知情搜索算法
在前面章节中,我们已经讨论了不知情搜索算法,该搜索算法通过搜索空间查找问题的所有可能解决方案,而无需任何关于搜索空间的额外知识。但是,知情搜索(Informed Search)算法包含一系列知识,例如我们离目标有多远,路径成本,如何到达目标节点等。这些知识有助于代理人更少地探索搜索空间并更有效地找到目标节点。
知情搜索算法对于大型搜索空间更有用。知情搜索算法使用启发式思想,因此也称为启发式搜索。
启发式函数:启发式是一种在Informed Search中使用的函数,它找到了最有希望的路径。它将代理的当前状态作为其输入,并生成估计代理与目标的接近程度。然而,启发式方法可能并不总是提供最佳解决方案,但它保证在合理的时间内找到一个好的解决方案。启发式函数估计状态与目标的接近程度。它由h(n)表示,它计算这对状态之间的最佳路径的成本。启发式函数的值始终为正值。
启发函数的可接受性如下:
h(n) <= h*(n)
这里h(n)是启发式成本,h *(n)是估计成本。因此,启发式成本应小于或等于估计成本。
纯启发式搜索
纯启发式搜索是最简单的启发式搜索算法。它根据启发式值h(n)扩展节点。它维护两个列表,OPEN和CLOSED列表。在CLOSED列表中,它放置那些已经扩展的节点,并在OPEN列表中放置尚未展开的节点。
在每次迭代中,具有最低启发式值的每个节点n被扩展并生成其所有后继者,并且n被放置到闭合列表中。该算法继续单元找到目标状态。
在知情搜索中,我们将讨论以下两种主要算法:
- 最佳搜索算法(贪婪搜索)
A *搜索算法
1. 最佳搜索算法(贪婪搜索)
贪心最佳优先搜索算法总是选择当时最佳的路径。它是深度优先搜索和广度优先搜索算法的组合。它使用启发式功能和搜索。最佳优先搜索允许我们利用这两种算法的优势。借助最佳优先搜索,在每一步,我们都可以选择最有前途的节点。在最好的第一搜索算法中,我们扩展最接近目标节点的节点,并且通过启发函数估计最接近的成本,即 -
f(n)= g(n)
是,h(n)= 从节点n到目标的估计成本。
贪婪最佳优先算法由优先级队列实现。
最佳优先搜索算法:
- 步骤1:将起始节点放入OPEN列表。
- 步骤2:如果OPEN列表为空,则停止并返回失败。
- 步骤3:从具有最低值h(n)的OPEN列表中删除节点n,并将其放在CLOSED列表中。
- 步骤4:展开节点n,并生成节点n的后继节点。
- 步骤5:检查节点n的每个后继节点,并查找是否有任何节点是目标节点。如果任何后继节点是目标节点,则返回成功并终止搜索,否则继续执行步骤6。
- 步骤6:对于每个后继节点,算法检查评估函数f(n),然后检查节点是否已处于OPEN或CLOSED列表中。如果节点未在两个列表中,则将其添加到OPEN列表中。
- 步骤7:返回步骤2。
优点:
- 最佳优先搜索可以通过获得两种算法的优势在BFS和DFS之间切换。
- 该算法比BFS和DFS算法更有效。
缺点:
- 在最坏的情况下,它可以表现为无指导的深度优先搜索。
- 它可以像DFS一样陷入循环。
- 该算法不是最优的。
示例:
考虑下面的搜索问题,我们将使用贪婪的最佳优先搜索来遍历它。在每次迭代时,使用评估函数f(n)= h(n)扩展每个节点,该函数在下表中给出。

