
7.4 语义搜索的交互范式
理解用户的查询意图在于将用户的查询输入构建成结构化的查询语言 SPARQL,或者让用户直接提出结构化的查询,然而这种方式需要用户具备以下基本能力:熟悉知识图谱数据源,熟悉知识图谱的数据模式,了解知识图谱中数据大致包含哪些内容,熟练掌握结构化的查询语言。
然而,大部分的情形是普通用户往往不具备以上的能力,即使是知识图谱的专家或开发者,也很难完全熟悉每一个图谱的模式和内容。所以,知识图谱的有效语义搜索需要一种简单高效的搜索范式,即允许用户以直观的、透明的、易用的方式对数据进行查询和浏览[13] 。此类常见的交互范式主要包括:关键词查询、自然语言查询、分面查询、表单查询、可视化查询以及混合方式查询等[15] 。
目前,最先进的语义搜索系统会结合一系列技术,从基于统计的 IR 排序方法、有效索引和查询处理的数据库方法到推理的复杂推理技术。在设计相应的交互范式和语义搜索系统时,需要明白语义搜索的核心在于能够支持表现形式丰富的信息需求,即查询的表达能力至关重要。然而,用户需求的表示通常不完整,表现在用户事先并不能准确了解自己的信息需求,进而无法完全准确地描述查询输入。所以,需要设计一种直观且支持复杂信息需求表达的方式,以不精确的方式匹配需求和数据,并对结果进行排序,足够灵活以应对条件的变化。在此基础上,设计查询处理、结果展示以及查询优化等其他环节。
7.4.1 基于关键词的知识图谱语义搜索方法
近年来,各大商业搜索引擎的成功表明用户使用关键字进行搜索非常舒适,这是由于关键词能够直观地表达信息需求[16] 。基于关键词查询和自然语言自动问答形式的知识图谱语义搜索引起广泛关注。知识图谱上的关键词查询主要可以分为两类[17] :基于关键词直接在知识图谱上搜索答案;基于关键词生成结构化的查询,进而提交给查询引擎得到结果。
1.基于关键词直接在知识图谱上搜索答案
将关键词在知识图谱上直接进行搜索的方法,其核心思想是采用知识图谱子图定位的策略。基本流程是建立有效的关键词和知识图谱子图的索引,对于给定的关键字查询,首先在索引上匹配得到候选的知识图谱子图,进而实现对搜索空间的剪枝。最后,在小范围的知识图谱子图上进行搜索,找到最终的查询答案。该类方法的核心在于索引的构建,其构建方式直接决定搜索的效率和结果的质量。常见的索引方式有:
(1)关键词倒排索引。通过构建索引,快速定位知识图谱中包含关键词的实体。
(2)摘要索引。主要是构建一些包含结构化查询实体和关系类别的索引,在线上处理时根据类别摘要进行扩充。
(3)路径索引。主要借助关键词中包含的查询起始和终止结点,在图上按路径搜索提高查询效率。
