
8.6 开源工具实践
8.6.1 使用Elasticsearch搭建简单知识问答系统
本书第7章介绍了如何基于 Elasticsearch 实现简单的语义搜索,本节则基于Elasticsearch 展示简单的知识问答系统。两个案例的基本框架一致,而知识问答增加了将自然语言问题转化为对应逻辑表达式以及查询语句的过程。因此,本小节通过一个简单案例介绍自然语言问题到 Elasticsearch 查询语句的转化,而用 Elasticsearch 查询语句进行查询即可得到问答结果。注意,真实的知识问答系统的语义理解远比本文方案复杂。
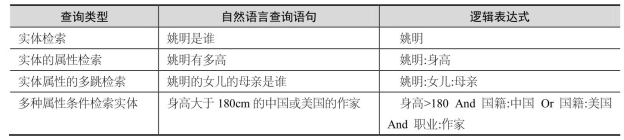
自然语言问题对应的查询类型同本书第7章中的语义检索,如表8-4所示,主要包含四种类型的查询,即实体检索、实体属性检索、实体属性的多跳检索以及多种属性条件检索实体。
表8-4 自然语言问题的四种类型
自然语言问题转化为逻辑表达式的过程如下:
(1)定义逻辑表达式模板。如表8-5所示,逻辑表达式的基本元素是三元组的成分,包含S(Subject,主语)、P(Predicate,谓语)和O(Object,宾语)。当P是属性时,可以定义属性条件的运算,相关运算符(OP)包括“<”(小于)、“>”(大于)、“<=”(小于或等于)、“>=”(大于或等于)、“:”(属性),属性条件形式表示为“<P> <OP> <O>”,例如“职业:演员”,“身高>180”。多个属性条件之间可以用逻辑链接符“And”和“Or”连接,表示条件间并且和或者的关系,例如“职业:作家 And 身高>180”。
表8-5 自然语言问题对应的逻辑表达式模板

(2)解析自然语言问题。从自然语言问题中识别出实体名、属性名和属性值等三类要素,并将实体名和属性名映射到知识库中的实体和属性。首先,实体和属性的识别可以采用词典的方法,例如从知识库中抽取所有的实体名和属性名,构建分词器的自定义词典。然后,对自然语言问题进行分词,可直接识别其中的属性名和实体名。其次,属性值的识别比较困难,由于取值范围变化较大,可以采用模糊匹配的方法,也可以采用分词后 n-gram检索Elasticsearch的办法。最后,查看自然语言问题中属性值和属性名的对应关系,当某属性值没有对应的属性名时,例如“(国籍是)中国(的)运动员”,缺省了“国籍”,就用该属性值对应的最频繁的属性名作为补全的属性名。例如下面的两段代码,分别实现了属性名识别和实体名识别。

