
2.5 知识图谱的向量表示方法
与前面所述的表示方法不同的是,本节要描述的方法是把知识图谱中的实体和关系映射到低维连续的向量空间,而不是使用基于离散符号的表达方式。
2.5.1 知识图谱表示的挑战
在前面提到的一些知识图谱的表示方法中,其基础大多是以三元组的方法对知识进行组织。在具体的知识库网络中,节点对应着三元组的头实体和尾实体,边对应着三元组的关系。虽然这种离散的符号化的表达方式可以非常有效地将数据结构化,但是在当前的大规模应用上也面临着巨大的挑战。
知识以基于离散符号的方法进行表达,但这些符号并不能在计算机中表达相应语义层面的信息,也不能进行语义计算,对下游的一些应用并不友好。在基于网络结构的知识图谱上进行相关应用时,因为图结构的特殊性,应用算法的使用与图算法有关,相关算法具有较高的复杂度,面对大规模的知识库很难扩展。
数据具有一定的稀疏性,现实中的知识图谱无论是实体还是关系都有长尾分布的情况,也就是某一个实体或关系具有极少的实例样本,这种现象会影响某些应用的准确率。
从上面的问题可以看出,对于当前的数据量较大的知识图谱、变化各异的应用来说,需要改进传统的表示方法。
2.5.2 词的向量表示方法
在介绍有关知识图谱的向量表示方法之前,在此先介绍词的表示方法。在自然语言处理领域中,因为离散符号化的词语并不能蕴涵语义信息,所以将词映射到向量空间,这不仅有利于进行相应的计算,在映射的过程中也能使相关的向量蕴涵一定的语义。知识图谱中的向量表示方法也在此次有所借鉴。
1.独热编码
传统的独热编码(One-Hot Encoding)方法是将一个词表示成一个很长的向量,该向量的维度是整个词表的大小。对于某一个具体的词,在其独热表示的向量中,除了表示该词编号的维度为1,其余都为0。如图2-19所示,假如词Rome的编号为1,则在其独热编码中,仅有维度1是1,其余都是0。这种表示方法虽然简单,但是可以看出其并没有编码语义层面的信息,稀疏性非常强,当整个词典非常大时,编码出向量的维度也会很大。
2.词袋模型
词袋模型(Bag-of-Words,BoW)是一种对文本中词的表示方法。该方法将文本想象成一个装词的袋子,不考虑词之间的上下文关系,不关心词在袋子中存放的顺序,仅记录每个词在该文本(词袋)中出现的次数。具体的方法是先收集所有文本的可见词汇并组成一个词典,再对所有词进行编号,对于每个文本,可以使用一个表示每个词出现次数的向量来表示,该向量的每一个维度的数字表示该维度所指代的词在该文本中出现的次数。如图2-20所示,在文本doc_1中,Rome出现32次,Paris出现14次,France出现0次。
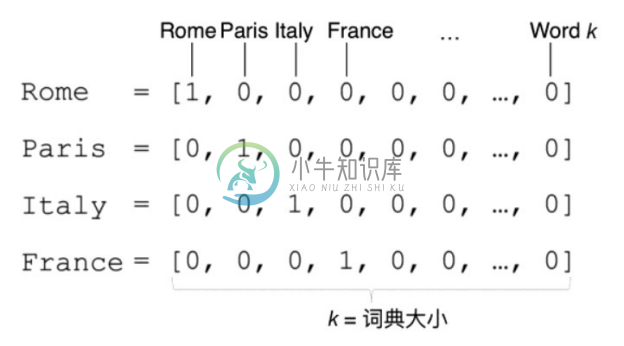
图2-19 独热编码示例1

图2-20 独热编码示例2
3.词向量
上面对词的表示方法并没有考虑语义层面的信息,为了更多地表示词与词之间的语义相似程度,提出词的分布式表示,也就是基于上下文的稠密向量表示法,通常称为词向量或词嵌入(Word Embedding)。产生词向量的手段主要有三种:
●Count-based。基于计数的方法,简单说就是记录文本中词的出现次数。
●Predictive。基于预测的方法,既可以通过上下文预测中心词,也可以通过中心词预测上下文。
●Task-based。基于任务的,也就是通过任务驱动的方法。通过对词向量在具体任务上的表现效果对词向量进行学习。
对词向量的产生方法到现在为止有较多的研究,在本章中并不展开讨论,下面简单介绍经典的开源工具word2vec[8] 中包含的CBoW和Skip-gram两个模型。
