
7.3 语义数据搜索
目前,得益于 W3C 完成RDF语言和协议的标准化,互联网上的不同 RDF数据能够以 RDF 链接的形式链接在一起,形成一个完整的语义链接数据网络,也称作数据 Web。并且,不同的场景都能够有一个公共的术语词汇表,以及精确的术语含义说明。数据 Web提供了丰富的信息,很多传统的搜索引擎都尝试将链接数据整合到其搜索结果中,如图7-4所示。

图7-4 基于链接数据的语义搜索
然而,有效地对整个数据Web进行精准的语义搜索还面临如下挑战:
●可扩展性。对数据 Web 的有效利用要求基础架构能在大规模和不断增长的内链数据上扩展和应用。
●异构性。如图7-5所示,主要包括:如何进一步整合数据源(补充 RDF 链接);如何从不同的数据源中找到与查询相关的数据;如何合并来自不同数据源的查询结果。
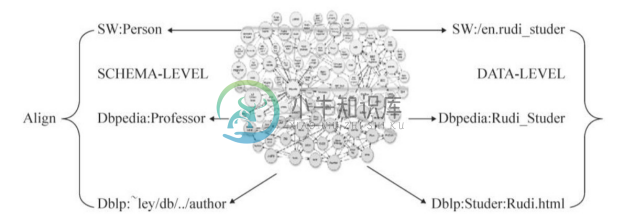
图7-5 多源知识图谱的异构性
●不确定性。用户事先不能准确地了解自己的需求,所以需求的描述往往不完整。这就要求语义搜索系统支持以不精确的方式匹配需求和数据,并对结果进行排序,能够足够灵活以应对条件的变化。
当前,链接数据比较成熟的语义搜索主要包括:面向本体的搜索引擎,如Swoogle[8] 、Watson[9] ;面向实体的搜索引擎,如Sigma on Sindice[10] 、FalconS[11] ;以及面向细粒度数据 Web 的搜索引擎,如 SWSE[12] 、Hermes(SearchWebDB)[13] 。这些搜索引擎的基本组成都包括三元组存储、索引构建、查询处理及排序等,具体内容如下:
1.三元组存储
基于 IR 的存储方式,即单一的数据结构和查询算法,针对文本数据进行排序检索来优化。其优点是高度可压缩、可访问,且排序是整个存储索引的组成部分,缺点是不能处理结构化查询中简单的选择、联结等操作。
基于 DB 的存储方式,即多种索引和查询算法,以适应各种结构化数据的复杂查询需求。其优点是能够完成复杂的选择、联结等操作,进而支持 SPARQL 结构化查询,并且能应对高动态场景(许多插入或删除),缺点是空间开销增大和访问有一定的局限性,并且无法集成对检索结果的排序。
原生存储(Native Stores)即直接以RDF图形式的存储方式。其优点是高度可压缩,可访问类似 IR 的检索排序,支持选择、联结等操作,并且可在亚秒级时间内在单台机器上完成对TB级数据的查询,以及支持高动态场景,缺点是没有事务、恢复等功能。
2.索引构建
目前主要的方式都是重用 IR 索引来索引 RDF 语义数据。IR 索引主要包括以下几个核心概念:文档、字段(例如,标题、摘要、正文……)、词语、Posting list 和 Position list[6] 。而利用IR索引来索引RDF数据的核心思想是将RDF转换成具有fields和terms的虚拟文档,如图7-6所示。

图7-6 基于IR索引的RDF语义数据索引示例
值得一提的是,语义 Web 上的链接数据规模已经非常庞大,不可能对其完全重建索引,需要采用增量索引的方法。在增量索引的过程中,因为移动大量元素非常耗时,所以还需要设计基于块的索引扩展,同时考虑块大小对索引性能的影响,最后做到权衡索引更新、搜索和索引块大小之间的平衡。
3.查询处理和排序
首先,查询处理的核心步骤是给定查询输入,将其构建成复杂的结构化查询。在此基础上,执行生成的结构化查询。不同拓扑结构的结构化查询的查询效率往往有很大不同[7] ,如图7-7所示,从DBpedia和LUBM[14] 的查询日志中抽取的5个典型的查询拓扑结构,其相应时间明显不同。所以,合理利用缓存可以大大提高效率,精心设计的查询功能的优化算法也可以缩短响应时间,效率和查询表达式的复杂程度之间总是有一个折衷点。

图7-7 不同拓扑结构的查询和其相应时间
对于查询结果的排序,通常需要考虑以下原则:
●质量传播(Quality Propagation)。一个元素的分数可以看成是其质量的度量,质量传播即通过更新这个分数,反映该元素的相邻元素的质量。例如,当查找匹配关键字“战争”的美国总统的接班人时,肯尼迪应该排在前面,因为他的前任总统艾森豪威尔与“战争”紧密相关。
●数量聚合。除质量外,还要考虑邻居的数量。因此,如果有更多的邻居,元素排名会更高。例如,在查询“找到图灵奖获得者工作的机构”,CMU、UC 伯克利和 IBM 是排在前三名的机构,因为他们拥有最多的图灵奖获得者。并且,排序方案需要满足单调性。
数据Web的查询及答案在通常情况下都涉及多个数据源,如图7-8所示。
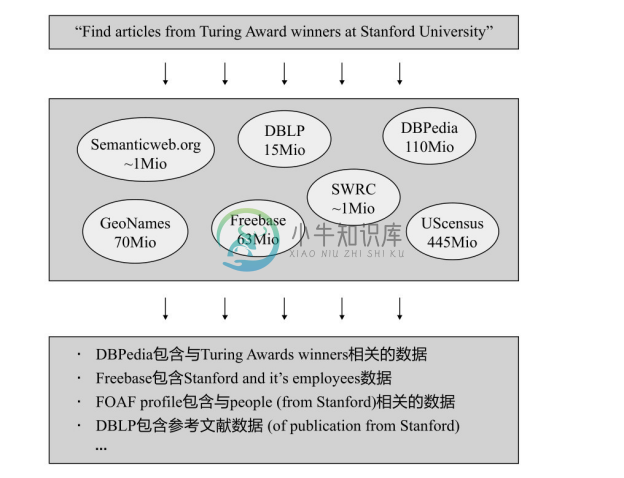
图7-8 涉及多数源的查询及答案
针对多数据源的情况,前提是对分布在不同数据源的数据进行融合,进而查询及处理,在多数据源、多存储的场景下进行语义数据搜索。Hermes 系统[13] 就是一个典型的多数据源语义数据搜索框架,如图7-9所示,包括数据源融合,用户意图理解以及搜索和优化。各个环节的详细内容感兴趣的读者可以查阅相关论文。

图7-9 Hermes多数据源语义数据搜索框架
语义数据搜索有多种研究原型,既可以直接应用 IR 技术以增强原有搜索系统的扩展性,也可以直接设计支持处理复杂查询的语义搜索系统,但是数据质量依然是一个问题,如何针对多数据源进行高质量的映射、理解用户的查询意图以及集成 IR 和 DB 排序以处理复杂查询,是未来设计语义数据搜索的关键。