
8.4 知识问答的评价方法
8.4.1 问答系统的评价指标
1.功能评价指标
问答系统通常可以通过一组预定的测试问题集以及一组预定的维度来评价。问答系统的功能评价重点关注返回的答案,正确的答案应当同时具备正确度及完备度,正确但内容不完整的答案被称为不准确答案,没有足够证据及论证表明答案与问题相关性的则是无支撑答案,当答案与问题完全无关时,意味着答案是错误的。答案评价通常可以从如下角度考虑:
(1)正确性。答案是否正确地回答了问题,例如问美国总统是谁,回答“女克林顿”就错了。
(2)精确度。答案是否缺失信息,例如问美国总统是谁,回答“布什”可能存在二义性,到底是老布什,还是小布什;答案中是否包含了多余的信息,同样的问题,“特朗普在纽约州出生”就包含了多余的信息。
(3)完整性。如果答案是一个列表,应当返回问题要求的所有答案。例如,列举美国总统,应该把所有满足条件的人都列举出来。
(4)可解释性。在给出答案的同时,也给出引文或证明说明答案与问题的关联。根据TREC的测试结果,考虑与未考虑文章支持度的测试结果差距可达十几个百分点。
(5)用户友好性。答案质量由人工评分,很多非事实性问题并非一个唯一的答案,所以需要人工判定答案的质量。如果答案被认为没错就按质量打分,Fair为1分、Good为2分、Excellent为3分,如果答不上来或答错则算零分。
(6)额外的评价维度。当答案类型更为复杂时,例如有排序、统计、对比等更多的要求,还应该有额外的评价维度。除了上述针对答案的评价,也有针对解答过程复杂程度的评价,例如 Semantic Tractability[33] ,用于反映问答之间的词表差异性;Answer Locality[34] ,答案是否零碎地分布在不同的文本或数据集录中;Derivability34 ,问题的答案是否是某种确定性答案,还是含蓄的、不确定的描述;Semantic Complexity,问题涉及的语义复杂程度。常用的问答指标采用 F1(综合正确率和召回率)和 P@1(第一个答案是否正确的比率)。
2.性能评价指标
除了功能评价指标,参考Usbeck R等人[35] 的评价体系,问答系统从性能角度可以考虑如下指标:
(1)问答系统的响应时间(Response Time)。问答系统对用户输入或者请求做出反应的时间。问答系统的响应时间是评价系统性能的一个非常重要的指标,如果响应时间过长,会使系统的可用性很低。一般问答系统的响应时间应控制在1s以内。
(2)问答系统的故障率(Error Rate)。在限定时间内给出答案即可,不考虑答案是否正确。系统返回错误或者系统运行过程中发生错误数的统计。
8.4.2 问答系统的评价数据集
1.TREC QA:评价IRQA
TREC QA[36] 是美国标准计量局在1999—2007年针对问答系统设定的年度评价体系,本文关注其问答的核心任务(MAIN TASK)。此评价体系主要针对基于搜索的问答解决方案(IRQA)。问题集主要来自搜索引擎的查询日志(也有少部分问题由人工设计)。知识库主要采用跨度几年的主流媒体的新闻。问答系统返回的结果包括两部分<答案,文档ID>,前者为字符串,后者为问题答案来源的文档的 ID。评价方法主要是选取大约1000个测试问题,由1~3人标注评价答案的正确性(答案是否正确回答了问题)、精准度(答案中是否包含多余的内容)以及对应文章的支持度(对应的文章是否支持该答案)。评价指标区分了单一答案和列表答案的评价方法。
2.TREC LIVE QA:评价CQA社区问答