CBoW也就是连续词袋模型(Continuous Bag-of-Words),和之前提到的BoW相似之处在于该模型也不用考虑词序的信息。其主要思想是,用上下文预测中心词,从而训练出的词向量包含了一定的上下文信息。如图2-21(a)所示,其中wn 是中心词, wn−2 ,wn−1 ,wn+1 ,wn+2 为该中心词的上下文的词。将上下文词的独热表示与词向量矩阵E相乘,提取相应的词向量并求和得到投影层,然后再经过一个 Softmax 层最终得到输出,输出的每一维表达的就是词表中每个词作为该上下文的中心词的概率。整个模型在训练的过程就像是一个窗口在训练语料上进行滑动,所以被称为连续词袋模型。
Skip-gram 的思想与 CBoW 恰恰相反,其考虑用中心词来预测上下文词。如图2-21 (b)所示,先通过中心词的独热表示从词向量矩阵中得到中心词的词向量得到投影层,然后经过一层 Softmax 得到输出,输出的每一维中代表某个词作为输入中心词的上下文出现的概率。
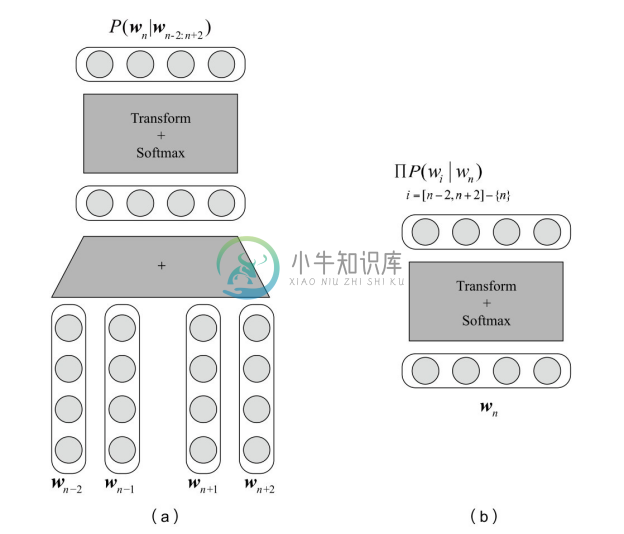
图2-21 CBoW模型
在训练好的词向量中可以发现一些词的词向量在连续空间中的一些关系,如图2-22所示。
vec(Rome)−vec(Italy)≈vec(Paris)−vec(France)
可以看出,Roma 和 Italy 之间有 is-capital-of的关系,而这种关系恰好也在Paris 和 France之间出现。通过两对在语义上关系相同的词向量相减可以得出相近的结果,可以猜想出 Roma 和 Italy 的词向量通过简单的相减运算,得到了一种类似 is-capital-of关系的连续向量,而这种关系的向量可以近似地平移到其他具有类似关系的两个词向量之间。这也说明了经过训练带有一定语义层面信息的词向量具有一定的空间平移性。

图2-22 词向量在连续空间中的关系
上面所说的两个词之间的关系,恰好可以简单地理解成知识图谱中的关系(relation)、(Rome, is-capital-of, Italy)和(Paris, is-capital-of, France),可以看作是知识图谱中的三元组(triple),这对知识图谱的向量表示产生了一定的启发。
2.5.3 知识图谱嵌入的概念
为了解决前面提到的知识图谱表示的挑战,在词向量的启发下,研究者考虑如何将知识图谱中的实体和关系映射到连续的向量空间,并包含一些语义层面的信息,可以使得在下游任务中更加方便地操作知识图谱,例如问答任务[9] 、关系抽取[10] 等。对于计算机来说,连续向量的表达可以蕴涵更多的语义,更容易被计算机理解和操作。把这种将知识图谱中包括实体和关系的内容映射到连续向量空间方法的研究领域称为知识图谱嵌入(Knowledge Graph Embedding)、知识图谱的向量表示、知识图谱的表示学习(Representation Learning)、知识表示学习。
类似于词向量,知识图谱嵌入也是通过机器学习的方法对模型进行学习,与独热编码、词袋模型的最大区别在于,知识图谱嵌入方法的训练需要基于监督学习。在训练的过程中,可以学习一定的语义层信息,词向量具有的空间平移性也简单地说明了这点。类似于词向量,经典的知识图谱嵌入模型TransE的设计思想就是,如果一个三元组(h, r, t)成立,那么它们需要符合h+r ≈ t关系,例如:
vec(Rome)+vec(is−capital−of)≈vec(Italy)
所以,在知识图谱嵌入的学习过程中,不同的模型从不同的角度把相应的语义信息嵌入知识图谱的向量表示中,如图2-23所示。
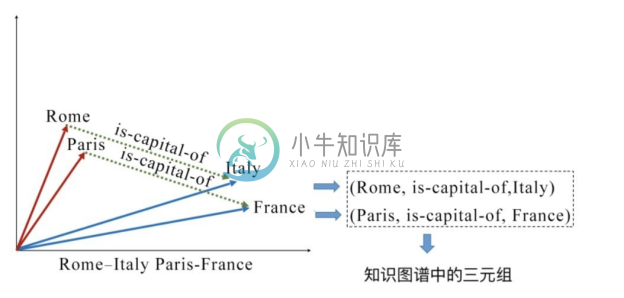
图2-23 语义信息嵌入知识图谱的向量表示中