(3)后生成逻辑表达式。在识别出自然语言问题中所有的实体名、属性名和属性值后,依据它们的数目及位置,确定问题对应的查询类型,以便基于逻辑表达式模板生成对应的逻辑表达式。逻辑表达式生成流程如下:查询中含有实体名。如果有多个属性名,那么是属性值的多跳检索;如果有一个属性名,则需判断实体名和属性名的位置及中间的连接词(“是”“在”“的”等),若实体名在前,则是实体的属性查询,例如“姚明的身高”,若属性名在前,则是依据属性查询实体,例如“女儿是姚沁蕾”。查询中没有实体名,则认为是依据属性查询实体,需要根据所有属性名和属性值位置的相对关系确定它们之间的对应关系。如果缺少属性名但有属性值,则需补全对应的属性名;如果缺少属性值但有属性名,例如“身高大于180cm”,则需通过正则表达式识别出范围查询的属性值。工业应用中抽取属性也会采用文法解析器、序列化标注、数字识别与解析等技术。
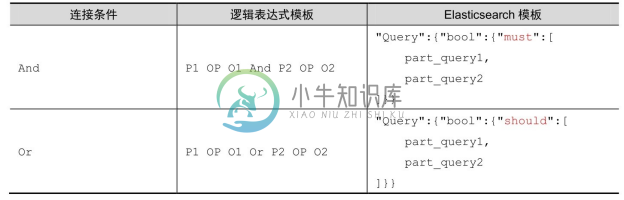
在生成逻辑表达式之后,可基于查询的类型及要素,直接用对应的 Elasticsearch 查询模板将逻辑表达式翻译成 Elasticsearch 查询。本方法定义了一组 Elasticsearch 查询模板,基于该模板将逻辑表达式按照一定的层次结构自动转换成Elasticsearch查询语句。如表8-6所示,对于实体属性查询,包括多跳检索,都是先检索实体,然后获取对应的属性。如表8-7所示,对于多个属性条件检索实体,先为每种单个的属性条件创建 Elasticsearch 查询,最后组合成完整的查询,表中part_query表示单个属性条件对应的部分查询。
表8-6 查询类型与Elasticsearch查询模板的映射关系
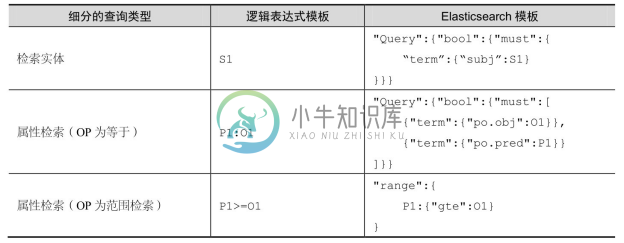
表8-7 多属性条件组合与Elasticsearch查询模板的映射关系
8.6.2 基于gAnswer构建中英文知识问答系统
本节进一步介绍一个真实的知识问答系统的架构与接口,帮助开发者理解如何使用知识问答系统。
gAnswer 系统[55] 是一个基于海量知识库的自然语言问答系统,针对用户的自然语言问题,能够输出SPARQL格式的知识库查询表达式以及查询答案的结果。gAnswer同时支持中文问答和英文问答。gAnswer参加了QALD-9的评测比赛,并取得了第一名的成绩。对于中文问答,使用PKUBASE知识库;对于英文问答,使用DBpedia知识库。本实践的相关工具、实验数据及操作说明由OpenKG提供,地址为http://openkg.cn。此外,我们给出了一个使用gAnswer进行英文问答的示例网站http://ganswer.gstore-pku.com/。如图8-33所示为 gAnswer 系统处理流程。主要分为三个阶段:构建语义查询图、生成 SPARQL 查询和查询执行。在构建语义查询图阶段,系统借助数据集的信息以及自然语言分析工具,对问句进行实体识别和关系抽取,构建语法依存树,并用这些结果构建对应的查询图。这时,并不对其中的实体和关系做消歧处理,而是利用谓词词典,记录词或短语可能对应的谓词或实体。在生成 SPARQL 查询阶段,系统利用查询图生成多个 SPARQL,并利用数据集中的部分信息对多个 SPARQL 进行过滤和优化,其中就包括歧义的消除。在查询执行阶段,借助gStore系统返回的SPARQL查询结果,返回并展示给用户。
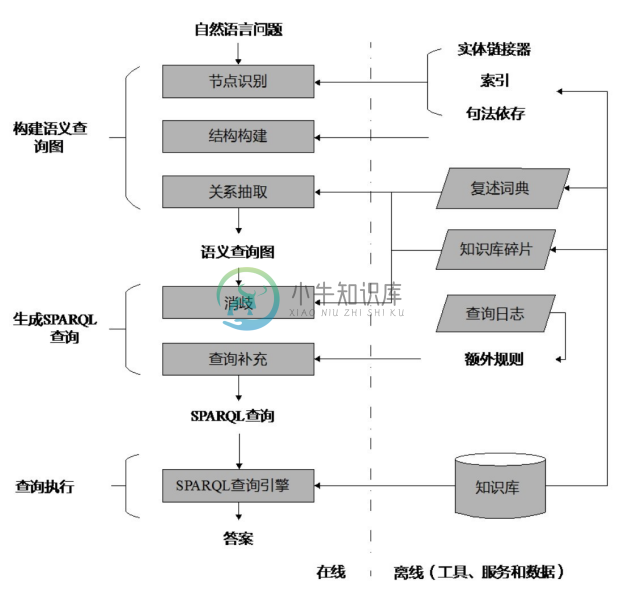
图8-33 gAnswer系统处理流程
1.系统配置需求
读者可以使用 gAnswer 系统构建自己的领域知识问答。在系统配置需求方面, gAnswer系统使用RDF格式的数据集,默认的中文数据集是PKUBASE,默认的英文数据集是DBpedia2016。gAnswer系统的运行需要借助支持SPARQL查询的图数据库系统来获取最终答案。在目前的版本中,使用 gStore 系统(http://openkg.cn/tool/gstore)。gAnswer的部署还依赖一些外部工具包。包括Maltparser、StanfordNLP,在生成SPARQL阶段,需要借助 Lucene 对辅助信息进行索引。gAnswer 为开发者提供了打包版本,安装流程如下:
(1)下载Ganswer.jar。访问地址为https://github.com/pkumod/gAnswer/releases。
(2)下载dbpedia16.rar数据文件。注意,完整的dbpedia16.rar数据文件需要较大的内存支持(20GB),也可以从 DBpedia 2016中选择下载抽取生成的小规模数据(5GB)。访问地址为https://github.com/pkumod/gAnswer/blob/master/README_CH.md。
(3)在控制台下解压 Ganswer.jar。用户可以解压到任意文件路径下,但需要保证Ganswer.jar文件与解压得到的文件处在统一路径下。
(4)在控制台下解压 data.rar。用户需要把解压得到的文件夹置于 Ganswer.jar 文件所在的路径下。
(5)在控制台下运行Ganswer.jar,等待系统初始化结束,出现“Server Ready!”字样后,说明初始化成功,使可以开始通过HTTP请求访问gAnswer服务了。
(6)配置外部第三方 API 接口。目前的 gAnswer 系统需要借助一些外部系统接口。在公开的版本中,提供了远程的外部系统调用函数,因此用户并不需要在自己的计算机上安装这些外部系统。但是,开发者强烈建议用户安装自己的版本,以保证性能。gStore, qa.GAnswer.getAnswerFromGStore2(),版本大于或等于 v0.7.0,访问地址为https://github.com/pkumod/gStore。DBpediaLookup,qa.mapping.DBpediaLookup,访问地址为https://wiki.dbpedia.org/lookup/
2.访问gAsnwer服务
KBQA的问答接口与常规问答的差异主要在返回结果上,具体说就是返回结果可以包括找到的实体、知识图谱的子图等结构化信息,然后利用自然语言生成技术将结构化结果展示为自然语言格式。gAnswer可以通过RESTful HTTP API通过发送JSON格式的数据进行交互。另外,在 gAnswer 源代码的 application.gAnswerHttpConnector 中给出了使用Java访问gAnswer系统的示例。
(1)配置输入参数。若提问“闻一多创作了哪些十四行诗?”输入参数如下:问题是“闻一多创作了哪些十四行诗?”要求最多返回3个不同的答案,1条生成的 SPARQL 查询。

