种路径,每次遍历都累加符合条件的概念对的相似度分数。结果,经常出现在相同位置的术语对间的相似度分数往往最高。
(a)等价组。在遍历本体图中的路径时,AnchorPROMPT 区别对待连接概念间的继承关系与其他普通关系,因为如把概念间的 Is-a 关系和普通关系同样看待, AnchorPROMPT的方法不能很好地利用这种继承关系。与普通关系不同,Is-a关系连接着已经相似的概念,如图5-5中的“PROTOCOL”和“EXECUTED-PROTOCOL”,事实上它们描述了概念之间的包含。AnchorPROMPT 算法将这种通过 Is-a 关系连接的概念作为一个等价组看待。考虑图5-5中从 TRIAL 到 CROSSOVER 的路径,其中将“PROTOCOL”和“EXECUTED-PROTOCOL”作为一个等价组,并用括号来做区别,这样的一条路径写为 Path:Trial→ [EXECUTED-PROTOCOL,PROTOCOL]→TREATMENT-POPULATION→ CROSSOVER。
这样,AnchorPROMPT 将等价组看作路径上的单个节点。等价组节点的入边是其中每个成员的入边的并;相似地,它的出边是每个成员的出边的并。显然图5-5中等价组节点有两条入边和一条出边。等价组的大小是节点中包括的概念总数,但对于AnchorPROMPT算法来说,它将这些概念视为一个节点。
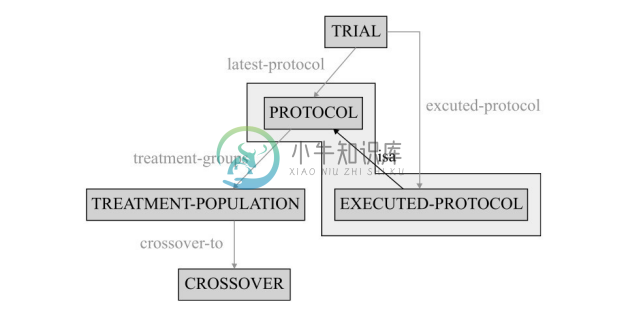
图5-5 路径中的等价组
(b)相似度分数。给定两个术语:来自本体 O1 中的概念 C1 和本体 O2 中的概念 C2 ,计算它们之间相似度分数S(C1 , C2 )的过程如下:
步骤1:生成长度小于给定参数 L 的全部路径集合,这些路径连接着输入的两本体中的锚。
步骤2:从步骤1生成的路径集合中,生成所有可能的等长路径对的集合,每一对路径中的一条来自O1 ,另一条来自O2 。
步骤3:在步骤2生成的路径对基础上,对于路径中处于相同位置的节点对 N1 和N2 ,为节点中的所有概念对之间的相似度分加上一个常数X。
如果概念 C1 和 C2 出现在上述路径中,则它们之间的相似度分数 S(C1 , C2 )反映了 C1 和C2 出现在路径中的相同位置的频繁程度。
当进行比较的节点包含等价组时,增加相似度分数的情况有所不同。例如,对于处于同一位置的一对节点(A1 , [B2 , C2 ]),需要分析如何对(A1 , B2 )以及(A1 , C2 )打分。这个问题在接下来的部分进行分析。
根据上述算法,AnchorPROMPT 算法生成很多可能的相似术语对,将这些术语对的相似分数进行排序,去除一些相似分数较低的术语对,就得到语义相关的术语对。
③ AnchorPROMPT评估。 Noy N F等人对AnchorPROMPT进行了一系列的评估试验,得到了一些有用的经验。
(a)等价组大小。试验表明,当等价组大小最大值为0(0是一个特殊的标记,表示算法不区分概念间的继承关系和普通关系 )或1(节点只包含单个概念,但区分概念间的继承关系和普通关系)时,87%的试验没有任何结果,不生成任何映射。当等价组的最大尺寸为2时,只有12%的试验没有结果。因此,在随后的试验中设定等价组的最大尺寸大小为2。
(b)等价组成员的相似度分数。为评价等价组成员如何打分合理而做了两类试验。第一类试验中对节点中的所有成员都加 X 分;而在第二类试验中为等价组中的成员只加 X/3或X/2的分数不等。试验结果表明,对等价组成员打分不同能将结果的准确率提高14%。
(c)锚的数目和路径最大长度。在大量的试验中表明,并非输入的锚数量越多和规定的最大路径长度越大能得到越好的映射结果,算法执行结果的正确率总体提高不明显,但运行时间明显增长[29] 。试验表明,当最大长度路径设为2时,能获得最好的正确率。当限制路径最大长度为3时,平均正确率为61%;当最大长度提高到4时,正确率只有少量的提升,达到65%。
④ AnchorPROMPT的讨论。 当AnchorPROMPT算法考虑路径长度为1时,如果概念A和A’相似以及B和B’相似,则认为连接A和B的关系S和连接A’和B’的关系S’相似。以此类推,可以得到路径上更多的关系对也是相似的。实际上,AnchorPROMPT 算法正是基于这样的假设:本体中相似的术语通常也通过相似的关系连接。在实际应用中,随着路径的过长,这个假设的可行性就越小,因此生成结果的精度反而会降低。而路径长度过短又可能使得路径上不包含任何的术语对,例如路径长度为1时,算法生成的结果和只使用术语比较技术的iPROMPT是一样的。AnchorPROMPT其他方面的讨论如下。
(a)减少负面结果的影响。概念间的相似度分数是一个累加值。两个不相关的术语可能出现在某一对路径的相同位置,但对于所有的路径来说,这两个不相关的术语总出现在不同路径对的同一位置上的概率很小。AnchorPROMPT 累加遍历所有路径过程中对应概念对的相似度分数,这能够消除这类负面结果的影响。试验中可以设定一个相似度分数的阈值,便于去掉相似度分数小于阈值的术语对。试验表明,AnchorPROMPT 的确可以去除大多数的这类术语对。
(b)执行本体映射。AnchorPROMPT 建立了术语之间的映射,它的结果可以提供给本体合并工具(如iPROMPT)或其他的本体应用直接使用。
(c)局限性。AnchorPROMPT 的映射发现方法并非适用于所有的本体。当两个本体间的结构差别很大时,该方法处理的效果并不好。此外,当一个本体对领域描述得比较深入时,而另一个本体描述同样的领域比较肤浅时,AnchorPROMPT 算法获得的结果也不令人满意。
⑤ AnchorPROMPT 的总结。 AnchorPROMPT 是基于结构的本体映射发现技术中的一项典型工作,它以基于术语技术得到的本体映射结果为基础,进一步分析本体图的结构相似性,从而发现更多的本体映射。
由 AnchorPROMPT 算法的过程可以看出,该算法只能发现异构本体原子概念间的等价映射,以及少量原子关系间的等价映射。对于复杂概念或复杂关系间的本体映射, AnchorPROMPT 是无法处理的。从技术上说,AnchorPROMPT 算法是基于一种直观的经验,缺乏严格的理论依据。
2)iPROMPT。 PROMPT 工具中的 iPROMPT 利用术语技术发现不同本体间的映射,并根据映射结果给出一系列本体合并建议,用于指导用户进行本体合并。
iPROMPT 从语言角度判断本体间概念或关系的相似。然后以这些初始的术语相似为基础,执行合并算法完成本体合并的任务。在合并本体时要与用户进行交互,iPROMPT 的本体合并过程如图5-6所示,步骤和算法如下。
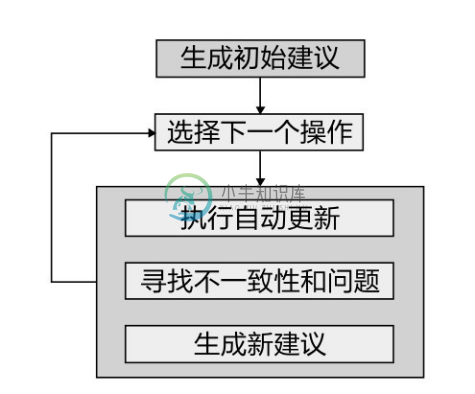
图5-6 iPROMPT的本体合并过程
步骤1:基于概念名或关系名相似,识别出潜在的合并候选术语,然后为用户生成一个可能的合并操作建议列表。
iPROMPT 中的操作包括合并概念、合并关系、合并实例、拷贝单个的概念和拷贝一系列的概念等。
步骤2:从合并建议列表中选择一条建议(也可以由用户直接定义一条合并操作),系统执行建议的合并操作,并自动发现由于这样的操作对整个合并建议列表产生的变化,即实现建议列表的更新,然后系统自动判断新的本体合并建议列表中的冲突和潜在的其他问题,并寻找可能的解决方案,经过这些处理,系统生成新的且无冲突的建议列表。
当执行合并操作后,iPROMPT 检查合并后本体中的不一致性和潜在问题,主要包括:①名字冲突。合并后的本体中的每个术语名字必须是唯一的,例如一个拷贝本体 O1 中的概念“Location”到本体 O2 时,可能 O2 中存在一个同名的关系,这便出现了名字冲突。这样的冲突可以通过重命名来解决。②当在本体间拷贝属性时,如果被拷贝属性的值域和定义域中包含概念,且这些概念并不在本体中存在时,便出现了不一致问题。在这种情况下可以考虑删除这些概念或为本体增加这些概念来解决。③概念继承冗余,本体合并可能造成一些概念继承连接出现冗余,即有些概念继承路径是不必要的。对于这种问题, iPROMPT建议用户删除一些多余的概念来避免冗余。
Noy N F等人从准确率和召回率来评估iPROMPT算法的效果。这里的准确率是指用户遵循 iPROMPT 给出的建议占所有建议的比例;召回率是指用户实际执行的合并操作占工具给出的建议的比例。试验表明,iPROMPT 算法的平均准确率是96.9%,平均召回率是88.6%。
总的来说,在发现本体映射的过程中,iPROMPT 主要利用术语相关性计算方法寻找本体间概念或概念的相关属性的映射,因此,它只能发现有限的概念间或属性间的等价映射。
3)MAFRA。 MAFRA 是处理语义 Web 上分布式本体间映射的一个框架[30-32] ,该框架是为了处理、表示并应用异构本体间的映射。MAFRA 引入了语义桥和以服务为中心的思想。语义桥提供异构本体间数据(主要是实例和属性值)转换的机制,并利用映射提供基于分布式本体的服务。
MAFRA 体系结构如图5-7所示,其结构由水平方向和垂直方向的两个模块组成。水平方向的五个模块具体包括:①正规化。要求各个本体必须表示为一个统一形式(如RDF、OWL 等),以消除不同源本体之间语法和语言上的差异。MAFRA 的正规化过程还包括一些词语方面的处理,如消除常见词和扩展缩写等。②相似度。MAFRA 利用多种基本的术语或结构相似度方法来获取本体成分之间的关系。在计算概念间关系的过程中还考虑了概念的属性。③语义桥。根据本体成分间的相似度,利用语义桥来表示本体映射。这些语义桥包括表示概念桥和属性桥,前者能实现实例间转换,后者表示属性间转换的规则。还能利用推理建立一些隐含的语义桥。④执行。在获得本体间交互的请求时,利用语义桥中的映射规则完成实例转换或属性转换。⑤后处理。映射执行产生的转换结果需要进一步处理,以提高转换结果的质量,例如,需要识别转换结果中表示同一对象的两个实例等。