2.5.4 知识图谱嵌入的优点
研究者将目光从传统的知识图谱表示方法转移到知识图谱的嵌入方法,是因为与之前的方法相比,用向量表达实体和关系的知识图谱嵌入方法有很多优点。
使用向量的表达方式可以提高应用时的计算效率,当把知识图谱的内容映射到向量空间时,相应的算法可以使用数值计算,所以计算的效率也会同时提高。
增加了下游应用设计的多样性。用向量表示后,知识图谱将更加适用于当前流行的机器学习算法,例如神经网络等方法。因为下游应用输入的并不再是符号,所以可以考虑的方法也不会仅局限于图算法。
将知识图谱嵌入作为下游应用的预训练向量输入,使得输入的信息不再是孤立的不包含语义信息的符号,而是已经经过一次训练,并且包含一定信息的向量。
如上所述,知识图谱的嵌入方法可以提高计算的效率,增加下游应用的多样性,并可以作为预训练,为下游模型提供语义支持,所以对其展开的研究具有很大的应用价值和前景。
2.5.5 知识图谱嵌入的主要方法
多数知识图谱嵌入模型主要依靠知识图谱中可以直接观察到的信息对模型进行训练,也就是说,根据知识图谱中所有已知的三元组训练模型。对于这类方法,常常只需训练出来的实体表示和矩阵表示满足被用来训练的三元组即可,但是这样的结果往往并不能完全满足所有的下游任务。所以,当前也有很多的研究者开始关注怎么利用一些除知识图谱之外的额外信息训练知识图谱嵌入。这些额外的信息包括实体类型(Entity Types)、关系路径(Relation Paths)等。
根据有关知识图谱嵌入的综述[11] ,将知识图谱嵌入的方法分类介绍如下。
1.转移距离模型
转移距离模型(Translational Distance Model)的主要思想是将衡量向量化后的知识图谱中三元组的合理性问题,转化成衡量头实体和尾实体的距离问题。这一方法的重点是如何设计得分函数,得分函数常常被设计成利用关系把头实体转移到尾实体的合理性的函数。
受词向量的启发,由词与词在向量空间的语义层面关系,可以拓展到知识图谱中头实体和尾实体在向量空间的关系。也就是说,同样可以考虑把知识图谱中的头实体和尾实体映射到向量空间中,且它们之间的联系也可以考虑成三元组中的关系。TransE[12] 便是受到了词向量中平移不变性的启发,在 TransE 中,把实体和关系都表示为向量,对于某一个具体的关系(head, relation, tail),把关系的向量表示解释成头实体的向量到尾实体的向量的转移向量(Translation vector)。也就是说,如果在一个知识图谱中,某一个三元组成立,则它的实体和关系需要满足关系head+relation≈tail。
2.语义匹配模型
相比于转移距离模型,语义匹配模型(Semantic Matching Models),更注重挖掘向量化后的实体和关系的潜在语义。该方向的模型主要是RESCAL[13] 以及它的延伸模型。
RESCAL模型的核心思想是将整个知识图谱编码为一个三维张量,由这个张量分解出一个核心张量和一个因子矩阵,核心张量中每个二维矩阵切片代表一种关系,因子矩阵中每一行代表一个实体。由核心张量和因子矩阵还原的结果被看作对应三元组成立的概率,如果概率大于某个阈值,则对应三元组正确;否则不正确。其得分函数可以写成
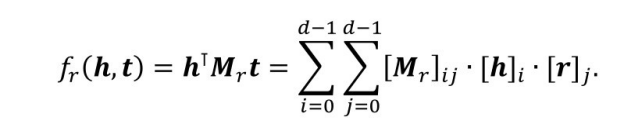
DistMul[14] 通过限制Mr 为对角矩阵简化 RESCAL 模型,也就是说其限制Mr =diag(r)。但因为是对角矩阵,所以存在h⊺ diag(r)t=t⊺ diag(r)h,也就是说这种简化的模型只天然地假设所有关系是对称的,显然这是不合理的。ComplEx[15] 模型考虑到复数的乘法不满足交换律,所以在该模型中实体和关系的向量表示不再依赖实数而是放在了复数域,从而其得分函数不具有对称性。也就是说,对于非对称的关系,将三元组中的头实体和尾实体调换位置后可以得到不同的分数。
