
代码封装自科大语音讯飞无UI版本,通过1行代码来实现语音识别 1行代码来实现文字识别,在封装的.h文件中有集成说明。
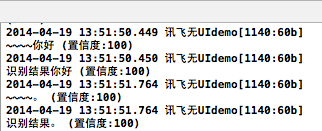
测试方式:点击“识别语音”,然后对着说话,在Xcode的debug输出窗口可以看到识别的结果。见下面右图。 [Code4App.com]

-
语音识别技术原理简介 自动语音识别技术(Auto Speech Recognize,简称ASR)所要解决的问题是让计算机能够“听懂”人类的语音,将语音中包含的文字信息“提取”出来。ASR技术在“能听会说”的智能计算机系统中扮演着重要角色,相当于给计算机系统安装上“耳朵”,使其具备“能听”的功能,进而实现信息时代利用“语音”这一最自然、最便捷的手段进行人机通信和交互。 语音识别技术所面临的问题是非常
-
1.Msc.jar,Sunflower.jar 2.VoiceActivity import android.os.Bundle; import android.os.Environment; import android.util.Log; import android.widget.EditText; import android.widget.Toast; import com.co_i
-
官方文档:https://www.xfyun.cn/doc/asr/voicedictation/API.html#%E6%8E%A5%E5%8F%A3%E8%B0%83%E7%94%A8%E6%B5%81%E7%A8%8B 讯飞WebAPI语音听写流式接口,用于1分钟内的即时语音转文字技术,支持实时返回识别结果,达到一边上传音频一边获得识别文本的效果。开启动态修正的好处是能提高
-
下载地址:https://download.csdn.net/download/qq_39735878/12447473 unity写的讯飞语音识别合成与评测功能,走的是webapi,连接讯飞WebSocket服务器没有接入任何sdk,也没有多余插件,开发工具unity2019.3.6 ,真正实现了跨平台,不用在每个平台重新接入sdk这么麻烦 最近项目要实现语音识别合成与评测功能,看到了讯飞正好符
-
importjava.io.UnsupportedEncodingException;importandroid.app.Activity;importandroid.os.Bundle;importandroid.os.Environment;importandroid.text.TextUtils;importandroid.util.Log;importandroid.view.Menu;i
-
参考大佬的教程,升级了一下插件版本 大佬:https://blog.csdn.net/zhangmei126/article/details/101437452
-
最近项目要实现语音识别合成与评测功能,看到了讯飞正好符合要求就打算介入讯飞sdk来实现,但是讯飞的sdk没有unity插件只有单个平台的sdk,看了开发文档之后发现可以用webapi实现跨平台这个可以再不同平台实现语音识别功能。讯飞语音合成与识别用的是WebSocket网络协议先要构建接口鉴权。在握手阶段,请求方需要对请求进行签名,服务端通过签名来校验请求的合法性。代码如下: string
-
本文向大家介绍Android基于讯飞语音SDK实现语音识别,包括了Android基于讯飞语音SDK实现语音识别的使用技巧和注意事项,需要的朋友参考一下 一、准备工作 1、你需要android手机应用开发基础 2、科大讯飞语音识别SDK android版 3、科大讯飞语音识别开发API文档 4、android手机 关于科大讯飞SDK及API文档,请到科大语音官网下载:http://www.xfyun
-
【笔试】 1.两兄弟拿奖品最大可能数 2.参观展厅总时间120分钟 3.手写kmeans聚类 【一面 40min】 1、自我介绍 2、问简历 3、介绍2个简历项目 4、训练的数据量级,过拟合的解决方法 5、遇到的困难,怎么解决 6、调过参吗?网络是自创还是开源?调参经历和结果 7、为什么使用自监督学习?有什么优势? 8、你的方法跟别人的方法相比的优势在哪?尝试过别人的方法吗?对比结果是什么 9、工
-
我正在为嵌入式设备的语音相关语音识别解决方案寻找解决方案。我已经研究过Pocketsphinx,但由于我仍然不熟悉它,我想也许更有经验的人可能会知道。是否有可能使用Pocketsphinx来实现这样的语音识别。它应该记录音频,提取其特征,然后将其与所说的任何内容进行匹配,而不是使用声学和语言模型。是否有可能使用Pocketsphinx实现此流程?如果没有,有人能为这样的解决方案指出正确的方向吗?谢
-
由于连接到不同的API,我目前正在开发一个工具,允许我阅读所有的通知。 它工作得很好,但现在我想用一些声音命令来做一些动作。 就像当软件说“一封来自Bob的邮件”时,我想说“阅读”或“存档”。 我的软件是通过一个节点服务器运行的,目前我没有任何浏览器实现,但它可以是一个计划。 在NodeJS中,启用语音到文本的最佳方式是什么? 我在它上面看到了很多线程,但主要是使用浏览器,如果可能的话,我希望在一
-
语音识别是以语音为研究对象,通过语音信号处理和模式识别让机器自动识别和理解人类口述的语言。语音识别技术就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。语音识别是一门涉及面很广的交叉学科,它与声学、语音学、语言学、信息理论、模式识别理论以及神经生物学等学科都有非常密切的关系。语音识别技术正逐步成为计算机信息处理技术中的关键技术,语音技术的应用已经成为一个具有竞争性的新兴高技术产
-
识别简单的语句。