TREC LIVE QA也[37] 是美国标准计量局在2015—2107年从更真实的网络问答出发,主要面向 CQA 社区问答解决方案的评价体系。问题集主要来自 Yahoo Answer 的实时新问题。 知识库主要来自Yahoo Answer 的社区问答数据,以及过往标注的千余条数据。评价方法主要选取大约1000个测试问题,每个问题要求在1min内回答。由于问题类型不限于简单知识问答,所有的答案由1~3人标注并直接按答案质量打{0,1,2,3}分。另外,评价系统也针对测试问题,获取赛后的社区人工答案做类似的评价,然后对比自动生成的答案和人工产生的答案的体验差异。
3.QALD:评价KBQA
QALD[38] 是指2011—2017年的链接数据的问答系统评测(Question Answering on Linked Data),为自然语言问题转化为可用的SPARQL查询以及基于语义万维网标准的知识推理提供了一系列的评价体系和测试数据集,对 QALD 的工作做了详细介绍。QALD的主要任务如下:给定知识库(一个或多个 RDF 数据集以及其他知识源)和问题(自然语言问题或关键字),返回正确的答案或返回这些答案的 SPARQL 查询。这样,QALD 可以利用工业相关的实际任务评价现有的系统,并且找到现有系统中的瓶颈与改进方向,进而深入了解如何开发处理海量 RDF 数据方法。这些海量数据分布在不同的数据集之间,并且它们是异构的、有噪声的,甚至结构是不一致的。每一年 QALD 通过不同的任务覆盖了众多的评价体系,包括:面向开放领域的多语种问答,例如 Task 1:Multilingual question answering over Dpedia;面向专业领域的问答,例如 MusicBrainz(音乐领域)、Drugbank(医药领域);结构化数据与文本数据混合的问答,例如 Task 2:Hybrid question answering;海量数据的问答,例如Task 3:Large-Scale Question answering over RDF;新数据源的问答,例如Task 4:Question answering over Wikidata。
4.SQuAD:评价端到端的问答系统解决方案
SQuAD[39] 是斯坦福大学推出的一个大规模阅读理解数据集,由众多维基百科文章中的众包工作者提出的问题构成,每个问题的答案都是相应阅读段落的一段文字或跨度。在500多篇文章中,有超过100,000个问题—答案对,SQUAD 显著大于以前的阅读理解数据集。2017—2018年,国内也有不少类似的阅读理解比赛,例如搜狗问答。SQuAD 评价指标主要分两部分:
(1)精准匹配。正确匹配标准答案,目前效果最好的算法达到74.5%,人类表现是82.3%。这个指标准确地匹配任何一个基本事实答案的预测百分比。
(2)F1值。这个指标衡量了预测和基本事实答案之间的平均重叠数。在给定问题的所有基础正确答案中取最大值 F1,然后对所有问题求平均值。2018年3月,谷歌公司的QAnet[40] 达到了F1=89.737,非常接近人工对比指标F1=91.221。
在此之前,斯坦福大学还发布过 Web Question 数据集[41] 。首先通过 Google Suggest API 获取只包含单个实体的问题,然后选取实体前面或后面的语句作为 query,以此作为种子进行问题扩充,每个 query 大约扩充5个候选问题,形成体量大约为100万的问题集;然后随机选取10万个问题,交由众包工作者搜集答案,并对每个答案给出答案来源URL;最后,对问答对进行筛选,形成包括3778条数据的训练集以及2032条数据的测试集。在Web Questions数据集上的F1值为31.3%,后续不少研究者在Web Questions 提出了一些新的有效模型,F1值逐年更新。目前,效果最好的模型是 Sarthak Jain 提出的Factual Memory Network模型[42] ,该模型的平均精确度为55.2%,平均召回率为64.9%,平均精确度和平均召回率的F1值为59.7%,平均F1值为55.7%。