3.考虑附加信息的模型
除了仅仅依靠知识库中的三元组构造知识图谱嵌入的模型,还有一些模型考虑额外的附加信息进行提升。
实体类型是一种容易考虑的额外信息。在知识库中,一般会给每个实体设定一定的类别,例如Rome具有city的属性、Italy具有country的属性。最简单的考虑实体类型的方法是在知识图谱中设立类似于IsA这样的可以表示实体属性的关系,例如
(Rome,IsA,city)
(Italy,IsA,Country)
这样的三元组。当训练知识图谱嵌入的时候,考虑这样的三元组就可以将属性信息考虑到向量表示中。也有一些方法[16] 考虑相同类型的实体需要在向量表示上更加接近。
关系路径也可以称为实体之间的多跳关系(Multi-hop Relationships),一般就是指可以连接两个实体的关系链,例如
(Rome,is−capital−of,Italy)
(Italy,is−country−of,Europe).
从 Rome 到 Europe 的关系路径就是一条is−capital−of→is−country−of关系链。当前很多方法也尝试考虑关系路径来提升嵌入模型,这里的关键问题是考虑如何用相同的向量表达方式来表达路径。在基于路径的 TransE,也就是 PTransE[17] 中,考虑了相加、相乘和RNN三种用关系表达关系路径的方法:
p=r1 +r2 +⋯+rl
p=r1 ∙r2 ∙⋯∙rl
ci =f(W[ci−1 ;ri ]).
在基于 RNN 的方法中,令c1 =r1 并且一直遍历路径中的关系,直到最终p=cn 。对于某一个知识库中存在的三元组,其两个实体间的关系路径p需要和原本两个实体间关系的向量表示相接近。
文本描述(Textual Descriptions)指的是在一些知识图谱中,对实体有一些简要的文本描述,如图2-24所示,这些描述本身具有一定的语义信息,对提高嵌入的质量有一定的提升。除了某些知识库本身具有的文本描述,也可以使用外部的文本信息和语料库。Wang[18] 提出了一种在知识图谱嵌入的过程中使用文本信息的联合模型,该模型分三个部分:知识模型、文本模型和对齐模型。其中,知识模型对知识图谱中的实体和关系做嵌入,这是一个 TransE的变种;文本模型对语料库中词语进行向量化,这是一个 Skip-gram模型的变种;对齐模型用来保证知识图谱中的实体和关系与单词的嵌入在同一个空间中。联合模型在训练时降低来自三个子模型的损失之和。

图2-24 文本描述示例
逻辑规则(Logical Rules)也是常被用来考虑的附加信息,这里讨论的重点主要是霍恩子句,例如简单规则
∀x,y:IsDirectorOf(x,y)⇒BeDirectedBy(y,x)
说明了两个不同的关系之间的关系。Guo[19] 提出了一种以规则为指导的知识图谱嵌入方法,其中提出的软规则(Soft rule)指的是使用AMIE+规则学习方法在知识图谱中挖掘的带有置信度的规则,该方法的整体框架是一个迭代的过程,其中包含两个部分,称为软标签预测阶段(Soft Label Prediction)和嵌入修正阶段(Embedding Rectification)。简单来说,就是讲规则学习和知识图谱嵌入学习互相迭代,最后使得知识图谱嵌入可以融入一定的规则信息。
2.5.6 知识图谱嵌入的应用
在知识图谱嵌入的发展中,也有很多的相关应用一起发展起来,它们和知识图谱嵌入之间有着相辅相成的关系。本小节将简单介绍一些典型的应用。
