
6.2 基于演绎的知识图谱推理
6.2.1 本体推理
1.本体与描述逻辑概述
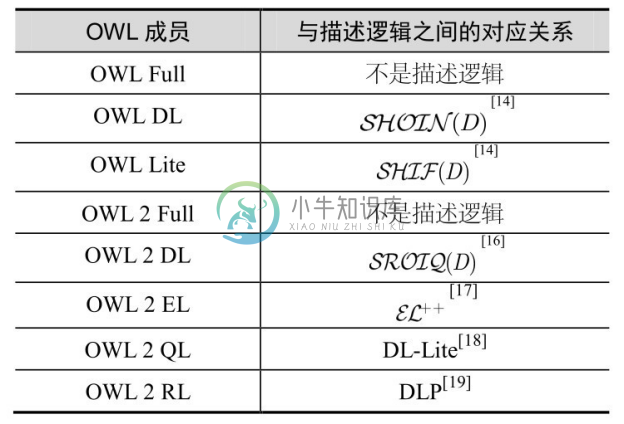
演绎推理的过程需要明确定义的先验信息,所以基于演绎的知识图谱推理多围绕本体展开。本体的一般定义为概念化的显示规约,它给不同的领域提供共享的词汇。因为共享的词汇需要赋予一定的语义,所以基于演绎的推理一般都在具有逻辑描述基础的知识图谱上展开。对于逻辑描述的规范,W3C 提出了 OWL。OWL 按表达能力从低到高划分成OWL Lite、OWL DL和OWL Full。OWL Lite和OWL DL在语义上等价于某些描述逻辑(Description Logics,DLs)[14,15] ,而OWL Full没有对应的描述逻辑。2009年,为了适应更多应用的需求,W3C组织又提出了OWL的新版本OWL 2[15] 。与OWL不同,OWL 2仅有对应的Full和DL层次。OWL 2 Full比OWL Full的表达能力更强,同样没有对应的描述逻辑。而OWL 2 DL比OWL DL的表达能力更强,仍有对应的描述逻辑[16] 。为了适应高效的应用需求,W3C组织从OWL 2中分裂出三种易处理的剖面OWL 2 EL、OWL 2 QL和OWL 2 RL。这些剖面都有对应的描述逻辑。表6-1总结了OWL成员与描述逻辑之间的对应关系。目前,OWL 是知识图谱语言中最规范、最严谨、表达能力最强的语言,而且OWL基于RDF语法,使表示出来的文档具有语义理解的结构基础,OWL的另外一个作用是促进了统一词汇表的使用,定义了丰富的语义词汇。
表6-1 OWL成员与描述逻辑之间的对应关系
基于 OWL 的模型论语义,在丰富逻辑描述的知识图谱中,除了包含实体和二元关系,还包含了许多更抽象的信息,例如描述实体类别的概念以及关系之间的从属信息等。从而有一系列实用有趣的推理问题,包括:
(1)概念包含。判定概念C是否为D的子概念,即C是否被D包含。例如,在包含公理Mother⊑Women和Women⊑Person的本体中,可以判定Mother⊑Person成立。
(2)概念互斥。判定两个概念 C 和 D 是否互斥,即不相交。需要判定 C⊓D⊑⊥是否为给定知识库的逻辑结论。例如,在包含Man⊓Women⊑⊥的本体中,概念Man和Women是互斥的。
(3)概念可满足。判定概念 C 是否可满足,需要找到该知识库的一个模型,使 C 的解释非空。例如,包含公理Eternity⊑⊥的本体中,概念Eternity是不可满足概念。
(4)全局一致。判定给定的知识库是否全局一致(简称一致,Consistent),需要找到该知识库的一个模型。例如,包含公理 Man⊓Women⊑⊥、Man(Allen)和 Women (Allen)的本体是不一致的。
(5)TBox一致。判定给定知识库的TBox是否一致,需要判定TBox中的所有原子概念是否都满足。例如,包含公理 Man⊓Women⊑⊥、Professor⊑Man 和 Professor⊑Women的TBox是不一致的。
(6)实例测试。判定个体a是否是概念C的实例,需要判定C(a)是否为给定知识库的逻辑结论。
(7)实例检索。找出概念 C 在给定知识库中的所有实例,需要找出属于 C 的所有个体a,即C(a)是给定知识库的逻辑结论。
2.基于Tableaux的本体推理方法
基于表运算(Tableaux)的本体推理方法[20] 是描述逻辑知识库一致性检测的最常用方法。基于表运算的推理方法通过一系列规则构建 Abox,以检测可满足性,或者检测某一实例是否存在某概念,基本思想类似于一阶逻辑的归结反驳。
以一个例子阐述该方法的基本思想。假设知识库K由以下三个声明构成:
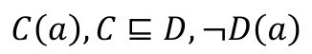
将以a作为实例的所有概念的集合记作 L(a)。我们使用L←C表示![]() 通过加入C进行更新。例如,如果
通过加入C进行更新。例如,如果![]() ={D}而且通过
={D}而且通过![]() ←C来对
←C来对![]() 进行更新,那么
进行更新,那么![]() 将变成{ C,D }。
将变成{ C,D }。
在给出的例子中,不经推导可以得到![]() 。TBox 声明C⊑D与
。TBox 声明C⊑D与![]() 等价。因此,通过
等价。因此,通过![]() ,得到
,得到![]() ,得到了矛盾,这表明K是不一致的。
,得到了矛盾,这表明K是不一致的。
在上面例子中构建的东西实质上是表的一部分。表是表达知识库逻辑结论的一种结构化方法。如果在表构建过程中出现矛盾,那么知识库是不一致的。
以描述逻辑![]() 为例,在初始情况下,
为例,在初始情况下,![]() 是原始的Abox,迭代运用如下规则:
是原始的Abox,迭代运用如下规则:

其中,y是新加进来的个体。

给定包含如下公理和断言的本体:Man⊓Women⊑⊥,Man(Allen),检测实例 Allen 是否在 Woman 中。首先,加入待反驳的结论 Woman(Allen),根据⊓− −规则,Man⊓Women(Allen)加入![]() 中,再通过⊑−规则得到⊥(Allen),这样就得到了一个矛盾,所以拒绝现在的
中,再通过⊑−规则得到⊥(Allen),这样就得到了一个矛盾,所以拒绝现在的![]() ,即Allen不在Woman中。
,即Allen不在Woman中。
为了提高Tableaux算法的效率,研究者提出了不少优化技术[20-22] ,使该算法对于中小型描述逻辑知识库的推理达到了实用化的程度。目前,前沿的超表运算(Hypertableau)技术[23] 进一步提高了Tableaux算法的效率,并能处理表达能力很强的描述逻辑。
目前,已经有不少公开的基于表运算的OWL推理系统,比较著名的包括FaCT++ [1] 、RacerPro [2] 、Pellet [3] 和HermiT [4] ,其中HermiT是目前唯一实现了Hypertableaux算法[23] 的开源OWL推理系统。
虽然Tableaux算法是最通用的描述逻辑知识库一致性的检测方法,但是这类算法并不一定具有最优的最坏情况组合复杂度。例如,针对 SHOIN 知识库进行一致性检测的问题是NExpTime-完全问题,但是针对SHOIN的Tableaux算法需要非确定性的双指数级的计算空间[22] ,而能处理 SHOIN 的 Hypertableaux 算法的组合复杂度也达到了2NExpTime 级别[23] 。因此,如何为SHOIN等强表达力的描述逻辑设计最优组合复杂度的Tableaux算法仍有待研究。
3.常用本体推理工具简介
(1)FaCT++。FaCT++是曼彻斯特大学开发的描述逻辑推理机,使用 C++实现,且能与Protégé集成。Java版本名为Jfact,基于OWL API。构建推理机采用下面的代码:
![]()
采用以下代码对本体进行分类:
![]()
(2)Racer。Racer 是美国 Franz Inc.公司开发的以描述逻辑为基础的本体推理机,也可以用作语义知识库,支持OWL DL,支持部分OWL 2 DL并且支持单机和客户端/服务器两种模式,用Allegro Common Lisp实现。以下代码可以进行TBox推理:
![]()
以下代码可对ABox进行推理:
![]()
(3)Pellet。Pellet是马里兰大学开发的本体推理机,支持OWL DL的所有特性,包括枚举类和XML数据类型的推理,并支持OWL API以及Jena的接口。构建推理机采用以下代码:
![]()
通过查询接口进行推理,采用下面的代码:
![]()
(4)HermiT。HermiT是牛津大学开发的本体推理机,基于Hypertableaux运算,比其他推理机更加高效,支持OWL 2规则。构建推理机采用以下代码:
![]()
不一致推理采用以下代码:
![]()
表6-2为本体推理工具总结。
表6-2 本体推理工具总结