垂直方向四个模块具体包括:①演化。当本体发生变化时,对生成的“语义桥”进行维护,即同步更新语义桥。②协同创建。对于某些本体成分可能存在多个不同的映射建议,此时一般通过多个用户协商,选择一致的映射方案。③领域限制和背景知识。给出一些领域限制能避免生成不必要的映射;提供一些特定领域的背景知识,如同义词典能提高映射结果的质量。④用户界面交互。给出图形化的操作界面能让本体建立的过程更容易。
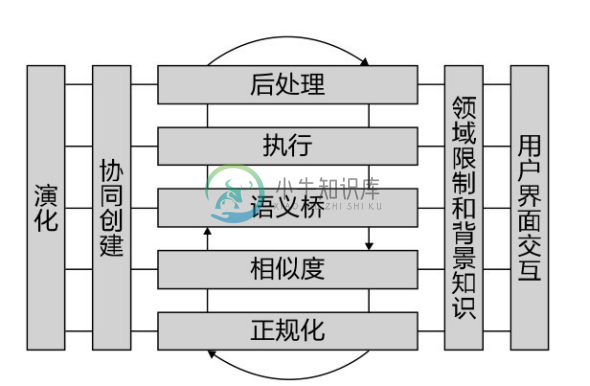
图5-7 MAFRA体系结构
MAFRA 主要给出一套本体映射方法学,用来表示映射,将映射划分为概念桥和属性桥两类,并利用映射实现异构本体间的数据转换。尽管MAFRA支持通过手工建立一些复杂的映射,但它缺乏自己特有的映射发现技术。因此,MAFRA 更多只是一个处理异构本体映射的框架。
4)ONION。 ONION是Mitra P等人设计的一个解决本体互操作的系统[33-34] 。该系统采用半自动算法生成本体互操作的映射规则,解决本体之间的异构。
为了使异构本体具有统一格式,ONION 采用图的形式表示本体,具体保存时采用RDF 的格式。本体图中包含了有五种明确定义的语义关系:{SubClassOf; PartOf;AttributeOf; InstanceOf; ValueOf}。本体映射的生成是半自动的,生成算法将可能的映射结果提供给专家,专家可以通过设定相似度阈值或直接选择的形式来接受、修改或改变建议。专家还可以添加新的映射,以补充算法无法生成的映射规则。
ONION 的映射生成过程同时使用了术语匹配和本体图匹配。对于每一种术语匹配算法,专家为其分配一定的置信度,最终的术语匹配结果是几个算法结果的综合[35] 。在计算两个本体的映射过程中,很多算法都需要比较两个本体之间所有可能的术语对,对于大本体而言,这样的计算过程非常耗时。为避免这种问题,ONION 在计算本体映射时提出一个“窗口算法”,即算法首先将每个本体划分为几个“窗口”,一个“窗口”包括本体中的一个连通子图。在发现映射的过程中,并不对所有可能的“窗口”对都进行比较,比较只在那些可能会有映射的窗口对之间进行。“窗口算法”虽然降低了比较过程的时间复杂度,但同时也可能造成映射的遗漏。
ONION 的映射发现算法分为非迭代算法和迭代算法两种。①非迭代算法,利用几种语言匹配器来发现本体术语间的关系,最后将各个匹配器发现的相似度进行综合,并将结果提供给本体专家进一步确认。在这个过程中,专家可以事先设定一些阈值,使算法自动去除一些不可能的相似度结果。同时,非迭代算法还借助词典(如 Nexus 和 WordNet),利用字典中的同义词集来提高映射发现的映射质量。②迭代算法,迭代寻找本体子图间结构上的同态以得到相似的概念,每一次迭代都利用上一次生成的映射结果。ONION 的试验表明,如果映射发现过程只使用子图比较技术的话,得到的结果往往不令人满意。因此,迭代算法一般以基本匹配器生成的结果为基础,再进行子图匹配。ONION 算法的试验结果表明,采用这种方法得到的映射精度在56%~73%之间,映射结果的召回率为50%~90%。试验还表明,在映射发现过程中采用多种策略能提高精度。
ONION中寻找的映射是原子概念之间的等价关系,属于本体间的简单映射。
5)Wang Peng和Xu Baowen的方法。 Wang Peng和Xu Baowen等人也探讨了建立本体映射规则的方法[36] 。该方法借助各种本体概念相似度的度量[37] ,寻找异构本体概念间的关系。该方法认为概念间的语义关系可以通过概念名、概念属性和概念在本体中的上下文得到。
这种方法认为不同本体间概念的相似度包括三个部分:① 概念的同义词集相似度。同义词集是语义相同或相近词的分组[38] 。基于同名或同义词集的概念在多数情况下具有相同或是相近的含义,因此,这里将概念的名称作为相似度首要考虑的要素。② 概念特征上的相似度。概念的特征包含概念的属性、概念附带的关系以及属性和关系取值的限制,是从概念的内部组成上比较它们之间的相似度。③ 概念上下文上的相似度。以上的两种相似度都是基于概念自身的,上下文的相似度是由当前概念的语义邻居结构的相似度决定的。以下定义概念的语义邻居概念集。
定义5.6 概念Co 的语义邻居概念集N(Co ,r)={Ci |∀i,d(Co ,Ci )≤r}。式中,d表示概念间的距离,其数值为联系两概念的最短的关系数目。这里的关系包含直接继承关系。d≤r表明与当前的概念在语义距离上小于某一定常数。
在以上分析的基础上,给出了本体间概念相似度的计算公式:
S (Cp ,Cq )=Ww × Sw (Cp ,Cq )+Wu × Su (Cp ,Cq )+Wn × Sn (Cp ,Cq )
式中,Ww 、Wu 和Wn 是权重;Sw 、Su 和Sn 分别代表概念名称、特征以及上下文三方面的相似性度量。计算采用Tverski A定义的非对称的相似度度量[39] :
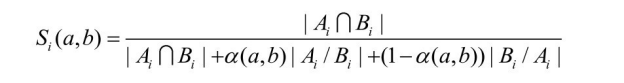
式中,a、b是待度量概念元素;Ai 和Bi ,i∈{w,u,n}分别对应概念的同义词集、特征集或语义邻居集;| |表示取集合的势;![]() 表示两集合的并集;/表示两集合的差集;α(a,b)由a、b所在类结构层次决定.
表示两集合的并集;/表示两集合的差集;α(a,b)由a、b所在类结构层次决定.

式中,depth()是当前概念在层次结构中的深度,定义为从当前概念到顶层概念的最短路径长度。
该方法利用概念间的相似度辅助本体映射的生成。
① 如果两个概念有相同名称、相同特征和相同上下文,则它们必然是相同的,即
Sw (a,b)=Su (a,b)= Sn (a,b)=1
事实上,①中的条件过于苛刻,两概念满足三种相似度都为1的情况极少。通常,如果两概念在三种相似度或总相似度中具有较高的值,它们相同的可能就很大。
② 更值得关注的结论是,在同一本体中,父概念与子概念的相似度通常小于子概念与父概念的相似度[38] ,该结论可推广到不同本体中概念间存在父子关联的判别中。
根据上面的相似度量方法和分析,该方法得到生成概念上的等价关系和上/下义关系两种映射。生成规则如下。
定义5.7 如果不同本体中两概念的互相相似度都大于定常数,那么这两概念是等价的,表示为![]() (Oa :Ci ,Ob :Cj ))。
(Oa :Ci ,Ob :Cj ))。
式中,AddBridge表示添加一个映射的操作,BCequal表示两个概念等价。
定义5.8 如果在不同本体中,某一概念Ci 对于另一概念C j 的相似度大于某一常数,同时该相似度比C j 对于Ci 的相似度大于定常数,那么将由这两概念构成上/下义关系,表示为:∀Oa :Ci ,Ob :Cj ,S(Oa :Ci ,Ob :Cj )≥β and S(Oa :Ci ,Ob :C j ) S(Ob :C j ,Oa :Ci )≥γ⇒AddBridge(isa(Oa :Ci ,Ob :C j ))。
式中,isa表示两概念具有上义和下义关系。
从上面的论述可以看出,这种方法从多个角度综合考虑概念的映射,并能抽取简单概念之间的等价和继承关系,但这些映射仍然属于简单映射。
6)S-Match。 S-Match 是一个本体匹配系统,能发现异构本体间的映射[40] 。它输入两个本体的图结构,返回图节点之间的语义关系;其中可能的语义关系有等价(=)、泛化(![]() )、特化(
)、特化(![]() )、不匹配(⊥)和相交(
)、不匹配(⊥)和相交(![]() )。
)。
S-Match 基于本体抽象层的概念继承结构树,不考虑本体中的实例。S-Match 的核心是计算异构本体间的语义关系。输入的本体树结构以标准的 XML 格式编码,这种编码能以手工编辑的文件格式调入,或者能通过相应的转换器产生。该方法首先以一种自顶向下的方式计算树中的每个标签的含义,这需要提供必要的先验词汇和领域知识,在目前的版本中,S-Match 利用 WordNet。执行结果的输出是一个被丰富的树。然后,用户协调两本体的匹配过程,这种方法使用三个外部库。第一个库是包含弱语义的元素匹配器,它们执行字符串操作(如前缀、编辑距离和数据类型等),并猜测编码相似的词之间的语义关系。目前的 S-Match 包含13个弱语义的元素层次匹配器,分成三类:①基于字符串的匹配器,它利用字符串比较技术产生语义关系;②基于含义的匹配器,它利用WordNet的继承结构特点产生语义关系;③基于注释的匹配器,它利用注释在WordNet中的含义产生语义关系。第二个库由强语义的元素层次匹配器组成,当前使用的是 WordNet。第三个库是由结构层次的强语义匹配器组成的。
输入给定的两个带标签的本体树T1 和T2 ,S-Match算法分为4步:
步骤1:对所有在T1 和T2 中的标签,计算标签的含义。
其中的思想是将自然语言表示的节点标签转换为一种内部的形式化形式,以此为基础计算每个标签的含义。其中的预处理包括:分词,即标签被解析为词,如 Wine and Cheese⇔ <Wine, and, Cheese>;词形分析,即将词的形态转换为基本形式,如Images⇔Image;建立原子概念,即利用 WordNet 提取前面分词后节点的含义;建立复杂概念,根据介词和连词,由原子概念构成复杂概念。
步骤2:对所有T1 和T2 中的节点,计算节点上概念的含义。
扩展节点标签的含义,通过捕获树结构中的知识,定义节点中概念的上下文。
步骤3:对所有T1 和T2 中的标签对,计算标签间的关系。
利用先验知识,如词汇、领域知识,借助元素层次语义匹配器建立概念间的关系。
步骤4:对所有T1 和T2 中的节点对,计算节点上的概念间的关系。
将概念间的匹配问题转换为验证问题,并利用第3步计算得到的关系作为公理,通过推理获得概念间的关系。
与一些基于术语和结构的本体映射系统比较,S-Match 在查准率和查全率方面都比较好,但是试验发现该方法的执行时间要长于其他方法。
7)Cupid。 Cupid 系统实现了一个通用的模式匹配算法[41] ,它综合使用了语言和结构的匹配技术,并在预定义词典的帮助下,计算相似度获得映射结果。该方法输入图格式的模式,图节点表示模式中的元素。与其他的混合方法比较[42] ,Cupid得到更好的映射结果。