1.链接预测
链接预测(Link Prediction)指通过一个已知的实体和关系预测另一个实体,或者通过两个实体预测关系。简单来说,也就是(h,r,?),(?,r,t),(h,?,t)三种知识图谱的补全任务,被称为链接预测。
当知识图谱的嵌入被学习完成后,知识图谱嵌入就可以通过排序完成。例如需要链接预测(Roma, is-capital-of, ?),可以将知识图谱中的每个实体都放在尾实体的位置上,并且放入相应的知识图谱嵌入模型的得分函数中,计算不同实体作为该三元组的尾实体的得分,也就是该三元组的合理性,得分最高的实体会被作为链接预测的结果。
链接预测也常被用于评测知识图谱嵌入。一般来说,会用链接预测的正确答案的排序评估某种嵌入模型在链接预测上的能力,比较常见的参数有平均等级(Mean Rank)、平均倒数等级(Mean Reciprocal Rank)和命中前n(Hist@n)。
2.三元组分类
三元组分类(Triple Classification)指的是给定一个完整的三元组,判断三元组的真假。这对于训练过的知识图谱向量来说非常简单,只需要把三元组各个部分的向量表达带入相应的知识图谱嵌入的得分函数,三元组的得分越高,其合理性和真实性越高。
3.实体对齐
实体对齐(Entity Resolution)也称为实体解析,任务是验证两个实体是否指代或者引用的是同一个事物或对象。该任务可以删除同一个知识库中冗余的实体,也可以在知识库融合的时候从异构的数据源中找到相同的实体。一种方法是,如果需要确定 x、y 两个实体指代同一个对象有多大可能,则使用知识图谱嵌入的得分函数对三元组(x, EqualTo, y)打分,但这种方法的前提是需要在知识库中存在 EqualTo 关系。也有研究者提出完全根据实体的向量表示判断,例如设计一些实体之间的相似度函数来判断两个实体的相似程度,再进行对齐。
4.问答系统
利用知识图谱完成问答系统是该任务的一个研究方向,该任务的重心是对某一个具体的通过自然语言表达的问题,使用知识图谱中的三元组对其进行回答,如下:
A: Where is the capital of Italy?
Q: Rome(Rome, is-capital-of, Italy)
A: Who is the president of USA?
Q: Donald Trump(Donald Trump, is-president-of, USA)
文献[9]介绍了一种借助知识图谱嵌入完成该问题的方法。简单来说就是设计一种得分函数,使问题的向量表示和其正确答案的向量表示得分较高。S(q,a)是被设计出来的得分函数
S(q,a)=(Wφ(q))⊺ (Wψ(a)).
式中,W为包含词语、实体和关系的向量表示的矩阵;φ(q)为词语出现的稀疏向量;ψ(a)为实体和关系出现的稀疏向量。简单来说,Wφ(q)和Wψ(a)可以分别表示问题和答案的向量表示。当a是q的正确答案时,得分函数S(q,a)被期望得到一个较高的分数,反之亦然。
5.推荐系统
推荐系统的本质是对用户推荐其没有接触过的、但有可能会感兴趣或者购买的服务或产品,包括电影、书籍、音乐、商品等。协同过滤算法(Collaborative Filtering)对用户和物品项目之间的交互进行建模并作为潜在表示取得了很好的效果。
在知识图谱嵌入的发展下,推荐系统也尝试借助知识图谱的信息提高推荐系统的能力。例如,Zhang[20] 尝试知识图谱中的三元组、文本信息和图像信息对物品项目进行包含一定语义的编码得到相应的向量表示,然后使用协同过滤算法对用户进行向量表示,对两个向量表示相乘得到分数,得分越高说明该用户越喜好该商品。