基于关键词直接在知识图谱上搜索答案主要可以解决简单的语义搜索,即查询答案仅仅出现在单条知识图谱三元组中,对于复杂的语义查询往往无法适用。基于此需求,将关键词转化为结构化的查询方法应运而生。
2.基于关键词生成结构化的查询
将关键词集合转化为结构化的查询方法主要包括三个步骤:
(1)关键词映射。进行映射的主要原因是用户输入的关键词和知识图谱上的实体关系往往存在语义鸿沟,例如,关键词“妻子”在知识图谱可能对应的是“配偶”。所以,需要将关键词映射到知识图谱上实体、关系以及文本内容等。在此过程中,需要对知识图谱进行预处理,构建关键词和知识图谱实体和边的索引,进而在知识图谱上快速定位与关键词相关的实体和关系。
(2)候选结构化查询构建。映射关键词后,生成了对应的实体和关系。在知识图谱中,基于生成的实体和关系拓展,能够生成局部的知识图谱子图,就得到了结构化查询需要的查询图结构。在此基础上,根据查询意图,将局部子图中的部分实体和关系替换位变量,进而生成结构化的查询。
(3)候选结构化查询排序。在关键词映射过程中,一个关键词往往会映射到知识图谱中的多个实体或关系,进而发现多个局部子图,生成多个结构化的查询。因此,需要对生成的结构化查询集合进行排序。例如,可以基于关键词搜索相似度、实体的拓扑度分布等指标来计算排序评分。
值得一提的是,基于关键词的语义搜索还需要考虑对查询结果进行排序,让用户通过观察排序结果进而更新关键词。常见的TF/IDF等排序方法均可以采用,这里不再赘述。
7.4.2 基于分面的知识图谱语义搜索
分面(Facet)概念最早是由“印度图书馆学之父”S.R.Ranganathan 提出来的,用于表示图书文献的多维属性,并在此基础上提出了第一种图书分面分类法——冒号分类法(Colon Classification)。在该分面分类法中,每一个大类图书由五个基本的分面组成:主体、物质、动力、空间和时间。此后,很多文献进一步给出分面这一概念的特性和定义。典型的定义将分面描述为属性或一组分类体系(category),或将分面定义为某个主题的维度或侧面。基于分面的语义搜索已经在工业界取得了广泛应用,如图7-10所示的是 Ebay的商品分面搜索系统。
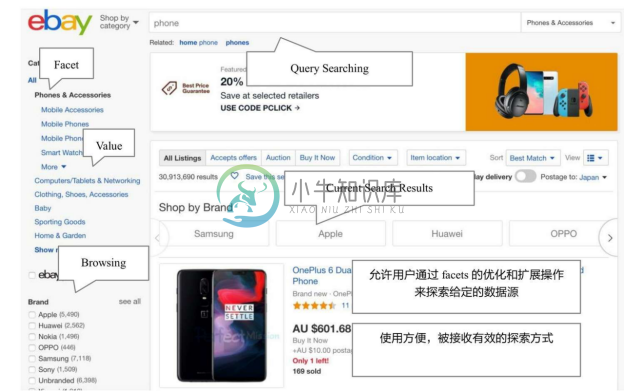
图7-10 Ebay的商品分面搜索系统
具体到知识图谱上的分面搜索,可以根据 RDF 三元组定义分面和值,即分面可以被看作一个在当前结果集中的RDF资源(实体)的属性,这些属性的 object 是分面的值[18,19] ,如图7-11所示。
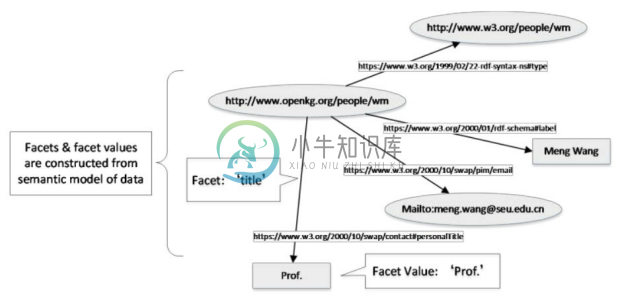