发现模式匹配的算法包含三个阶段。①语言匹配,计算模式元素的语言相似度,基于词法正规化、分类、字符串比较技术和查词典等方法;②结构匹配,计算结构相似度,度量元素出现的上下文;结构匹配算法的主要思想是利用一些启发式规则,例如两个非叶节点相似,如果它们在术语上相似,并且以两元素为根的子树相似;③映射生成,计算带权重相似度和生成最后的映射,这些映射的权重相似度应该高于预先设定的阈值。
Cupid 针对数据库模式(通常作为一种简单的本体),它只支持模式间元素的简单映射,但给出的方法也适用于处理本体映射。
8)其他方法。 Chimaera 是一个合并和测试大本体的环境[43] 。寻找本体映射是进行合并操作的一个主要任务。Chimaera将匹配的术语对作为候选的合并对象,术语对匹配考虑术语名、术语定义、可能的缩写与展开形式以及后缀等因素。Chimaera能识别术语间是否包含或不相关等简单的映射关系。
BUSTER 是德国不来梅大学开发的改善信息检索的语义转换中间件[44] ,是为了方便获取异构和分布信息源中的数据。BUSTER通过解决结构、语法和语义上的异构来完成异构信息源的集成。它认为不同系统的用户如果在一些基本词汇上达成一致,便能确保不同源本体间的信息查询相互兼容。因此,BUSTER建立局部本体和基本词汇集之间的映射,通过这种映射来达到异构信息源查询。
COMA 是一个模式匹配系统[45] ,它是一种综合的通用匹配器。COMA 提供一个可扩展的匹配算法库、一个合并匹配结果的框架,以及一个评估不同匹配器的有效性平台。它的匹配库是可扩展的,目前该系统包含6个单独的匹配器、5个混合匹配器和1个面向重用的匹配器,它们大多数的实现基于字符串技术。面向重用的匹配器则力图重用其他匹配器得到的结果来得到更好的映射。模式被编码为有向无环图。COMA 支持在匹配过程中与用户进行交互,提高匹配结果的准确率。
ASCO 原型依靠识别不同本体间相关元素对的算法[46] 来发现映射,这些元素对可以是概念对,也可以是关系对。ASCO 使用本体中包含的可用信息来处理映射,这些信息包括标识、标签、概念和标签的注释、关系和它的定义域和值域,概念和关系的结构,以及本体的实例和公理。该方法的匹配过程分为几个阶段:语言阶段应用语言处理技术和字符串比较度量元素间关系,并利用词汇数据库来计算概念或关系间的相似度;结构阶段利用概念和关系的结构计算概念或关系间的相似度。
(3)基于术语和结构的本体映射总结。 尽管基于术语和结构的本体映射探索不少,但是总的来说取得的映射结果都不够让人满意,大多数的工作只能发现简单概念间的等价和包含映射,以及原子关系之间的等价。这一类方法大部分基于一些直观的思想,缺乏理论的依据和支持,因此适用范围窄,取得的映射结果质量低。
2.基于实例的本体映射
基于实例的本体映射发现方法通过比较概念的外延,即本体的实例,发现异构本体之间的语义关联。
(1)技术综述。 基于实例的本体映射技术可分为两种情况:本体概念间存在共享实例和概念之间没有共享实例。
① 共享实例的方法。 当来自不同本体的两概念A和B有共享实例时,寻找它们之间关系最简单的方法是测试实例集合的交。当两概念等价时,显然有 A![]() B=A=B。然而,当两概念相似,即它们存在部分共享实例时,直接求交集的方法不合适,为此采用如下定义的对称差分来比较两概念。
B=A=B。然而,当两概念相似,即它们存在部分共享实例时,直接求交集的方法不合适,为此采用如下定义的对称差分来比较两概念。
定义5.9 对称差分表示两集合的相似度,如果x和y是两个概念对应的实例集合,则它们的对称差分相似度为![]()
可见,对称差分值越大,概念间的差异越大。此外,还可以根据实例集合的概率解释来计算相似度,在随后的方法中将详细介绍。
② 无共享实例的方法。 当两概念没有共享实例时,基于共享实例的方法无能为力。事实上,很多异构本体间都不存在共享实例,除非特意人工构建共享实例集合。在这种情况下,可以根据连接聚合等数据分析方法获得实例集之间的关系。常用的连接聚合度量包括单连接、全连接、平均连接和Haussdorf距离。其中,Haussdorf距离度量两个集合之间的最大距离。而Valtchev P提出的匹配相似度则通过建立实体间的对应关系来进一步计算集合之间的相似度[47] 。
基于实例的映射发现方法很多采用机器学习技术来发现异构本体间映射。通过训练,有监督的学习方法可以让算法了解什么样的映射是好的(正向结果),什么样的映射不正确(负向结果)。训练完成后,训练结果用于发现异构本体间的映射。大量的本体实例包含了实例间具有的关系以及实例属于哪个概念等信息,学习算法利用这些信息能学习概念之间或关系之间的语义关系。常用的机器学习算法包括形式化概念分析[48] 、贝叶斯学习[49] 和神经网络[50] 等。
(2)方法和工具
1)GLUE。 GLUE 是著名的本体映射生成系统之一,它应用机器学习技术,用半自动的方法发现异构本体间的映射[51,8,52] 。GLUE 是对半自动模式发现系统 LSD 的一个改进[53] 。GLUE 认为概念分类是本体中最重要的部分,它着重寻找分类本体概念之间的1∶1映射。该方法还能扩充为发现关系之间的映射以及处理更复杂的映射形式(如1∶n 或n∶1)[54] 。
① GLUE的思想。 GLUE的目的是根据分类本体寻找本体间1∶1的映射。其中的主要思想包括:(a)相似度定义。GLUE 有自己特有的相似度定义,它基于概念的联合概率分布,利用概率分布度量并判断概念之间的相似度。GLUE定义了4种概念的联合概率分布。(b)计算相似度。由于本体之间的实例是独立的,为了计算本体 O1 中概念 A 和本体O2 中概念 B 之间的相似度,GLUE 采用了机器学习技术。它利用 A 的实例训练一个匹配器,然后用该匹配器去判断B的实例。(c)多策略学习。使用机器学习技术存在的一个问题是:一个特定的学习算法通常只适合解决一类特定问题。然而,本体中的信息类型多种多样,单个学习器无法有效利用各种类型的信息。为此,GLUE 采用多策略学习技术,即利用多个学习器进行学习,并通过一个元学习器综合各学习器的结果。(d)利用领域约束。GLUE 利用领域约束条件和通用启发式规则来提高映射结果的精度。一个领域约束的例子是“如果概念 X 匹配 Professor 以及概念 Y 是 X 的祖先,那么 Y 不可能匹配概念Assistant-Professor”;一个启发式规则如“两个概念的邻居都是匹配的,那么这两个概念很可能也匹配”。(e)处理复杂映射。为了能发现本体间的复杂映射,如1∶n 类型的概念映射,GLUE被扩展为CGLUE系统,以寻找复杂的映射。
以下给出GLUE方法的详细介绍。
② 相似度度量。 很多本体相似度定义过于依赖概念本身和它的语法表示,与这些方法不同,GLUE 定义了更精确的相似度表示。GLUE 将概念视为实例的集合,并认为该实例集合是无限大的全体实例集中的一个子集。在此基础上,GLUE 定义不同概念间的联合概率分布。概念 A 和 B 之间的联合概率分布包括4种:P(A,B)、P(![]() ,B)、P(A,
,B)、P(A,![]() )和P(
)和P(![]() )。以 P(A,
)。以 P(A,![]() )为例,它表示从全体实例集中随机选择一个实例,该实例属于 A 但不属于B的概率,概率的值为属于A但不属于B的实例占全体实例集的比例。
)为例,它表示从全体实例集中随机选择一个实例,该实例属于 A 但不属于B的概率,概率的值为属于A但不属于B的实例占全体实例集的比例。
GLUE 的相似度度量正是基于这4种概念的联合分布,它给出了两个相似度度量函数。第一个相似度度量函数是基于Jaccard系数[55] :
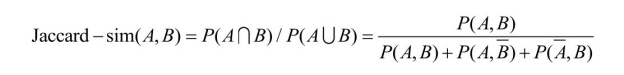
当 A 与 B不相关时,该相似度取得最小值0;当A和 B 是等价概念时,该相似度取得最大值1。
另一个相似度度量函数为“最特化双亲”,它定义为
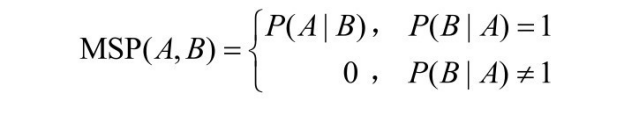
其中,概率 P(A|B)和 P(B|A)能用4种联合概率来表示。这个定义表明,如果 B 包含A,则 B 越特化,P(A|B)越大,那样 MSP(A,B)的值越大。这符合这样的直觉:A 最特化的双亲是包含 A 的最小集;或者说在 A 的所有父概念中,它与直接父概念的相似度最大。类似于“最特化双亲”,还可以定义“最泛化孩子”的相似度度量。
③ GLUE 体系结构。 GLUE 主要由三个模块组成:分布估计、相似度估计和放松标记,如图5-8所示。
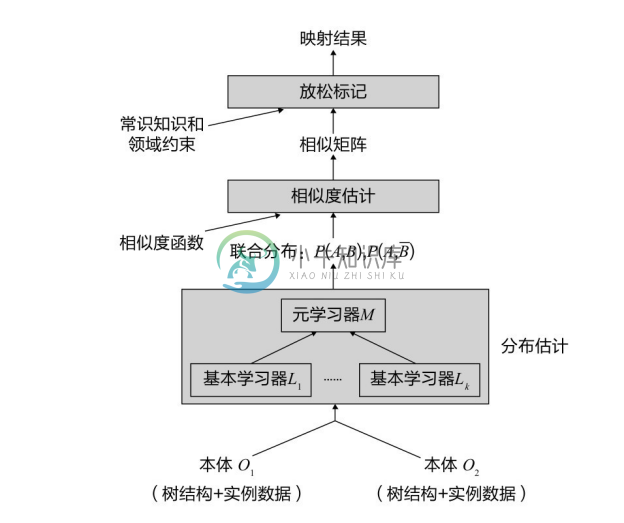
图5-8 GLUE体系结构
分布估计输入两个分类本体O1 和O2 以及它们的实例。然后利用机器学习技术计算每对概念的联合概率分布。由于联合概率分布包含4种,这样一共需要计算4|O1 ||O2 |个概率,其中|Oi |是本体Oi 中概念的数目。分布评估使用一组基本学习器和一个元学习器。
相似度估计利用输入的联合概率分布,并借助相似度函数,计算概念对之间的相似度,输出两个分类本体之间的概念相似度矩阵。
放松标记模块利用相似度矩阵以及领域特定的约束和启发式知识,寻找满足领域约束和常识知识的映射,输出最终的映射结果。
④ 分布估计。 考虑计算P(A,B)的值,其中A∈O1 且B∈O2 ,这个联合概率分布是同时属于 A 和 B 的实例数与全体实例总数的比值。通常这个比值是无法计算的,因为不可能知道全体实例。因此,必须基于现有的数据来估计 P(A, B),即利用两个本体的输入实例。注意,两个本体的实例可以重叠,但没有必要必须那样。
Ui 表示本体 Oi 的实例集合,它是全体实例中的本体 Oi 对应部分的抽样。N(Ui )是 Ui 中实例的数目,![]() 是同时属于 A 和 B 的实例数目。这样,P(A, B)能用如下的公式来估计:
是同时属于 A 和 B 的实例数目。这样,P(A, B)能用如下的公式来估计:
![]()
这样将 P(A,B)的计算转化为计算![]() 和
和![]() 。例如,为了计算
。例如,为了计算![]() 的数值,需要知道U2 中的每个实例s是否同时属于A和B;由于B是O2 的概念,属于B的那部分实例是很容易得到的,因为这已在本体中明确说明;而 A 并不在本体 O2 中,因此只需要判断O2 中的实例s是否属于A。为了达到这个目的,GLUE使用了机器学习方法。特别地,将 O1 的实例集合 U1 划分为属于 A 的实例集和不属于 A 的实例集。然后,将这两个集合作为正例和反例,分别训练关于 A 的实例分类器。最后,使用该分类器预测 O2 中的实例 s 是否属于 A。通常,分类器返回的结果并非是明确的“是”或“否”,而是一个[0,1]之间的置信度值。这个值反映了分类的不确定性。这里规定置信度大于0.5就表示“是”。常用的分类学习器很多,GLUE使用的分类学习器将在随后部分介绍。
的数值,需要知道U2 中的每个实例s是否同时属于A和B;由于B是O2 的概念,属于B的那部分实例是很容易得到的,因为这已在本体中明确说明;而 A 并不在本体 O2 中,因此只需要判断O2 中的实例s是否属于A。为了达到这个目的,GLUE使用了机器学习方法。特别地,将 O1 的实例集合 U1 划分为属于 A 的实例集和不属于 A 的实例集。然后,将这两个集合作为正例和反例,分别训练关于 A 的实例分类器。最后,使用该分类器预测 O2 中的实例 s 是否属于 A。通常,分类器返回的结果并非是明确的“是”或“否”,而是一个[0,1]之间的置信度值。这个值反映了分类的不确定性。这里规定置信度大于0.5就表示“是”。常用的分类学习器很多,GLUE使用的分类学习器将在随后部分介绍。
基于上述思想,通过学习的方法得到 ![]() 和
和 ![]() 等参数,就能估计A和B的联合概率分布。具体的过程如图5-9所示。
等参数,就能估计A和B的联合概率分布。具体的过程如图5-9所示。
●划分本体O1 的实例集合U1 为![]() 和
和![]() ,分别表示属于A和不属于A的实例集合,如图5-9(a)和图5-9(b)所示。
,分别表示属于A和不属于A的实例集合,如图5-9(a)和图5-9(b)所示。
●使用![]() 和
和![]() 作为正例和反例分别训练学习器L,如图5-9(c)。
作为正例和反例分别训练学习器L,如图5-9(c)。
●划分本体 O2 的实例集合 U2 为![]() 和
和 ![]() ,分别表示属于 B 和不属于 B 的实例集合,如图5-9(d)和图5-9(e)所示。
,分别表示属于 B 和不属于 B 的实例集合,如图5-9(d)和图5-9(e)所示。
●对![]() 中的每个实例使用学习器 L 进行分类。将
中的每个实例使用学习器 L 进行分类。将 ![]() 划分为两个集合
划分为两个集合![]() 和
和![]() 。相似地,对
。相似地,对![]() 应用学习器 L,得到两个集合
应用学习器 L,得到两个集合![]() 和
和![]() ,如图5-9(f)所示。
,如图5-9(f)所示。
●重复(a)~(d),得到集合![]() 和
和 ![]() 。
。
●使用公式计算P(A,B)。类似地,可以计算出其他3种联合概率分布。
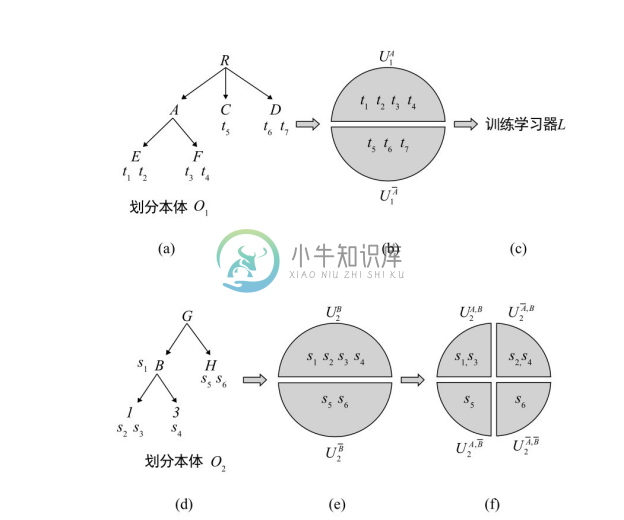
图5-9 估计概念A和B的概率分布
⑤ 多策略学习。 训练实例分类器的过程可根据不同类型的信息,如可以利用词语出现的频率、实例名和实例属性的赋值格式等。基本的分类学习器有很多,但不同学习器通常只适合针对特定信息类型进行分类,分类的效果不一定让人满意。为了在学习过程中充分考虑信息类型,提高分类的精度,GLUE 采用多策略的学习方法。在分布估计阶段,系统会训练多个基本学习器 L1 ,…,Lk 。每种学习器利用来自实例数据中某种类型的信息进行分类学习训练。训练完成后,当使用这些基本学习器进行实例分类时,借助一个元学习器合并各个学习器的预测结果。与采用单个学习器的方法相比,多策略的学习方法能得到较高的分类准确率,并可以得到较好的联合分布近似值。
目前实现的 GLUE 系统中有2个基本分类学习器:内容学习器和名字学习器。此外,还有1个元学习器将基本学习器的结果进行线性合并。内容学习器和名字学习器的细节如下:
(a)内容学习器。利用实例文本内容中的词频来进行分类预测。一个实例通常由名字、属性集合以及属性值组成。GLUE 将这些信息都作为实例的文本内容。例如,实例“Professor Cook”的文本内容是“R.Cook, Ph.D., University of Sydney, Australia”。
内容学习器采用贝叶斯学习技术[56] ,这是最流行和有效的分类法之一。它采用分词和抽取词干技术将每个输入实例的文本内容表示为一组标记,即输入实例的内容表示为d={w1 ,…,wk },其中的wj 是标记。
内容学习器的目的是计算输入的一个实例(用它的内容d表示)属于概念A的概率,即P(A|d)。根据贝叶斯原理,P(A|d)可被重写为P(d|A)P(A)/P(d)。其中,P(d)是一个常量,而P(d|A)和P(A)能通过训练实例来估计。特别地,P(A)被估计为属于A的实例占全部训练实例的比例。因此,只需要计算P(d|A)就可以得到P(A|d)。
为计算P(d|A),假设实例的内容d中的标记wj 是独立的,这样便有:
P(d|A)=P(w1 |A)P(w2 |A)··· P(wk |A)
式中,P(wj |A)可用 n(wj , A)/n(A)来估计,n(A)表示在属于 A 的训练实例中,所有标记出现的总次数,n(wj ,A)则表示标记 wj 出现在属于 A 的训练实例中的次数。注意,尽管标记独立假设在很多时候并不成立,但贝叶斯学习技术往往在很多领域都取得了不错的效果,这种现象的相关解释见文献[60]。P(![]() |d)可通过相似的方法来计算。
|d)可通过相似的方法来计算。
(b)名字学习器。相似于内容学习器,但名字学习器利用实例的全名而不是实例的内容来进行分类预测。这里的实例全名是指从根节点直到实例所在位置的路径上所有概念名的连接。例如,图5-9(d)中s4 的全名为“GBJs4”。
(c)元学习器。基本学习器的预测结果通过元学习器来合并。元学习器分配给每个基本学习器一个权重,表示基本学习器的重要程度,然后合并全部基本学习器的预测值。例如,假设内容学习器和名字学习器的权重分别是0.6和0.4;对于本体O2 中的实例s4 ,如果内容学习器预测它属于A的概率为0.8,属于![]() 的概率为0.2,名字学习器预测它属于A的概率为0.3,属于
的概率为0.2,名字学习器预测它属于A的概率为0.3,属于![]() 的概率为0.7,则元学习器预测 s4 属于 A 的概率为0.8×0.6+0.3×0.4=0.6,属于
的概率为0.7,则元学习器预测 s4 属于 A 的概率为0.8×0.6+0.3×0.4=0.6,属于![]() 的概率为0.4。
的概率为0.4。
这种基本学习器的权重往往由人工给定,但也可以使用机器学习的方法自动设置[57] 。
⑥ 利用领域约束和启发式知识。 经过相似估计,得到了概念之间的相似度矩阵,进一步利用给定的领域约束和启发式知识,能获得最佳的正确映射。
放松标记是一种解决图中节点的标签分配问题的有效技术。该方法的思想是节点的标签通常受其邻居的特征影响。基于这种观察,放松标记技术将节点邻居对其标签的影响用公式量化。放松标记技术已成功用于计算机视觉和自然语言处理等领域中的相似匹配。GLUE 将放松标记技术用于解决本体映射问题,它根据两本体的特征和领域知识寻找本体节点间的对应关系。
考虑约束能提高映射的精度。约束又可分为领域独立约束和领域依赖约束两种。领域独立约束表示相关节点间交互的通用知识,其中最常用的两种约束是邻居约束和并集约束。邻居约束是指“两节点的邻居匹配,则两节点也匹配”;并集约束指“如果节点 X 的全部孩子匹配 Y,那么节点 X 也匹配 Y”;该约束适用于分类本体,它基于这样的事实,即 X 是它的所有孩子的并集。领域依赖约束表示特定节点间交互的用户知识,在 GLUE系统中,它可分为包含、频率和邻近三种。以一个大学组织结构的本体为例,包含约束如“如果节点 Y 不是节点 X 的后继,并且 Y 匹配 PROFESSOR,则 X 不可能匹配FACULTY”;频率约束如“至多只有一个节点和 DEPARTMENT-CHAIR 匹配”;邻近约束如“如果X邻居中的节点匹配ASSOCIATE-PROFESSOR,则X匹配PROFESSOR的机会增加”。GLUE利用这些限制进一步寻找正确的映射或去除不太可能的映射。
⑦ 实验评估。 GLUE 系统的实验结果表明,对于1∶1的映射,正确率为66%~97%。在基本学习器中,内容学习器的正确率为52%~83%,而名字学习器的正确率很低,只有12%~15%。在半数的实验中,元学习器只少量提高正确率,在另一半的实验中,正确率提高了6%~15%。放松标记能进一步提高3%~18%的正确率,只有一个实验例外。由实验可见,对于适量的数据,GLUE能取得较好的概念间1∶1形式的映射结果。
尽管 GLUE 取得了不错的映射结果,但几个因素阻碍它取得更高的映射正确率。首先,一些概念不能被匹配是因为缺少足够的训练数据。其次,利用放松标签进行优化的时候可能没有考虑全局的知识,因此优化的映射结果对整个本体来说并不是最佳的。第三,在实现中使用的两个基本学习器是通用的文本分类器,使用适合待映射本体的特定学习器可以得到更好的正确率。最后,有些节点的描述过于含糊,机器很难判断与之相关的映射。
⑧ 扩充 GLUE 发现复杂映射。 GLUE 寻找给定分类本体概念之间1∶1的简单映射,但是实际应用中的复杂映射很普遍。为此,GLUE 被扩充为 CGLUE,用于发现异构本体间的复杂映射。目前的 CGLUE 系统主要针对概念间的复杂映射,如 O1 中的概念“Course”等价于O2 中的“Undergrad-Courses”![]() “Grad-Course”。
“Grad-Course”。