6.2.2 基于逻辑编程的推理方法
1.逻辑编程与Datalog简介
逻辑编程是一族基于规则的知识表示语言。与本体推理相比,规则推理有更大的灵活性。本体推理通常仅支持预定义的本体公理上的推理,而规则推理可以根据特定的场景定制规则,以实现用户自定义的推理过程。逻辑编程是一个很大的研究领域,在工业界应用广泛。逻辑编程也可以与本体推理相结合,集合两者的优点。
逻辑编程的研究始于Prolog语言[24,25] ,后来由ISO标准化。Prolog在多种系统中被实现,例如SWI-Prolog、Sicstus Prolog、GNU Prolog和XSB。Prolog在早期的人工智能研究中应用广泛,多用于实现专家系统。在通常情况下,Prolog 程序是通过 SLD 消解和回溯来执行的[25] 。运行结果依赖对规则内部的原子顺序和规则之间的顺序,因此不是完全的声明式的(declarative)。在程序存在递归的情况下,有可能出现运行无法终止的情况。
为了得到完全的声明式规则语言,研究人员开发了一系列 Datalog 语言。从语法上来说,Datalog程序基本上是Prolog的一个子集。它们的主要区别是在语义层面,Datalog基于完全声明式的模型论的语义,并保证可终止性。在本节中,将简要回顾 Datalog 语言的语法和语义,并展示如何在实践中使用它们。读者可参考文献[26] 获得更多关于逻辑程序的相关介绍。
2.Datalog语言
Datalog 语言是一种面向知识库和数据库设计的逻辑语言。便于撰写规则,实现推理。Datalog与OWL的关系如图6-2所示,其中OWL RL和RDFS处于OWL和Datalog的交集之中。OWL RL的设计目标之一就是找出可以用规则推理来实现的一个OWL的片段。
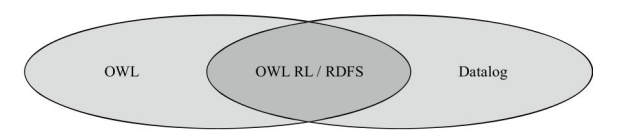
图6-2 Datalog与OWL的关系
Datalog 的基本符号有常量(constant)、变量(variable)和谓词(predicate)。常量通常用小写字母 a、b、c 表示一个具体的实例。变量用大写字母 X、Y、Z 表示,有时也会用问号(?)开头,例如?x、?y。项(term)包括常量和变量。原子(atom)形如p(t1 ,…,tn ),其中 p 是一个谓词,t1 ,…,tn 为项,n 被称为 p 的元数。例如,假定has_child为一个二元谓词,原子has_child(X, Y)表示变量X和Y有has_child的关系,而原子has_child(jim, bob)表示常量jim和bob有has_child的关系。
Datalog规则形如
H:-B1 , B2 ,…,Bm .
其中,H,B1 ,B2 ,…,Bm 为原子。H 称为此规则的头部原子,B1 ,B2 ,…,Bm 称为体部原子。规则的直观含义为:当体部原子都成真时,头部原子也应成真。
例如,规则 has_child(Y, X): -has_son(X,Y)表示当X和Y 有has_son 的关系时,则Y与X有has_child的关系。
Datalog事实(fact)是形如F(c1 ,c2 ,…,cn ):-的没有体部且没有变量的规则。事实也常写成“F(c1 ,c2 ,…,cn ).”的形式。
例如,规则has_child(alice, bob):- 即为一个事实,表示alice和bob有has_child的关系。
Datalog程序是规则的集合。例如,下面的两条规则构成了一个Datalog程序:
has_child(X,Y):-has_son(X,Y).
has_child(Alice,Bob).
3.Datalog推理举例
下面的规则集表达了给定一个图,计算所有的路径关系,即节点X、Y之间是否联通:
path(X,Y):-edge(X,Y). ①
path(X,Y):-path(X,Z),path(Z,Y). ②
节点X和Y联通有两种情况:①X、Y之间通过一条边(edge)直接连接;② 存在一个节点Z,使得X、Z联通并且Z、Y联通。
下面的三个事实表示了一个图中的三条边。
edge(a,b).edge(b,c).edge(d,e).
Datalog的语义通过结果集定义,直观来讲,一个结果集是Datalog程序可以推导出的所有原子的集合。
例如,上面的关于图联通的例子,结果集为{ path(a,b).path(b,c).path(a,c).path(d,e).edge(a,b).edge(b,c).edge(d,e)},如图6-3所示。
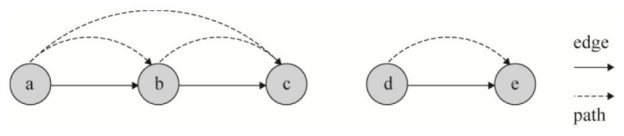
图6-3 Datalog推理举例
4.Datalog与知识图谱
Datalog 程序可以应用在知识图谱中进行规则推理。一个知识图谱可以自然地被看作一个事实集。只需人为引入一个特殊的谓词triple,每一个三元组(subject, property, object)便可以作为一个事实triple(subject, property, object)。另一种方法是按照描述逻辑ABox的方式来看待,即三元组 (s, rdf:type, C)看作 C(s),其他的三元组(s,p,o)看作p(s, o)。这样一来,Datalog 规则就可以作用于知识图谱上。下面介绍的三种语言 SWRL、OWL RL、RDFS与Datalog密切相关。
(1)SWRL(Semantic Web Rule Language)。SWRL 是2004年提出的一个完全基于Datalog的规则语言。SWRL规则形如Datalog,只是限制原子的谓词必须是本体中的概念或者属性。SWRL虽然不是W3C的推荐标准,但在实际中被多个推理机支持,应用广泛。
(2)OWL RL。OWL RL是W3C定义的OWL 2的一个子语言,其设计目标为可以直接转换成Datalog程序,从而使用现有的Datalog推理机推理。
(3)RDFS(RDF Schema)。RDFS 是 W3C 定义的一个基于 RDF 的轻量级的本体语言。RDFS的推理也可以用Datalog程序表示。RDFS的表达能力大体是OWL RL的一个子集。
5.基于Datalog的推理工具RDFox介绍
目前,最主要的 Datalog 工具包括 DLV [5] 和 Clingo [6] 。这两个工具都是一般性的Datalog 推理机,而不是专用于知识图谱。知识图谱领域也有多个系统,包括 KAON2 [7] 、HermiT [8] 、Pellet [9] 、Stardog [10] 、RDFox [11] 等,支持RL或者SWRL推理。Datalog相关工具总结如表6-3所示。下面简要介绍一下RDFox。
表6-3 Datalog相关工具总结
RDFox 是由牛津大学开发的可扩展、跨平台、基于内存的 RDF 三元组存储系统。其最主要的特点是支持基于内存的高效并行 Datalog 推理,同时也支持 SPARQL 查询。RDFox 的架构如图6-4所示。RDFox 的输入包括本体(TBox)、数据(ABox)和一个自定规则集。其核心为RDFox推理机,支持增量更新。
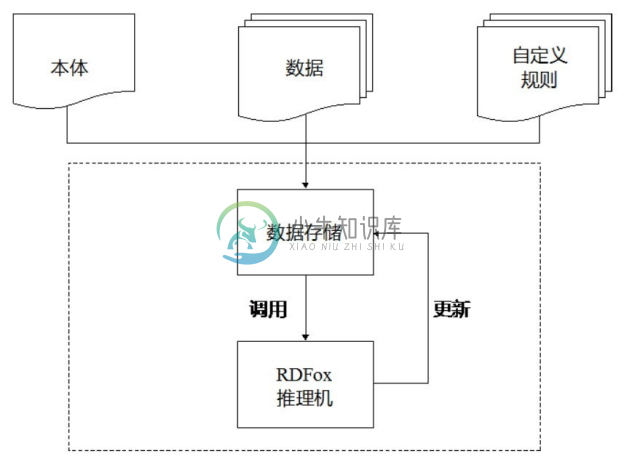
图6-4 RDFox的架构
1.RDFox Java API使用方法
(1)创建本体与存储