图7-11 知识图谱分面实例
图7-12展示了面向 RDF 数据分面搜索系统 Dataplorer[18] 的主要功能,可以看出构建知识图谱的分面搜索系统的主要环节包括:即时的计算生成分面、实时地计算分面的值以及根据用户的交互点击找到相关的分面。
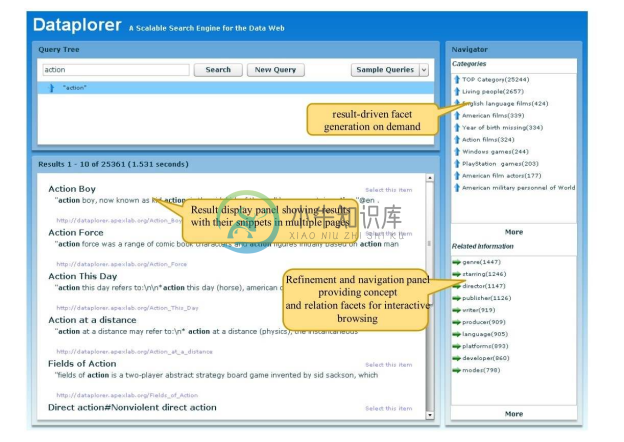
图7-12 知识图谱分面搜索系统Dataplorer
由于分面搜索的技术多种多样,本节不再详细展开。值得一提的是,一些高级的分面搜索系统还需要具备以下特征:
(1)考虑特定领域的分面、分面值和计数。分面能够根据它们的起点进行分组。
(2)支持全面的浏览。通过浏览可以达到每个分面的值,即没有值被跳过。
(3)支持动态分面和值的聚类。
此外,每一个当前浏览的知识图谱实体可能有大量分面,还需要对分面进行排序和分面隐藏。最终在整个分面搜索的过程中,分面应该以非常小的、相等的进度“引导”用户的,用户进而可以直观和明显地(用最少的必需知识)选择一类给定的分面。
7.4.3 基于表示学习的知识图谱语义搜索
近年来,知识图谱表示学习技术的出现,在知识图谱存储、构建、补全以及应用层面都产生了深远的影响。利用知识图谱表示学习技术来改善语义搜索的质量,也逐渐引起学术界和工业界的兴趣。知识图谱表示学习旨在通过机器学习技术,将知识图谱中的实体和关系投射到连续低维的向量空间中,同时保持原有知识图谱的基本结构和性质[20] 。在知识图谱表示学习技术出现之前,通常以图数据库的形式组织和存储知识图谱。然而,随着开放知识图谱数据规模越来越大,即使是中等规模的知识图谱也可能包含了数以千计的关系类型、数百万的实体和数亿的三元组。传统的基于图存储和图算法的知识图谱应用越来越受限于数据稀疏性和计算效率低下的问题[21] 。
通过知识图谱表示学习技术,将其投射到低维连续的向量空间中,对于语义搜索领域主要有两个好处。一是在连续向量空间中,可以直接进行数值型计算,对查询术语或者关键字进行扩展,效率极高。例如,衡量两个实体之间的相似度可以通过直接计算两个实体在向量空间中的欧式距离来实现。二是低维连续的知识图谱向量表示是通过机器学习技术学习得到的,其学习过程既考虑了知识图谱的局部特征,又考虑了全局特征,生成的实体和关系的向量在本质上是一种蕴涵语义更丰富的表示,可以进行高效率的简单查询推理。
下面从基于表示学习的结构化语义查询和基于表示学习的自然语言语义查询两个方面,介绍知识图谱表示学习技术可以带来哪些改进。
1.基于表示学习的结构化语义查询