CGLUE中的复杂映射形式如A=X1 op1 X2 op2 … opn-1 Xn ,其中A是O 1 中的概念,Xi 是O2 中的概念,opi 是算子。这种1∶n的映射可扩展为m∶n的形式,如A1 op1 A2 =X1 op1 X2 op2 X3 。由于将概念看作实例的集合,因此 opi 可以是并、差和补等集合运算符。CGLUE将形如X1 op1 X2 op2 · · · opn-1 Xn 的复合概念称作映射对象。
CGLUE 还进一步假设概念 D 的孩子 C1 , C 2 , …, Ck 要满足条件![]() , 1≤i,j≤k,i≠ j,且
, 1≤i,j≤k,i≠ j,且![]() 。这样的假设对实际本体的质量提出了很高的要求。CGLUE将复合概念都可以重写为概念并的形式,便于统一处理。
。这样的假设对实际本体的质量提出了很高的要求。CGLUE将复合概念都可以重写为概念并的形式,便于统一处理。
对于O1 中的概念 A,CGLUE 枚举 O2 中的所有概念并的组合,并比较它与A的相似度。比较的方法与 GLUE 中的相似。最后返回相似度最高的映射结果。由于概念并组合的数目是指数级的,上面的“暴力”方法是不实用的。因此需要考虑从巨量的候选复合概念中搜索 A 的近似。为提高搜索的效率,CGLUE 采用人工智能中的定向搜索技术,其基本思想是在搜索过程中的每一阶段,只集中关注最可能的k个候选对象。
定向搜索算法寻找概念A的最佳映射的步骤如下:
步骤1 。令初始候选集合S为O2 的全部原子概念集合。设highest_sim=0。
步骤2 。循环:
(a)计算A和S中每个候选对象的相似度分数。
(b)令new_highest_sim为S中对象的最高相似度分数。
(c)如果|new_highest_sim - highest_sim|≤ε,则停止,返回S中拥有最高相似度分数的候选对象;其中ε是预定的。
(d)否则,选择C中有最高分的k个候选对象。扩展这些候选创建新的候选对象。添加新候选对象到S。设置highest_sim=new_highest_sim。
算法的步骤2(a)采用 GLUE 中的学习方法计算概念 A 和候选概念间的相似度分数。在步骤2(c)中,ε最初设置为0。在步骤2(d)中,对于选择的k个候选对象,算法将它们与 O2 中的节点分别进行并操作,这样一共产生 k|O2 |个新候的选对象;接着,去除前面使用的候选对象。因为每个候选对象只是O2 概念的并,去除过程很快。
CGLUE 的实验结果表明,该算法发现了 GLUE 不能发现的1∶n 类型的概念映射。试验还表明,对于一部分实验,CGLUE取得50%~57%的正确率,对另外一部分实验只获得16%~27%的正确率。实验还表明,CGLUE 能帮助用户确定52%~84%的正确1∶1映射。CGLUE的开发者认为,如果进一步利用领域约束等知识,能取得更好的映射结果。
⑨ GLUE 的总结。 GLUE 是早期经典的本体映射工作之一,该方法取得的结果较早期大多的映射发现技术更好。GLUE 的语义相似基础建立在概念的联合概率分布上,它利用机器学习的方法,特别是采用了多策略的学习来计算概念相似度;GLUE 利用放松标记技术,利用启发式知识和特定领域约束来进一步提高匹配的正确率。试验表明,对于概念之间1∶1的简单映射,GLUE 能得到很不错的结果。扩展后的 CGLUE 系统还能进一步发现概念间1∶n类型的映射。
尽管GLUE取得了很多不错的映射结果,但该方法还存在一些不足。首先,GLUE和CGLUE 的映射正确率并不是很高,即使应用相关的领域约束,对各种情况的映射仍然难以得到高精度的映射结果;这主要是由于 GLUE 建立在机器学习技术上,机器学习技术的特性决定了很难取得接近100%的正确率;对不同本体之间的映射,都需要进行学习训练,使用起来很麻烦;学习器的类型有限,难以处理本体中各种类型的信息。其次,对于复杂概念间的映射,CGLUE 提出的算法并不能让人满意,这种算法寻找到的复杂概念映射不是完备的,很多正确的映射可能会被漏掉。最后,GLUE 无法处理关于异构本体的关系之间的映射。
2)概念近似的方法。 在基于异构本体的信息检索中,为了得到正确和完备的查询结果,往往需要将原查询重写为近似的查询。本体间概念的近似技术是近似查询研究的重点,它不仅用于解决异构本体的近似查询,而且还提供了一类表示和发现概念间映射的方法。
① 方法的思想。 在本体查询系统中,信息源和查询都是针对特定本体的。不同的信息系统可能使用不同的本体,一个查询用某个本体中的词汇表达,但系统可能使用另一个本体,因而无法回答这个查询。一般地,如果 S 是基于本体 O 的信息源,则 S 只能回答关于 O 的查询。因此,如果用户(查询提出者)和系统(查询回答者)使用不同的本体,便带来了查询异构问题。当不存在一个全局本体时,异构查询问题通常需要在这两个本体之间解决。令用户本体为O1 ,系统本体为O2 ,则必须把用户提出的关于O1 的查询重写为关于O2 的查询,系统才能够回答。查询重写的理想目标是把关于O1 的查询重写为关于 O2 的解释相同的查询,这样系统才能准确地给出查询结果。但是对于 O1 中的很多查询,可能不存在关于 O2 的解释相同的查询,或者找到这样的查询所需的时间是不可接受的,因此常常需要重写为解释近似于原查询的查询。
令Q为关于O1 的查询,R是重写Q得到的关于O2 的近似查询,称R是Q在O2 中的近似;令O2 中全部概念的集合为T,则也称R是Q在T中的近似。R作为Q在T中的近似,它在信息源S中的查全率和查准率可定义为:
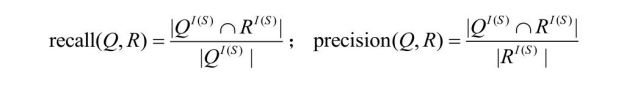
查全率和查准率决定了近似的质量,较好的近似有较高的查全率和查准率。如果在所有S中都有recall(Q,R)= 1,则近似查询结果包括了所有原查询的结果,称R是完备的;如果在所有S中都有precision(Q,R)= 1,则所有近似查询结果都是原查询的结果,称R是正确的。查询间的蕴涵关系可用来寻找完备或正确的近似,如果Q![]() R,那么R一定是完备的,称R是Q在T中的一个上近似;反之,如果R
R,那么R一定是完备的,称R是Q在T中的一个上近似;反之,如果R![]() Q,那么R一定是正确的,称R是Q在T中的一个下近似。
Q,那么R一定是正确的,称R是Q在T中的一个下近似。
本体间的概念近似技术正是基于上述思想,研究如何通过概念近似来重写查询表达式中的概念,以获得较高查全率和查准率的结果。这种方法虽然最终是为了处理查询,但它的核心过程是表示和寻找异构本体概念间的近似;寻找概念近似的过程通常是基于实例进行的,因此是一种重要的本体映射发现方法。
② Stuckenschmidt H的概念近似。 寻找O1 中概念C在O2 中的近似是近似查询中的关键问题,其质量决定了近似查询的质量。Stuckenschmidt H 提出了利用概念的最小上界和最大下界计算概念近似的方法[57] 。
该方法首先定义了概念的最小上界和最大下界,并以此作为概念的上近似和下近似。从概念的蕴涵关系层次上看,概念的最小上界包括了概念在另一本体中所有的直接父类,概念的最大下界包括了概念在另一本体中所有的直接子类,如图5-10所示。C为O1 中概念,概念C的最小上界 lub(C, T)包含 A 1 , A 2 ,…,Am ,是 C 在 O 2 中的直接父类;概念C的最大下界glb(C,T)包含B 1 ,B 2 ,…,Bn ,是C在O2 中的直接父类。
图5-10 最小上界和最大下界
定义5.10 令C为O1 中概念,T为O2 中全部概念的集合。定义C在T中的最小上界lub(C, T)是T中概念的集合,满足:
1.对于任何D∈lub(C, T),有C![]() D;
D;
2.对于任何A∈T且C![]() A,存在B∈lub(C, T)满足B
A,存在B∈lub(C, T)满足B![]() A。
A。
找到C在T中的最小上界后,定义其中元素的合取为C在T中的一个上近似,记为下式:

由于C被最小上界中的概念蕴涵,可知C![]() ua(C, T),所以ua(C, T)确实是C在T中的上近似。
ua(C, T),所以ua(C, T)确实是C在T中的上近似。
定义5.11 令C为O1 中概念,T为O2 中全部概念的集合。定义C在T中的最大下界glb(C,T)是T的一个子集,满足:
1.对于任何D∈glb(C,T),有D![]() C;
C;
2.对于任何A∈T且A![]() C,存在B∈glb(C,T)满足A
C,存在B∈glb(C,T)满足A![]() B。
B。
找到C在T中的最大下界后,定义其中元素的析取为C在T中的一个下近似,记为下式:

由于 C 蕴涵最大下界中的概念,可知 la(C,T)![]() C,所以 la(C,T)确实是 C 在 T 中的下近似。
C,所以 la(C,T)确实是 C 在 T 中的下近似。
显然,这样得到的上近似和下近似都不包含非算子( ![]() ),该方法只考虑不包含非算子的近似。因为非算子可以通过将查询化为否定正规形式(Negation Normal Form, NNF)消去[58] 。任何查询都可以在线性时间内通过反复应用以下公式改写为等价的NNF
),该方法只考虑不包含非算子的近似。因为非算子可以通过将查询化为否定正规形式(Negation Normal Form, NNF)消去[58] 。任何查询都可以在线性时间内通过反复应用以下公式改写为等价的NNF
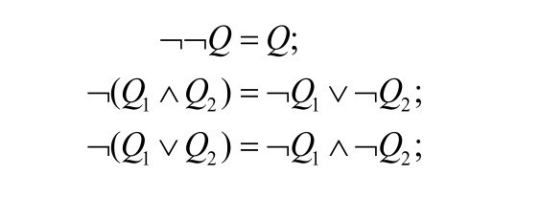
在 NNF 中,非算子只作用于单个概念,可以将其看作一个新的概念进行处理。这样概念数目最多翻倍,但所有非算子都被消去。
Akahani J等人对定义5.10和定义5.11进行了扩展[59] ,改写为T中概念D属于O1 中概念C在T中最小上界lub(C,T),当且仅当C![]() D,且不存在A∈T满足C
D,且不存在A∈T满足C![]() A
A![]() D;T中概念D属于O1 中概念C在T中最大下界glb(C,T),当且仅当D