(2)导入本体进行推理
![]()
2.RDFox Java API使用举例
下面用一个具体的例子介绍RDFox。假定有如图6-5所示的某金融领域相关的图。
首先把它转换成一个知识图谱。对每一个实体,要创建一个 IRI。为此引入命名空间finance:来表示http://www.example.org/kse/finance#。
<http://www.example.org/kse/finance#孙宏斌>这个 IRI 就可以使用命名空间简写为“ finance:孙宏斌”。
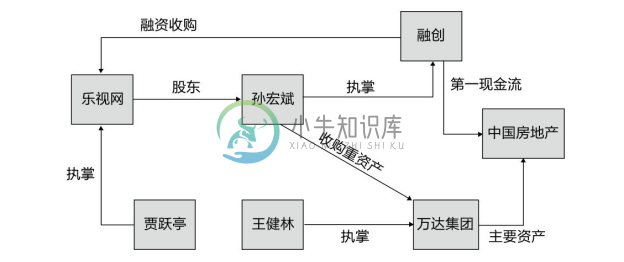
图6-5 某金融领域相关的图
一个三元组例子为:
finance:融创中国 rdf:type finance:地产事业本体(TBox)如下:
● SubClassOf(PublicCompany,Company) //类PublicCompany是Company的子类
● ObjectPropertyDomain(Control,Person) //属性Control的定义域是Person
● ObjectPropertyRange(Control,Company) //属性Control的值域是Company
此本体用RDF/XML的格式描述如下:

数据(ABox)用Triple的语法,如下所示。

自定义规则如下:
1)执掌一家公司就一定是这家公司的股东。
2)如果某人同时是两家公司的股东,那么这两家公司一定有关联交易。
用Datalog形式化,写成SWRL规则,具体如下:

下面演示如何使用代码(Java)数据读取本体、数据,声明规则并进行推理。
读取本体、数据,声明规则。
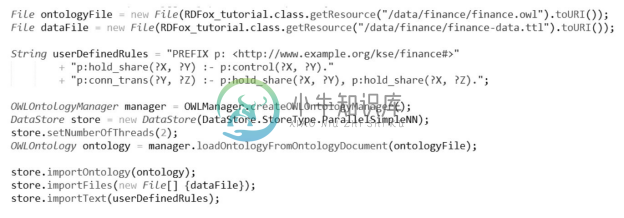
推理,定义命名空间与查询操作(用于输出当前三元组)。
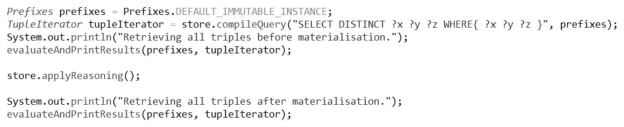
将结果输出为结合规则推理的所有三元组实例化。

6.2.3 基于查询重写的方法
本节介绍查询重写的方法实现知识图谱的查询。考虑两种情况,第一种情况是知识图谱已经存在,第二种情况是数据并不以知识图谱的形式存在,而是存在外部的数据库中(例如关系数据库)。
第一种情况直接在知识图谱之上的查询称为本体介导的查询回答(Ontology-Mediated Query Answering,OMQ)[27] 。在OMQ下,查询重写的任务是将一个本体TBox T上的查询q重写为查询qT ,使得对于任意的ABox A,qT 在A上的执行结果等价于q在(T, A)上的执行结果。
第二种情况称为基于本体的数据访问(Ontology-Based Data Access,OBDA)[28,29] 。在 OBDA 的情况下,数据存放在一个或多个数据库中,由映射(Mapping)将数据库的数据映射为一个知识图谱。映射的标准语言为W3C的R2RML语言。OMQ可以看作OBDA的特殊情况,即每个本体中谓词的实例都存储在一个特定的对应表中,而映射只是一个简单的同构关系。以下着重介绍OBDA。
1.OBDA框架
OBDA 框架包含外延(extensional)和内涵(intensional)两个部分。外延层为符合某个数据库架构(schema)S 的一个源数据库 D,S 通常包括数据库表的定义和完整性约束。内涵层为一个OBDA规范P =(T, M, S),其中T是本体,S是数据源模式,M是从S到 T 的映射。这样 OBDA 的实例定义为外延层和内涵层的一个对 I=(P,D),其中P=(T,M,S),且 D 符合 S。用 M(D)表示将映射 M 作用于数据库 D 上生成的知识图谱。给定这样一个OBDA实例I,OBDA的语义即定义为一个知识库(T,M(D))。
OBDA的主要推理任务为查询。当查询时,本体T为用户提供了一个高级概念视图数据和方便的查询词汇,用户只针对T查询,而数据库存储层和映射层对用户完全透明。这样OBDA可以将底层的数据库呈现为一个知识图谱,从而掩盖了底层存储的细节。
OBDA 有多种实现方式,最直接的方式是生成映射得到的知识图谱 M(D),然后保存到一个三元组存储库中,这种方式也称作ETL(Extract Transform Load),优点是实现简单直接。但是当底层数据量特别大或者数据经常变化时,或者映射规则需要修改时,ETL的成本可能很高,也需要额外的存储空间。在此,我们更感兴趣的是虚拟 OBDA 的方式,此方式下的三元组并不需要被真正生成,而通过查询重写的方式来实现,OBDA将在本体层面的 SPARQL 查询重写为在原始数据库上的 SQL 查询。相比于 ELT 的方式,虚拟OBDA方式更轻量化、更灵活,也不需要额外的硬件。为了保证可重写性,本体语言通常使用轻量级的本体语言DL-Lite,被W3C标准化为OWL 2 QL。
OBDA查询重写的流程如图6-6所示。给定一个OBDA 实例I=(P,D)、P=(T,S,M)以及一个SPARQL查询q,通过重写回答查询的具体步骤为:
(1)查询重写。对于 OMQ 的情况,利用本体 T 将输入的 SPARQL q 重写为另一个SPARQL。
(2)查询展开。将 SPARQL 利用映射 M 展开,把每一个查询中的谓词替换成映射中的定义,生成SQL语句查询[30] 。
(3)查询执行。将生成的SQL语句交给数据库引擎并执行。
(4)结果转换。SQL语句查询的结果做一些简单的转换,变换成SPARQL的查询结果。
为了实现更好的性能,实际使用的 OBDA 系统做了非常多的优化,实际的流程更加复杂[29] 。
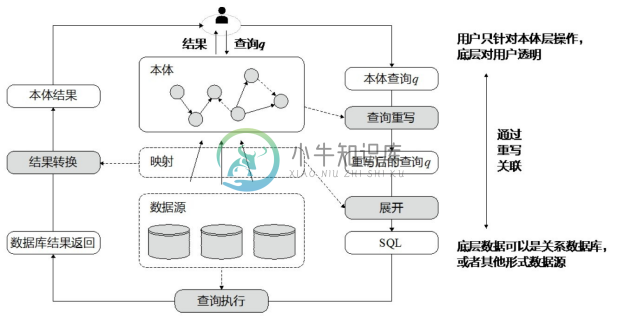
图6-6 OBDA查询重写的流程
2.查询重写举例(OMQ)
假定有如下一个关于学校信息系统的本体T:

查询q1 = SELECT ?teacher WHERE {?teacher a Teacher} 试图查询所有的教师。
通过层次关系和定义域可以被重写为q1'=

请注意 q1’包括了所有的已知教师和所有有教学任务的人。
查询q2 = SELECT ?teacher WHERE {?teacher a Teacher .?teacher teaches ?course .?course a Course .} 查询所有的教师和讲授的课程。
可以先利用teaches的定义域和值域将q2优化为
SELECT ?teacher ?course WHERE {?teacher teaches ?course }
然后重写为q2':

注意q2’只包括有教学任务的人。

可以重写为:

3.查询重写举例(OBDA)
现在假设数据实际是存在于一个关系数据库中。此数据库包含以下三个数据库表,其中下画线的列构成数据表的主键:

同时,假设有如下的映射规则:
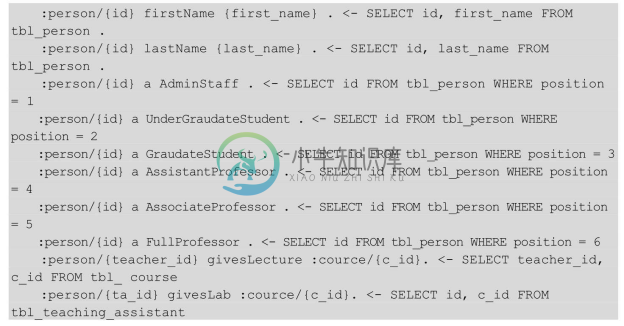
利用这些映射,q1’可以被展开为:

并进一步简化为:

查询q2’可以展开为:

并进一步简化为:

查询q3’可以展开为:


并进一步简化为:

这些生成的SQL语句可以直接在原始的数据库上运行。
4.相关工具介绍
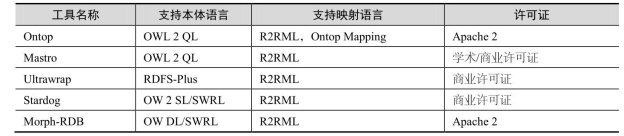
基于查询重写的推理机有多个,例如 Ontop [12] Mastro [13] 、Stardog [14] 、Ultrawrap [15] 、Morph [16] 。这些工具的功能对比如表6-4所示。
表6-4 基于查询重写的推理机工具的功能对比
Ontop 是由意大利博尔扎诺自由大学开发的一个开源的(Apache License 2.0)OBDA系统,现在由 Ontopic 公司提供技术支持。Ontop 兼容 RDFS、OWL 2 QL、R2RML、SPARQL标准,并支持主流关系数据库,如Oracle、MySQL、SQL Server、PostgreSQL。Ontop 的 Protégé插件可以用于编辑映射和测试查询。RDF4J 插件可以将编辑好的 OBDA系统发布为一个SPARQL endpoint。Ontop也提供Java API。
Mastro 最初是由意大利罗马大学开发的 OBDA 系统,现在由 OBDA Systems 商业化运行。此系统支持对 OWL2 QL 本体的推理。与此处提到的其他 OBDA 系统不同,它仅支持与合取查询相对应的SPARQL的受限片段。
Ultrawrap是由Capsenta公司商业化的OBDA系统。它被扩展为支持对具有反向和传递属性的RDFS扩展的推断。
Morph-RDB 是西班牙马德里工业大学开发的开源 OBDA 系统,不支持本体层面的推理能力。
Stardog原本是由Stardog Union开发的商业化的Triple存储工具。Stardog v4版中集成了Ontop代码以支持虚拟RDF图上的SPARQL查询。因此,它现在也可以归为OBDA系统。在v5版本中有了自己的OBDA实现。
5.OBDA的应用
OBDA在学术界和工业级有着广泛的应用,如石油与天然气领域,挪威国家石油公司[31] ;涡轮发电机故障诊断,西门子[32] ;数据集成解决方案,SIRIS Academic SL Barcellona[33] ;日志流程挖掘,KAOS 项目[34] ;文化遗产,EPNet 项目[35] ;海事安全,EMSec 项目[36] ;制造业,工业4.0[37] ;医疗保健,电子健康记录[38] ;政务信息,意大利公共债务[39] ;智慧城市,IBM爱尔兰[40] 。限于篇幅,不展开讲解,有兴趣的读者可以查阅参考文献[41] 。
6.2.4 基于产生式规则的方法
1.产生式系统
产生式系统是一种前向推理系统,可以按照一定机制执行规则并达到某些目标,与一阶逻辑类似,也有区别。产生式系统可以应用于自动规划和专家系统等领域。
一个产生式系统由事实集合、产生式集合和推理引擎三部分组成。
(1)事实集合。事实集合是运行内存(Working Memory,WM)为事实(WME)的集合,用于存储当前系统中的所有事实。事实可描述对象,形如(type attr_1:val_1 attr_2:val_2…attr_n:val_n),其中 type、attr_i、val_i 均为原子(常量)。例如,(student name:"Alice" age:24)表示一个学生,姓名为Alice,年龄为24。事实也可描述关系 (Refication)。例如,(basicFact relation:olderThan firstArg:John secondArg:Alice)表示John比Alice的年纪大,此事实也可简记为(olderThan John Alice)。
(2)产生式集合。产生式集合(Production Memory,PM)由一系列的产生式组成。
产生式形如:
●IF conditions THEN actions
其中,conditions 是由条件组成的集合,又称为 LHS;actions 是由动作组成的序列,又称为RHS。
LHS 是 conditions 的集合,各条件之间为且的关系。当 LHS 中所有条件均被满足时,触发规则。每个条件形如(type attr_1:spec_1 attr_2:spec_2…attr_n:spec_n)。其中, spec_i 表示对attr_i 的约束,形式可取下列中的一种:
● 原子,如:Alice (person name:Alice)
● 变量,如:x (person name:x)
● 表达式,如:[n+4] (person age:[n+4])
● 布尔测试,如:{>10} (person age:{>10})
● 约束的与、或、非操作
RHS是action的序列,执行时依次执行。动作的种类有如下三种:
●ADD pattern。向WM中加入形如pattern的WME。
●REMOVE i。从WM中移除当前规则第i个条件匹配的WME。
●MODIFY i (attr spec)。对于当前规则第i个条件匹配的WME,将其对应于attr属性的值改为spec。
例如,产生式 IF (Student name:)Then ADD (Person name:)表示如果有一个学生名为?x,则向事实集加入一个事实,表示有一个名为?x的人。
产生式具体语法因不同系统而异,某些系统中此产生式亦可写作 (Student name:x)⇒ADD (Person name:x)。
(3)推理引擎。推理引擎用于控制系统的执行。产生式系统执行流程如图6-7所示。
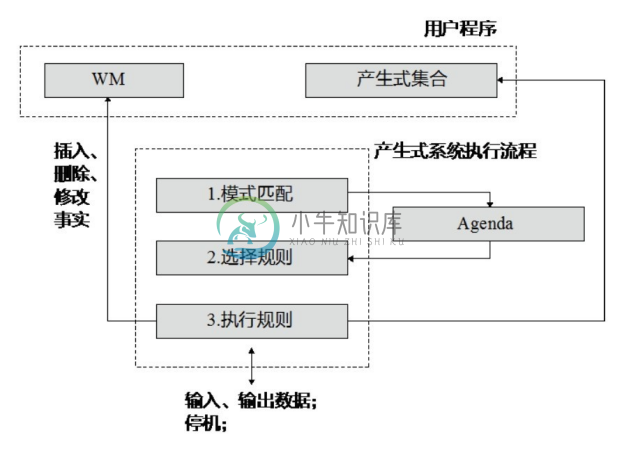
图6-7 产生式系统执行流程
产生式系统主要有三个部分:
●模式匹配。用规则的条件部分匹配事实集中的事实,整个 LHS 都被满足的规则被触发,并被加入议程(Agenda)。
●选择规则。按一定的策略从被触发的多条规则中选择一条。
●执行规则。执行被选择出来的规则的RHS,从而操作WM。
模式匹配用每条规则的条件部分匹配当前的WM,如图6-8所示为匹配规则过程。规则为:(type xy),(subClassOf yz)⇒ADD(type xz)。
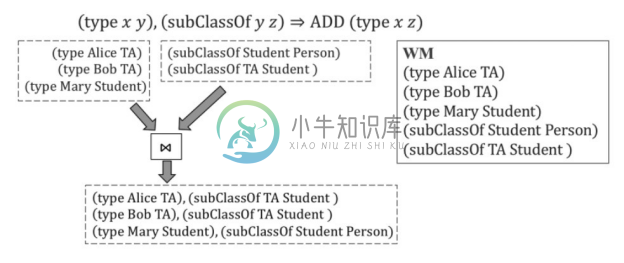
图6-8 匹配规则过程
高效的模式匹配算法是产生式规则引擎的核心。目前,最流行的算法是 Rete 算法,在1979年由 Charles Forgy 提出[42] 。其主要的想法为将产生式的 LHS 组织成判别网络形式,以实现用空间换时间的效果。
下面用图6-9和图6-10解释Rete算法的形状。最主要的部分为α网络和β网络。α和β的名字来源于产生式规则常写成α⇒β的形式。α网络对应条件,检验并保存各个条件对应的WME集合。β网络对应结果,用于保存join的中间结果。
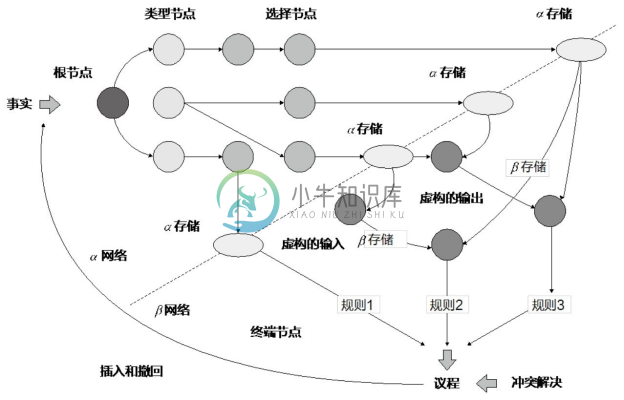
图6-9 Rete网络
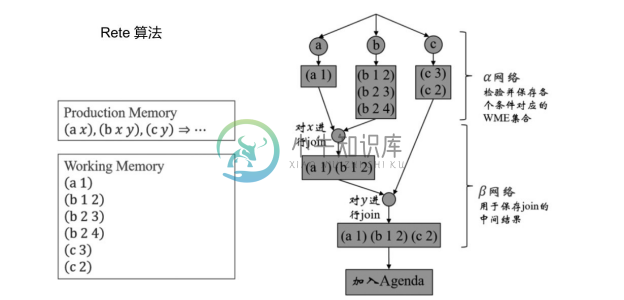
图6-10 Rete算法的匹配过程
选择规则从被触发的多条规则中选择一条执行,常用的策略有:
●随机选择。从被触发的规则中随机选择一条执行。注意在推理的场景下,被触发的多条规则可全被执行。
●具体性(specificity)。选择最具体的规则,例如下面的第二条规则比第一条更具体,故当同时满足时触发第二条:
(Student name:)⇒…
(Student name: age:20)⇒…
●新近程度(recency)。选择最近没有被触发的规则执行动作。
4.相关工具介绍
表6-5为三个基于产生式规则的系统,它们都是基于Rete算法或其改进的。
表6-5 三个基于产生式规则的系统

(1)Drools。 Drools 是一个商用规则管理系统,提供了一个规则推理引擎。核心算法是基于Rete算法的改进。提供规则定义语言,支持嵌入Java代码。
Drools使用举例:
创建容器与会话,如下:

触发规则,如下:
![]()
(2)Jena。 Jena是一个用于构建语义网应用的Java框架。提供了处理RDF、RDFS、OWL数据的接口,还提供了一个规则引擎。提供三元组的内存存储于SPARQL、查询。
Jena 使用举例:
创建模型,如下:
![]()
创建规则推理机,如下:

(3)GraphDB 。 GraphDB(原 OWLIM)是一个可扩展的语义数据存储系统(基于RDF4J),其功能包含三元组存储、推理引擎、查询引擎,支持 RDFS、OWL DLP、OWL Horst、OWL 2 RL等多种语言。