(2)调用服务。将此 JSON 格式的数据转化为字符串,进行 URL 转码,然后使用ip:port/gSolve/?data=%json string%(在%json string%处放入 JSON 数据字符串)这一 URI来调用gAnswer系统。本地运行IP为localhost,默认端口为9999。在样例中,实际访问的URI为:
![]()
(3)解析返回结果。对于上例,返回的结果如下。需要特别说明的是,其中“vars”代表识别到的变量名,“results”中为实际得到的答案,“value”中为实际答案的值,“status”则说明这是一次正常的请求返回。

3.在新的知识库上运行
若更换知识库,使gAnswer系统在新的知识库上运行,需要更新查询引擎、离线索引和词典。下面具体说明。
将新的知识库组织成三元组形式,如下所示:


将 kb.txt 文件置于 data/kb/中。通过 gStore 查询引擎建立基于 kb.txt 的查询服务,访问地址为http://gstore-pku.com/。
根据kb.txt生成实体、谓词、类型的列表文件,如下所示:

将上述三个文件置于 data/kb/fragments/id_mappings 中。运行 src/fgmt/GenerateFragment.java,程序将产生三个编码后的碎片文件 entity_fragment.txt、predicate_fragment.txt 和type_fragment.txt并置于data/kb/fragments/中。以entity_fragment.txt为例,格式为
![]()
示例如下:

为提高效率,使用lucene建立索引。运行src/lcn/BuildIndexForEntityFragments.java和src/lcn/ BuildIndexForTypeShortName.java。程序会在data/kb/lucene下生成索引文件。
提供新知识库的实体链接词典和谓词复述词典,示例如下所示:

其中,“逆时针 逆时针_(张靓颖演唱歌曲) 2”是指短语“逆时针”可以链接到实体“逆时针_(张靓颖演唱歌曲)”,第三列数字2表示这个链接是在短语“逆时针”的所有链接中置信度处于第二高的;“地理位置 在哪里”表示短语“在哪里”可以匹配到谓词“地理位置”,数字“30”为该次匹配的置信度。mention2ent 和 pred2phrase 两个文件主要用来支撑实体链接和关系抽取两个子模块。将这两个词典文件置于data/kb/parapharse中。
以上操作完成后,gAnswer即可在新的知识库上提供问答服务。