D;T中概念D属于O1 中概念C在T中最大下界glb(C,T),当且仅当D![]() C,且不存在A∈T满足D
C,且不存在A∈T满足D![]() A
A![]() C。
C。
上述扩展定义去除了最小上界和最大下界中的大量冗余成员,提高了效率。但由于最小上界和最大下界是T的子集,本身不会很大,效果并不明显。
在生成概念的近似过程中,该方法首先找到概念在系统本体中的超类和子类,然后生成概念的最小上界和最大下界,并将上界的合取作为概念的上近似,下界的析取作为概念的下近似。但这种方法无法得到概念的最佳近似,近似的质量有时是不可接受的。
如果概念远小于它的超类,那么它的上近似可能过大;最坏情况是找不到概念的超类,那么上近似的查询结果就会返回全集。同样,如果概念远大于它的子类,那么它的下近似可能过小;最坏情况是找不到概念的子类,那么下近似的查询结果就会返回空集。异构本体常常有全异的概念集合和概念层次,因此最坏的情况也时常会出现。这种现象出现的主要原因是现有方法只注意概念的超类和子类,也就是异构本体原子概念间的蕴涵关系,因而不能得到概念的最佳近似。实际上,在复杂概念,如概念的合取和析取之间,同样也存在着蕴涵关系。如果考虑这些蕴涵关系,也许可以提高近似查询的质量。
例如,令 O1 ,O2 为本体,C 为 O1 中概念,T 是 O2 中所有概念的集合,且 T 中没有概念能蕴涵 C 或被 C 蕴涵,则现有方法对C求上近似会返回全集top,下近似返回空集bot。但如果T中有概念A, B满足A∧B![]() C
C![]() A∨B,则 A∨B 是 C 的一个上近似,A∧B 是 C 的一个下近似,它们显然比现有的近似要好。图5-11就描述了这种情况,图中阴影部分表示 C 的实例集合,斜线部分表示A 的实例集合,竖线部分表示 B 的实例集合。显然,A, B, C之间不存在任何蕴涵关系,但有A∧B
A∨B,则 A∨B 是 C 的一个上近似,A∧B 是 C 的一个下近似,它们显然比现有的近似要好。图5-11就描述了这种情况,图中阴影部分表示 C 的实例集合,斜线部分表示A 的实例集合,竖线部分表示 B 的实例集合。显然,A, B, C之间不存在任何蕴涵关系,但有A∧B![]() C
C![]() A∨B。这个例子表明在检查蕴涵关系时考虑复杂概念 A∨B(概念A和B的析取)和A∧B(概念A和B的合取)确实会得到更好的上近似和下近似。
A∨B。这个例子表明在检查蕴涵关系时考虑复杂概念 A∨B(概念A和B的析取)和A∧B(概念A和B的合取)确实会得到更好的上近似和下近似。
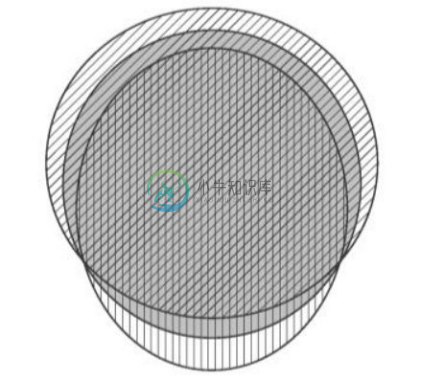
图5-11 复杂蕴涵关系示例
③ TzitzikasY 的概念近似。 为获得不同本体中概念的最佳近似,Tzitzikas Y 提出通过实例学习来进行近似查询的方法[60] 。它根据每个查询结果中的实例进行查询重写:对每一个应该是原查询结果的实例,找到能返回该实例的另一个本体中的最小查询,最后把这些最小查询组合起来得到原查询的一个近似。
该方法需要一个训练实例集合。令与 O2 中概念集合 T 相关的信息源 S 为训练集,K是S中的一个非空对象集合。在不考虑非算子的情形下,该方法定义了两个关于T的查询集合:
K+ ={Q|K⊆QI(S) };K- ={Q|QI(S) ⊆K}
式中,QI(S) 表示查询Q对应S中对象的集合;K+ 表示包含K的查询集合;K- 表示K包含的查询集合。这样,对于非空对象集合K,它的上界和下界可计算为:
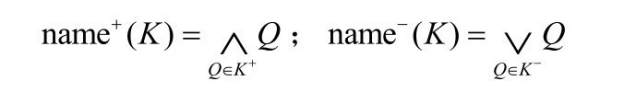
显然,由于 K+ 和 K- 中的查询表达式数目可能会很多,这样的上、下界表达式长度会很长,需要一种方法计算等价的且长度有限的查询。为此,引入一个将对象映射到概念合取的函数:![]() 。可证明利用DI (o)能得到与上界和下界等价的近似表示形式,这种表示的长度是有限的:
。可证明利用DI (o)能得到与上界和下界等价的近似表示形式,这种表示的长度是有限的:
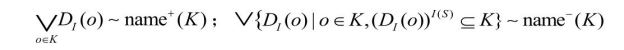
对于概念 C,如果K=CI(S) ,那么name+ (K)是 C 关于 T 的最小上近似,name- (K)是最大下近似。对于给定的查询,只需要将其中的概念按照这种近似表示就能重写概念近似查询。遗憾的是,Tzitzikas Y并没有提出有效发现这种概念近似的方法。
与Stuckenschmidt H的方法相比,这种表示不会造成映射结果的丢失,即能得到完备的概念间近似,但这种方法存在着明显的缺点。第一是查询效率问题。该方法需要遍历所有实例计算概念近似。得到的近似查询是由很多小查询构成的,比较冗长,但表达式的长度却没有算法来简化。第二,该方法完全基于从训练集合中学习概念间的包含关系,而没有考虑本体间的语义关系。最后,该方法得到的近似不能传递,即不能从![]() 和
和![]() 得到
得到![]() ,因为它们可能是根据不同的训练集得到的结果。
,因为它们可能是根据不同的训练集得到的结果。
④ 基于多元界的概念近似。 Kang Dazhou、Lu Jianjiang和Xu Baowen等人提出一套表示和发现概念近似查询的有效方法[61-63] ,该方法能有效发现异构本体间概念的近似,且这种近似是最佳的和完备的。这种方法能进一步推广到关系映射的发现。
由于其他的方法要不只考虑异构本体概念间一对一的蕴涵关系,概念的上下界中只包含独立的概念,因此无法得到概念的最佳近似;或者得到了概念间的最佳近似,但近似表示的形式冗余,且没有给出有效寻找映射的算法。基于多元界的概念近似方法的创新之处是考虑概念合取和析取之间的蕴涵关系来得到概念的最佳近似。将概念的最小上界和最大下界扩展为多元界:引入概念的析取定义概念的多元最小上界,引入概念的合取定义概念的多元最大下界。证明通过概念的多元最小上界可以得到概念的最小上近似,通过概念的多元最大下界可以得到概念的最大下近似。通常多元界中可能包含大量冗余,增加了概念近似表达的复杂度,降低了查询效率。该方法又定义了概念的最简多元最小上界和最简多元最大下界去除这些冗余,并提供两个有效的算法寻找概念的最简多元界,算法被证明是正确和完备的。
该方法首先结合查全率和查准率的评判标准和查询间蕴涵关系,给出概念最佳近似的定义,分别包括概念的最小上近似和最大下近似。引入复杂概念间的蕴涵关系,将概念析取扩充到概念的上界中,将概念合取扩充到概念的下界中。由于上下界中都含有多个概念组成的复杂概念,称新的上下界为概念的多元界。证明利用多元界可以求得概念的最佳近似,从而提高近似查询的质量。这是该方法的理论基础。
3)FCA。 Stumme G 等人提出一种自底向上的本体合并方法 FCA-Merge[48,64] ,它基于两本体和它们的实例,使用形式化概念分析技术 FCA 合并两个共享相同实例集的本体。该方法的结果是合并后的本体,但结果本体间接蕴涵着两个初始本体间的概念映射:被合并的概念可认为是等价映射,它们与对应的祖先或孩子节点之间存在包含关系的映射,与对应的兄弟概念存在着相似关系。当然,这些概念分别来自两个不同的初始本体。
① 形式化概念分析基础。 首先介绍 FCA-Merge 方法采用的理论基础,即形式概念分析,也称为概念格。形式概念分析是由 Wille R 于1982年首先提出的[65] ,它提供了一种支持数据分析的有效工具。概念格中的每个节点是一个形式概念,由两部分组成:外延,即概念对应的实例;内涵,即概念的属性,这是该概念对应实例的共同特征。另外,概念格通过 Hasse 图生动和简洁地体现了这些概念之间的泛化和特化关系。因此,概念格被认为是进行数据分析的有力工具。从数据集(概念格中称为形式背景)中生成概念格的过程实质上是一种概念聚类过程;然而,概念格可以用于许多机器学习的任务。形式背景可表示为三元组形式T=(S, D, R), 其中S是实例集合,D是属性集合,R是S和D之间的一个二元关系,即R∈S× D。(s, d)∈R表示实例s有属性d。一个形式背景存在唯一的一个偏序集合与之对应,并且这个偏序集合产生一种格结构。这种由背景(S, D, R)导出的格L就称为一个概念格。格 L 中的每个节点是一个序偶(称为概念),记为(X, Y),其中 X∈P(S),这里P(S)是S的幂集,称为概念的外延;Y∈P(D),这里P(D)是D的幂集,称为概念的内涵。每一个序偶关于关系R是完备的,即有性质:
1)X ={x∈S|∀y∈Y,xRy}
2)Y={y∈D|∀x∈X,xRy}
在概念格节点间能够建立起一种偏序关系。给定 H1 =(X1 ,Y1 )和 H2 =(X2 ,Y2 ),则H2 <H1 ⇔Y1 <Y2 ,领先次序意味着 H2 是 H1 的父节点或称直接泛化。根据偏序关系可生成格的Hasse图:如果H2 <H1 ,且不存在另一个元素H3 使得H2 <H3 <H1 ,则从H1 到H2 就存在一条边[66] 。
② 自底向上的 FCA-Merge 本体合并。 该方法并不直接处理本体映射,而是使用形式化概念分析技术,以一种自底向上的方式来合并两个共享相同实例集的本体。整个本体合并的过程分三步。
(a)实例提取。由于 FCA-Merge 方法要求两个本体具有相同的实例集合,为达到这个目的,首先从同时与两本体相关的文本集合中抽取共享实例。从相同的文本集合为两个本体提取实例能够保证两本体相关的概念具有相近的共享实例集合。而共享实例是用来识别相似概念的基础,因此,提取共享实例是该方法实现的保证,同时提取出的实例质量也决定了最后结果的质量。这一步采用自然语言处理技术,得到两本体的形式背景。每个本体的形式背景表示为一张布尔表,表的行是实例,列是本体的概念,行列对应的位置表示实例是否属于概念;FCA-Merge将每个文本视为一个实例,如果某个文档是一个概念的实例,则它们在表中对应的值为真。显然,一个文档可能是多个概念的实例。
(b)概念格计算。输入第一步中得到的两张布尔表来计算概念格。FCA-Merge采用经典的形式化概念分析理论提供的算法,这些算法能根据两张形式化背景的布尔表自动生成一个剪枝的概念格[65,67,68] 。