在此搜索示例中,我们使用两个列表,即OPEN和CLOSED列表。以下是遍历上述示例的迭代。

展开S的节点并放入CLOSED列表
初始:
Open [A, B], Closed [S]
迭代 1:
Open [A], Closed [S, B]
迭代 2:
Open [E, F, A], Closed [S, B]
: Open [E, A], Closed [S, B, F]
迭代 3:
Open [I, G, E, A], Closed [S, B, F]
: Open [I, E, A], Closed [S, B, F, G]
因此最终的解决方案路径为:S ——> B ——-> F ——> G.
时间复杂性:最佳优先搜索的最坏情况时间复杂度是O(bm)。
空间复杂性:最佳优先搜索的最坏情况空间复杂度是O(bm)。其中,m是搜索空间的最大深度。
完成:即使给定的状态空间是有限的,贪婪最佳优先搜索也是不完整的。
最优:贪心最佳优先搜索算法不是最优的。
2. A *搜索算法:
A *搜索是最常见的最佳优先搜索形式。它使用启发函数h(n),并且从开始状态g(n)到达节点n的成本。它结合了UCS和贪婪的最佳优先搜索功能,可以有效地解决问题。A *搜索算法使用启发式函数找到通过搜索空间的最短路径。此搜索算法扩展了较少的搜索树并更快地提供最佳结果。A *算法类似于UCS,除了它使用g(n)+ h(n)而不是g(n)。
在A *搜索算法中,我们使用搜索启发式以及到达节点的成本。因此可以将两种成本结合起来,并将此总和称为适合度数。
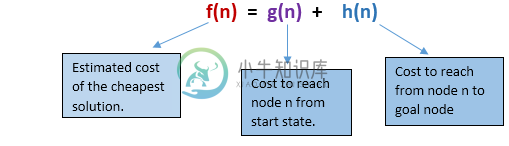
在搜索空间中的每个点处,仅扩展具有最小值f(n)的那些节点,并且算法在找到目标节点时终止。
A *搜索算法过程
- 步骤1:将起始节点放在OPEN列表中。
- 步骤2:检查OPEN列表是否为空,如果列表为空则返回失败并停止。
- 步骤3:从OPEN列表中选择具有最小评估函数值
(g + h)的节点,如果节点n是目标节点则返回成功并停止,否则继续。 - 步骤4:展开节点n并生成其所有后继节点,并将n放入关闭列表中。对于每个后来者n’,检查n’是否已经在OPEN或CLOSED列表中,如果没有,则检查n’的评估函数并放入打开列表。
- 步骤5:否则如果节点n’已经处于OPEN和CLOSED状态,那么它应该连接到反向最低g(n’)值的后向指针。
- 步骤6:返回步骤2。
优点:
- A * 搜索算法是比其他搜索算法更好的算法。
- A * 搜索算法是最佳和完整的。
- 该算法可以解决非常复杂的问题。
缺点:
- 它并不总是产生最短路径,因为它主要基于启发式和近似。
- A * 搜索算法存在一些复杂性问题。
- A * 主要缺点是内存需求,因为它将所有生成的节点保存在内存中,因此对于各种大规模问题是不实际的。
示例:
在这个例子中,我们将使用A * 算法遍历给定的图形。所有状态的启发式值在下表中给出,因此将使用公式f(n)= g(n)+ h(n)计算每个状态的f(n),其中g(n)是成本 从开始状态到达任何节点。
下面是将使用OPEN和CLOSED列表。
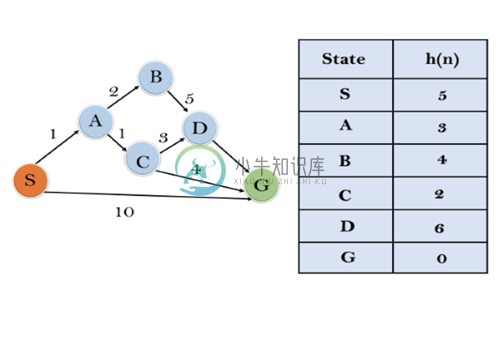
解决方案

初始化: {(S, 5)}
迭代1: {(S—> A, 4), (S—>G, 10)}
迭代2: {(S—> A—>C, 4), (S—> A—>B, 7), (S—>G, 10)}
迭代3: {(S—> A—>C—->G, 6), (S—> A—>C—->D, 11), (S—> A—>B, 7), (S—>G, 10)}
迭代4将给出最终结果,如: S—->A—->C—->G 它提供了成本6的最佳路径。
要记住的要点:
- A * 算法返回首先发生的路径,并且不搜索所有剩余路径。
- A * 算法的效率取决于启发式的质量。
- A * 算法扩展满足条件f(n)的所有节点
完成:
A * 算法完成,只要:
- 分支因子是有限的。
- 每项行动的成本都是固定的。
最佳:
如果遵循以下两个条件,A *搜索算法是最佳的:
- 可接受:第一个要求最优的条件是h(n)应该是A * 树搜索的可接受的启发式算法。可接受的启发式算法本质上是乐观的。
- 一致性:第二个必需条件是仅A * 图搜索的一致性。
如果启发式函数是可接受的,则A * 树搜索将始终找到最低成本路径。
时间复杂度:A * 搜索算法的时间复杂度取决于启发式函数,并且扩展的节点数量是指数d的深度的指数。因此,时间复杂度为O(b ^ d),其中b是分支因子。
空间复杂度:A *搜索算法的空间复杂度为O(b ^ d)