表示学习在结构化语义查询的应用主要是可以有效、高速地进行近似语义搜索。如图7-13所示[22] ,初始的结构化查询可以看作是一个查询图,虽然查询图中的查询目标在数据层中不存在,但可以基于查询图,利用翻译机制等表示学习算子计算出其在向量空间中的坐标(如图7-13中点 A 所示),进而通过最近邻搜索找到近似结果(如图7-13中点 B所示),该近似结果很可能接近用户的初始查询意图。
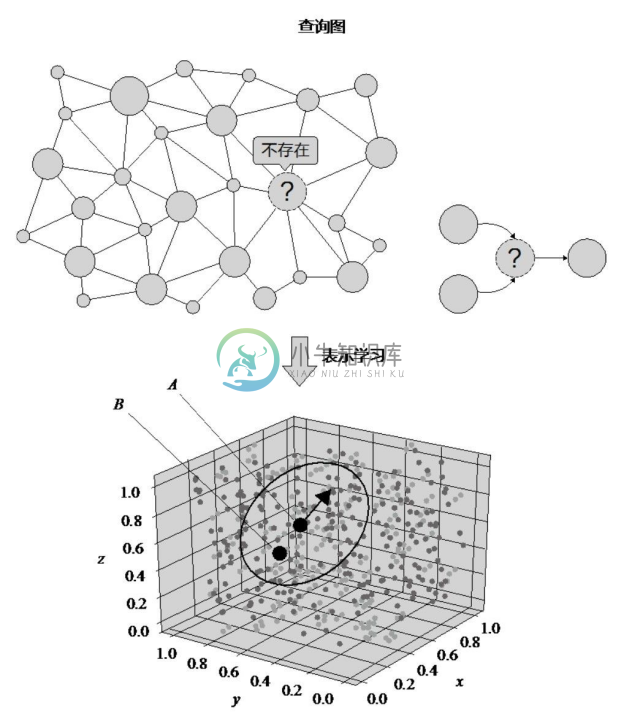
图7-13 基于表示学习的知识图谱结构化查询示意图
2.基于表示学习的自然语言语义查询
自然语言形式的语义查询的核心在于短语(phrase)到知识图谱上实体或边的映射,进而生成结构化的查询。在映射的过程中,主要难点在于关系(实体之间的边或实体属性)歧义的消除和查询图的构建。表示学习技术在这两个过程中都可以充分发挥作用。整个流程如图7-14中的例子所示[23] 。
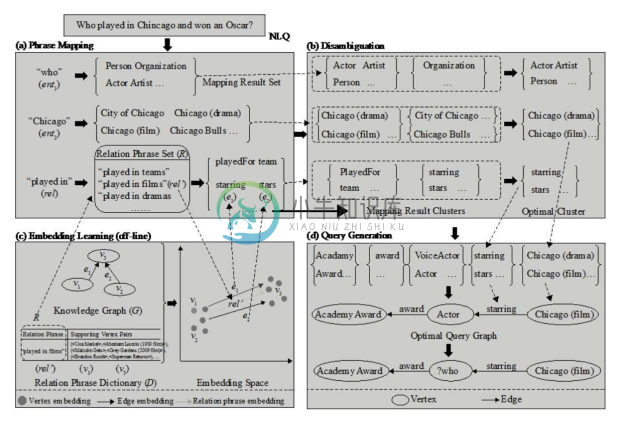
图7-14 基于表示学习的知识图谱自然语言语义查询示意图
首先,在离线阶段,生成知识图谱的实值向量,并且将关系短语词典和知识图谱中的关系在向量空间中对齐。在线上阶段,将首先通过关键字检索的方式发现知识图谱中和自然语言短语对应的候选实体和边的集合。传统的语义搜索方法将对候选的实体和边进行消歧,容易出错;并且,在消歧后进行实体和边的组合,计算最优查询图,进而提交给查询引擎,效率较低。知识图谱的向量空间可以帮助模型省略消歧的过程,方法是将每一个候选实体集合中的实体平均实值向量作为查询图生成时的实体表示,进而并不需要某一个具体的实体向量。在计算查询图时,也可以利用翻译机制等原理提前预估查询图的评分好坏,提高生成效率和质量。
以上两个案例在本质上是在传统语义搜索的数据和查询之间提供了全新的向量空间维度,进而利用实值向量计算的优势对查询进行改进。以近似查询来说,基于表示学习的搜索可以在不修改初始查询的前提下直接返回近似结果,极大地提高近似查询的质量,为知识图谱近似查询提供了全新的思路。值得一提的是,表示学习技术为知识图谱的语义搜索提供了新思路,但同时面临三项挑战,需要在实际使用中予以考虑:
(1)最近邻搜索效率问题。无论是近似查询,还是自然语言问答中的关系拓展和候选查询图构建,在向量空间中进行最近邻搜索存在维度灾难造成的效率问题。
(2)链接预测的合取问题。在向量空间中利用基于链接预测的思想,对语义搜索的目标进行预估,但是当搜索目标受多个实体和关系共同约束时,需要考虑不同链接预测的结果进行叠加时的合取问题。
(3)结果可解释性问题。表示学习技术可以让语义检索绕过对查询本身的修改拓展,直接得到近似结果,在提高效率和精度的同时又带来结果的可解释问题。