(c)交互生成合并的本体。生成的概念格已经将独立的两个本体合并在一起。本体工程师根据生成的概念格,借助领域知识,通过与机器交互创建目标合并本体。显然,合并的本体实际上蕴涵了两个初始本体概念间的映射关系。
② FCA 总结。 形式化概念分析技术基于不同本体间的共享实例解决本体映射的发现问题,并有很好的形式化理论基础作为支持。这种方法能发现异构本体概念间的等价和包含映射,这样的映射是1∶1的简单类型。
FCA 具有一些不足。首先,该方法并没有考虑复杂概念间的映射,而且该方法的实现原理决定着它无法生成关系间的映射。其次,映射结果质量受提取共享实例过程的影响。最后,由概念格生成合并本体的工作由于人工参与,可能产生错误的映射结果。
4)IF-Map。 为了弥补很多本体映射方法缺乏形式化的理论基础的问题,Kalfoglou Y受形式化概念分析的影响,提出一个本体映射发现系统 IF-Map[69,70] 。该方法是一种自动的本体映射发现技术,基于信息流理论[71] 。
IF-Map 的基本原理是寻找两个局部本体间的等价,其方法是通过查看它们与一个通用的参考本体的映射。那样的参考本体没有实例,而实例只在局部本体中才考虑。因此, IF-Map 方法的核心在于生成参考本体和局部本体之间的可能映射,然后根据这些映射判断两局部本体间的等价关系。映射生成的过程包括4个阶段:①采集,即收集不同的本体;②转换,即将待映射本体转换为特定格式;③信息映射生成,即利用信息流理论生成本体间的映射;④映射投影,将生成的概念间等价映射用本体语言表示出来,如owl:sameAs等。
IF-Map也只能生成异构本体概念间的简单等价映射。
(3)基于实例的本体映射总结。 与基于术语和结构的映射发现方法相比,基于实例的本体映射发现方法更好,在映射的质量、类型和映射的复杂程度方面都取得了不错的结果。一些基于实例的方法能较好地解决异构本体概念间的映射问题,但对本体关系间的映射还缺乏有效方法和具体的实现。此外,基于实例的方法大多要求异构本体具有相同的实例集合,有些方法采用机器学习技术来弥补这个问题,而有的方法采用人工标注共享实例来解决这个问题;前一类方法的映射结果受到机器学习精度的影响,而后一类方法耗时费力,缺乏如何有效地建立共享实例集的方法。
3.综合方法
不同的映射方法具有各自的优点,但仅仅使用某一种方法又都不能完善地解决映射发现的问题。因此,为了得到更好的本体映射结果,可以考虑将多种映射方法综合使用,以吸收每种方法的优势。
(1)方法和工具
1)QOM。 QOM 是采用综合方法发现本体映射的典型工作[72-75] 。该方法的最大特点在于寻找映射的过程中同时考虑了映射结果的质量与发现映射的时间复杂度,它力图寻找到二者间的平衡。QOM 通过合理组织各种映射发现算法,在映射质量的损失可接受的前提下,尽量提高映射发现效率,因此该方法可以处理大规模本体间的映射发现问题。
① QOM 的思路。 大多数本体映射发现算法过于强调映射结果的质量,而往往忽略发现映射的效率。目前,绝大多数方法的时间复杂度为 O(n2 ),n 是映射对象的数目。对于大本体间的映射需求,如UMLS(107 个概念)与 WordNet(106 个概念)之间的映射而言,很多方法由于效率太低而无法实用。与这些方法不同,QOM 给出的映射发现方法同时考虑映射质量和运行时间复杂度,在提高映射发现效率的同时保证一定质量的映射结果。QOM只考虑异构本体间1∶1等价映射,映射对象包括概念、关系和实例。
② QOM 方法的过程。 QOM 处理本体映射的过程共分六步,输入异构本体,进行处理后得到本体间的映射。
步骤1。 特征工程:将初始的输入本体转换为相似度计算中使用的统一格式,并分析映射对象的特征。QOM使用RDF三元组形式作为统一的本体形式,其中考虑的映射对象特征包括:标识,即表示映射对象的专用字符串,如 URIs 或 RDF 标签;RDF(S)原语,如属性或子类关系;推导出的特征,由 RDF(S)原语推导出的特征,如最特化的类;OWL原语,例如考虑 sameAs 等表示等价的原语;领域中特定的特征,例如某领域中概念“Person”的实例都有“ID”属性,可用该属性值代替实例,方便处理。
步骤2。 搜索步骤的选择:由于各种相似度计算方法的复杂度与待映射的对象对直接相关,为了避免比较两个本体的全部对象,保证发现映射的搜索空间在能接受的范围内, QOM 使用启发式方法降低候选映射对象的数目,即它只选择那些必要的映射对象,而忽略其他不关心的映射对象。
步骤3。 相似度计算:对每一对候选映射对象,判断它们之间的相似度值。一个对象可被不同类型的信息描述,如 URIs 的标识和 RDF(S)原语等。QOM 定义了多种关于对象特征(包括概念、关系和实例)的相似度量公式,对于其中的每种度量,都预先分析它的时间复杂度。为了提高发现映射的效率,在选择度量公式的时候忽略那些复杂度过高的度量公式。
步骤4。 相似度累加:由于同时采用多种度量方法,一对候选对象通常存在多个相似度值。这些不同的相似度值需要累加,成为单个的相似度值。QOM 不采用直接累加方式,它强调一些可靠的相似度,同时降低一些并不可靠的相似度。
步骤5。 解释:利用设定的阈值或放松标签等技术,考虑本体结构和一些相似度准则,去除一些不正确的映射结果。根据处理后的最终相似度值判断本体之间的映射。
步骤6。 迭代:算法过程可迭代执行,每次迭代都能提高映射结果的质量,迭代可在没有新映射生成后停止。每次迭代时可基于贪婪策略从当前相似度最高的对象开始执行。
③ 实验评估和结果。 QOM 分析了几种典型的本体映射方法的时间复杂度。iPROMPT 的复杂度为O(n · log(n)),AnchorPROMPT 的复杂度为O(n2 · log2 (n)),GLUE 的复杂度为O( 2 n )。与这些方法相比,QOM 忽略一些造成较高复杂度的方法,将映射发现的时间复杂度控制为O(n · log(n))。注意,各种方法的时间复杂度并不是在同样的映射结果下给出的:iPROMPT 的时间复杂度虽然低,但映射结果的质量不尽如人意;GLUE 的时间复杂度虽然高,但映射结果质量却最好。试验结果表明,QOM 能在保证一定映射结果质量的前提下,尽量提高发现映射的效率。
2)OLA。 OLA 也是一种本体映射发现综合方法[76,77] ,具有如下特点:①覆盖本体所有可能的特征(如术语、结构和外延);②考虑本体结构;③明确所有的循环关系,迭代寻找最佳映射。目前,OLA实现了针对OWL-Lite描述的本体间的映射,并支持使用映射API[78] 。
OLA算法首先将OWL本体编码为图,图中的边为概念之间的关系。图节点之间的相似度根据两方面来度量:①根据类和它的属性将节点进行分类;②考虑分类后节点中的所有特征,如父类和属性等。实体之间的相似度被赋予权重并线性累加。
OLA能发现本体概念间的等价映射。
3)KRAFT。 KRAFT提出了一个发现1∶1的本体映射的体系结构[79,80] 。这些映射包括:①概念映射,源本体和目标本体概念间的映射;②属性映射,源本体与目标本体属性值间的映射,以及源本体属性名和目标本体属性名的映射;③关系映射,源本体和目标本体关系名间的映射;④复合映射,复合源本体表达式与复合目标本体表达式之间的映射。KRAFT并没有给出映射发现的方法。
4)OntoMap。 OntoMap是一个知识表示的形式化、推理和Web接口。它针对上层本体和词典[81] ,提供访问大多流行的上层本体和词典资源的接口,并表示它们之间的映射。
为统一表示本体和它们之间的映射,OntoMap 引入相对简单的元本体 OntoMapO。这个表示语言比 RDF(S)复杂,与 OWL Lite 相似,但它包括描述本体映射的特定原语。OntoMapO考虑的上层本体包括Cyc、WordNet和SENSUS等。映射语言中包括的映射原语有:①MuchMoreSpecific,表示两个概念的特化程度;②MuchMoreGeneral,与MuchMoreSpecific 相反;③TopInstance,最特化的概念;④ParentAsInstance 和ChildAsClass。这些原语表明了 OntoMapO 支持的映射类型。但遗憾的是,OntoMap 不能自动创建映射,它假设一个映射已存在或者能被手工创建。因此,OntoMap更多只是提供了一个映射的表示框架。
5)OBSERVER。 OBSERVER 系统是为了解决分布式数据库的异构问题,它通过使用组件本体和它们之间明确的映射关系解决数据库间的异构[82] ,同时它能维护这些映射。
OBSERVER 使用基于组件的方法发现本体映射。它使用多个预先定义的本体来表示异构数据库的模式。映射建立在这些本体之间,通过一个内部管理器提供不同组件本体之间的互操作,以及维护这些映射。OBSERVER能表示两个组件本体之间的1∶1映射,包括同义、上义、下义、重叠、不交和覆盖等。但是,该方法的本体映射依靠手工建立。
6)InfoSleuth。 InfoSleuth 是一个基于主体的系统,能够支持通过小本体组成复杂本体,因而一个小本体可以在多个应用领域使用[83,84] 。本体间的映射是概念间的关系。本体的映射由一个特殊的被称为“资源主体”的类完成。一个资源主体封装了本体映射的规则集,这些规则能被其他主体使用,辅助完成主体之间的信息检索。
7)基于虚拟文档的本体匹配。 瞿裕忠和胡伟等研究者给出了一种基于虚拟文档的通用本体匹配方法[85] ,该方法可有效地利用本体中的语义信息、文本信息和结构信息进行本体匹配,从而得到了广泛的推广和应用。
本体元素使用的词汇可能是独立的单词(如 Review),也可能是多个单词的组合形式(如 Meta_Reviewer),还可能是某些特殊的缩写(如 Stu_ID)。元素还可以通过自身注释中的简单语句,对其含义进行补充说明。此外,各种语义描述(例如概念的上下位关系等)也可转化为文本形式。因此,可以将本体中元素相关的文本组织为虚拟文档,然后用虚拟文档表示相应的元素。