5.Quora QA:评价问题相似度计算
Quora于2017年在Kaggle发布的数据集包含约40万个问题对,每个问题包含两个问题的 ID 和原始文本,另外还有一个数字标记这两个问题是否等价,即对应到同一个意图上。这个数据集主要用于验证社区问答或 FAQ 问答的语义相似度计算算法,目前在Kaggle 上的竞赛结果最优者的 Logloss 已经达到0.11。这个数据集来自社区问答网站Quora,这种规模抽样的数据的确存在少量噪声问题且话题分布并不一定与 Quora 网站的问题分布一致。另外,社区问答中只有少量问题是真正等价,因此通过 C(n,2)随机组合抽取两个问题,绝大多数问题对也不应该等价。这40万条数据首先加入了大量正例(等价的问题对),然后利用“related question”关系添加了负例(相关但不等价的问题对),这样才形成一个相对平衡的训练数据集。Elkhan Dadashov[43] 在Quora QA数据集上尝试了多种不同的LSTM模型,最好的模型的F1值达到了79.5%,准确率还到了83.8%。
6.SemEval:词义消歧评测
SemEval 是由 ACL 词汇与语义小组组织的词汇与语义计算领域的国际权威技术竞赛。从1998年开始举办,竞赛包括多方面不同的词汇语义评测任务,如文本语义相似度计算、推特语义分析、空间角色标注、组合名词的自由复述、文本蕴涵识别、多语种的词义消歧等。2018的Sameval比赛包含12个任务,主要包括以下几方面的内容:
(1)推特情感与创造性语句分析。该部分的处理对象来自推特的社交文本数据,其中涵盖英语、阿拉伯语以及西班牙语等多种语言的文本。分析的定位包括情感分析(情感的强弱、喜怒哀乐等类型的判断、情绪的积极消极以及识别推文中涵盖的多个情感类型)、符号预测(预测推文中可能嵌入的表情图片或颜文字)、反讽语义识别(识别推文中的讽刺表达)。
(2)实体关联。该部分包含两个子任务。一个子任务是多人对话中的人物识别,目标是识别对话中提及的所有人物。值得一提的是,这些人物并不一定是对话中的某个谈话者,可能是他们提及的其他人。如图8-18所示的多人对话场景,Ross 提到的“mom”并不是参与对话的某人,而是Judy。如何有效地识别出对话中提及人物的字符具体指向什么人物实体,是本任务需要解决的重要问题之一。另一个子任务则是面向事件的识别以及分析,针对给定的问题,从给定文本中找出问题相关的一个事件或多个事件,以及参与角色之间的关系。

图8-18 多人对话场景示例
(3)信息抽取。该部分介绍的信息抽取包含关系(关系抽取与分类)、时间(基于语义分析的时间标准化)等。如图8-19所示为时间信息的语义解析示例,对于文本“met every other Saturday since March 6”,其中的时间信息被解析为时间点与时间段并标准化表示出来。
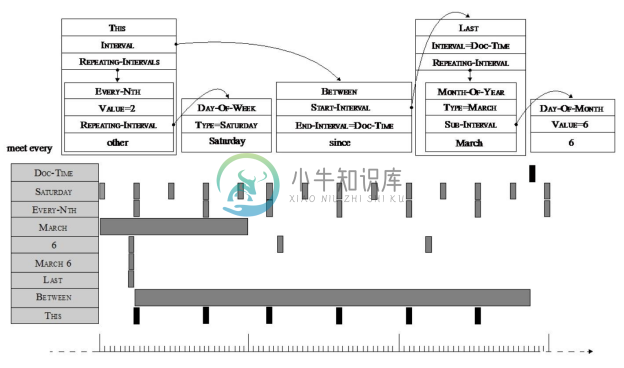
图8-19 时间信息的语义解析示例
(4)词汇语义学。该部分从词汇语义的角度入手,提出了用于反映词汇之间高度关系的上位调发现以及判别属性识别。与传统计算词汇语义相似不同,本任务关注词的语义相异性,目标是预测一个词是其他词的一个判别属性。例如,给定词语“香蕉”与“苹果”,词语“红色”可以作为判别属性区分两者的相异性。红色是苹果的一个颜色属性,但是与香蕉无关。
(5)阅读理解与推理。该部分由两个子任务构成,一个子任务是研究任务包括如何利用常识完成文本阅读理解,另一个子任务是通过推理方式对给定的由声明和理由组成的论点,从两个候选论据中选出正确的论据。