一个元素的虚拟文档包含3种。①元素自身的描述文本Des(e):包括 local name、rdfs:lable、rdfs:comment,以及其他的注释文本,这些不同类型的文本可赋予[0,1]区间的权重。②空节点的描述文档Des(e):对于空节点类型的元素,虽然它没有描述自身的文本,但仍然可以根据和它相关的三元组中的其他非空节点进行描述,在这个描述过程中,如果存在其他的空节点,则这种描述迭代进行多次,直至收敛。在此过程中,越远的元素会被赋予越小的描述权重。③元素邻居的描述文本:根据三元组得到元素的邻居,并分别得到元素作为主语、谓语、宾语时的邻居文本。注意,如果这些邻居存在空节点,则采用空节点的描述方式进行描述。
在上述3种文档的基础上,给定一个元素e,它对应的虚拟文档为:
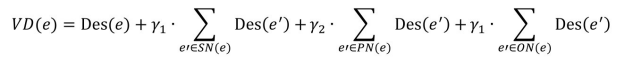
构造虚拟文档后,便可通过计算语义描述文档相似度来寻找异构本体元素间的映射。两元素的语义描述文档相似度越高,它们相匹配的可能性越大。描述文档根据本体对元素描述的语义特点被划分为不同的类型,所以相似度计算是在相同类型的文档中进行的。
虚拟文档的表示形式为带权重的词汇集合,即 DS={p1 W1 ,p2 W2 ,…,px Wx },该描述形式类似于文本向量空间模型,故可利用文本向量空间的余弦相似度衡量语义描述文本间的相似度。
基于虚拟文档的方法思想直观,易于实现,可用于各种包含丰富的文本信息的本体匹配情形。
(2)本体映射的综合方法总结。 考虑将多种映射方法综合使用,吸收每种方法的优点,能得到更好的本体映射结果。但综合使用多种方法要注意这些方法之间是否能改善映射质量,还要在映射的效率上进行权衡,因为可能引入一些方法会大大降低原有算法的效率。此外,将各种映射方法的结果进行综合也很重要。
5.3.4 本体映射管理
映射捕获了异构本体间的关系,但仅仅有映射还不足以解决多个异构本体间的知识共享。要在多本体环境中实现知识重用和协调多本体,还需要对多本体进行有效的管理。管理多个本体的好处在于:①方便处理多个本体的维护和演化问题;②合理组织本体间的映射,方便查询、数据转移和推理等应用;③将多个本体作为一个整体来使用,能为实际应用提供更强大的功能。这里讨论如何通过组织映射来达到管理异构的多本体的目的。
实际上,在数据库等领域中就有针对模式或模型管理的研究。Bernstein P A等人讨论了如何利用通用的模型管理功能降低模型间互操作的编程量[86] ,这种模型管理是为了支持模型的变化以及模型之间的映射。他们指出,模型间的映射和操作是模型管理的核心问题。
在本体研究领域,一些工作分析了本体管理的挑战[87,88] 。这些研究将本体管理的任务分为两方面。一个方面是设计本体库系统以增强本体管理,包括存储、搜索、编辑、一致性检查、检测、映射,以及不同形式间的转换等。另一方面则包括本体版本或演化,研究如何提供相应的方法学和技术,在不同的本体版本中识别、表示或定义变化操作。
Stoffel K等人设计了一个处理大规模本体的系统,使用高效内存管理、关系数据库二级存储,以及并行处理等方法,其目的是为在短时间内给出对大规模本体的复杂查询回答[89] 。Lee J 等人描述了一个企业级的本体管理系统,它提供API和查询语言来完成企业用户对本体的操作[90] ,他们还提供了如何用关系数据库系统有效地直接表示和存储本体的体系结构。Stojanovic L 等人提出一个本体管理系统 OntoManager[91] ,它提供一种方法学,指导本体工程师更新本体,使本体与用户需求保持一致;该方法跟踪用户日志,分析最终用户和基于本体的系统间的交互。显然,这些工作都关注本体的表示、存储和维护。而且这些方法只处理单个本体,没有考虑多个本体之间的映射或演化问题。但这些工作为管理多个本体打下了基础。
Noy N F和Musen M提出一个处理版本管理框架,使用PROMPTDiff算法识别出一个本体不同版本在结构上的不同[25] 。PROMPTDiff 只使用结构不同检测两个版本的不同。而在Klein M的方法中则有更多的选择,如日志的变化、概念化关系和传递集合等,这些都能提供更丰富的本体变化描述[92] 。Maedche A 等人提出一个管理语义 Web 上多本体和分布式本体的继承框架[93] ,它将本体演化问题分为三种情况:单个本体演化、多个相互依赖的本体演化和分布式本体演化。Klein M 分析本体演化管理的需求和问题,提出了本体演化的框架[94] ,基于一些变化操作,定义了一个变化说明语言。
从这些本体管理工作可以看出,目前多数本体管理工作关注本体演化或本体版本变化问题。这些工作在管理多本体的同时都忽略如何发挥多本体的潜在能量这一本质问题,即利用多本体实现更强大、灵活的、单本体无法提供的服务。
与目前大多工作侧重点不同,Xu Baowen等人从功能角度来探讨多本体管理[95] 。该思想认为,管理多本体的目标不仅是为了解决本体异构和最大限度地重用本体,而且要提供基于多本体的各种服务:多本体上的查询和检索,即通过有效管理本体间的简单和复杂映射,为本体间通信服务;本体间映射的管理是多本体中查询转换的保证;跨多本体的推理,即利用多本体间的映射支持跨多个本体的推理服务;抽取子本体,即从多本体抽取语义完全且功能独立的子本体,实现知识的重用;共享本体互操作,即描述多本体间概念和实例的转换规则;协调应用多个本体,进行多本体语义标注等应用。
传统的本体管理通常是二层结构:本体存储层和应用层。二层架构的多本体管理过于粗糙,提供的多本体功能嵌入具体的应用中,针对不同的应用都需要重新考虑本体间的映射,这导致大量工作的重复。Xu Baowen等人从管理多本体的映射来处理这些问题,首先利用桥本体将本体间的映射抽取出来,映射抽取出来后并不影响每个本体的独立性,通过管理和组织本体间的映射来协调本体。这样的管理方式具有灵活的特点,适应动态 Web环境。然后将多本体可提供的功能与应用分离,提供面向应用的通用功能,避免使用多本体时的大量重复工作。
Xu Baowen等人设计了一个五层体系结构的多本体管理框架。框架包括本体库层、本体表示层、描述本体间映射的桥本体层、多本体功能层和应用层。五层的多本体管理体系结构面向发挥多本体功能,它通过组织本体间的映射,将多个本体有机协调,为应用提供灵活和强大的功能。各层的具体功能如下:
① 本体库层。本体库层存放不同渠道获得的本体。本体由于创建者与创建时间不同,模型和本体语言上具有差异,例如DAML、RDF(S)或OWL等格式。
② 本体表示层。不同本体语言的语法、逻辑模型和表达能力都必然存在差异,因此需要将这些本体转换到统一的表示形式上来。这种转换会造成一些信息的损失。通常少许的非关键本体信息在转换中丢失是可容忍的。
③ 桥本体层。多本体间常常重叠,其间往往有关联。为有效使用多本体而避免本体集成,采用生成的桥本体来描述多本体间的沟通。桥本体是一特殊的本体,可表示本体间概念和关系的12种不同映射。在这层中,利用文献[62,36]的方法生成本体间的映射。桥的生成是半自动化的,并在桥本体中组织管理。
本体间映射生成过程无法避免语义冗余和冲突,有必要在使用前进行有效的化简。Xu Baowen等人分析了引入桥后的多本体环境的语义一致性检查问题和冗余化简算法[96] 。对于语义一致性问题,将引入桥后的多本体中的回路分为两种类型:良性回路和恶性回路。前者是由于引入等价桥后造成的,通过算法可消除。后者是由于原始本体中的错误或引入不当的桥造成的。算法能够找到环路,但区分恶性和良性环路需要人工参与。经过语义检查的多本体环境可当作有向无环图来处理,语义化简的目的就是要保证该图中的映射是无冗余的,同时化简操作不能改变整个多本体环境的连通性。
本体间映射抽取出来,可通过桥本体进行管理。当多本体环境中添加、删除或修改本体时,为减少重新生成映射的代价,需要设计高效的增量更新算法保证映射同步更新。
④ 多本体功能层。多本体的管理能提供满足应用需求的一些主要功能。第一,桥本体中的桥提供了大量的简单和复杂的本体映射。通过这些映射,很容易实现异构本体间的互操作问题。第二,利用多本体间的桥,能实现跨不同本体的推理。第三,能利用桥本体处理查询表达式的转换和重写,实现跨多本体的信息检索。第四,还可以从多本体中抽取满足需求的子本体。第五,还能利用多本体进行语义标注,提供比单本体更丰富的语义数据。
⑤ 多本体应用层。在应用层上,利用多本体的功能可以开发各种不同的应用,这些应用具有通用性。
5.3.5 本体映射应用
基于本体映射,能实现很多基于多本体的应用,例如子本体抽取与信息检索等,这里以子本体抽取为例给出本体映射在其中的应用;本体映射在信息检索中的应用将在随后的章节中详细讨论。
本体建模时总希望模型建立得尽量准确和完全,这往往导致大本体,如统一医学语言系统本体包括了多达80万个概念和900万个关系。大本体难以驾驭,而且在实际应用中往往只需其中与应用需求相关的一小部分。使用整个本体会大大增加系统的复杂性和降低效率。因此,从源本体中抽取一个小的子本体能让系统更有效。
子本体抽取是一个新的研究领域。Wouters C 等人提出物化本体视图抽取的顺序抽取过程[97] ,通过优化模式来保证抽取质量。该方法计算代价较高。随后的研究者提出了一种分布式方法来降低从大的复杂本体中抽取子本体的代价[98] 。Bhatt M 等人进一步分析了这种方法的语义完整性问题[99] 。Noy N F等提出的PROMPTFactor本体抽取工具也支持从单个本体中获得语义独立的子本体[25] ,其主要思想是通过用户选择所需要的相关术语,并与PROMPT系统进行交互抽取子本体。
当前的方法都是从单个本体中抽取子本体。但多本体环境下的应用很多,多个本体的不同部分都可能是子本体需要的。从多本体中抽取子本体对于知识重用具有重要意义,目前相关的工作和工具并不多见。Kang Dazhou等人探讨了从多本体中抽取子本体的方法[100] 。抽取子本体是一种重要的知识重用手段。本体映射表示了多本体间的联系,对解决从多本体中抽取子本体具有重要的作用。
在语义搜索和智能问答中,本体映射和匹配结果用于辅助查询重写,能有效地提高对用户问题的语义理解能力。