
3.1 知识图谱数据库基本知识
本节首先介绍目前表示知识图谱的两种主要图数据模型:RDF图和属性图。
3.1.1 知识图谱数据模型
从数据模型角度来看,知识图谱本质上是一种图数据。不同领域的知识图谱均须遵循相应的数据模型。往往一个数据模型的生命力要看其数学基础的强弱,关系模型长盛不衰的一个重要原因是其数学基础为关系代数。知识图谱数据模型的数学基础源于有着近300年历史的数学分支——图论。在图论中,图是二元组G=(V,E),其中V是节点集合,E是边集合。知识图谱数据模型基于图论中图的定义,用节点集合表示实体,用边集合表示实体间的联系,这种一般和通用的数据表示恰好能够自然地刻画现实世界中事物的广泛联系。
1.RDF图
RDF 是 W3C 制定的在语义万维网上表示和交换机器可理解信息的标准数据模型[1] 。在 RDF 三元组集合中,每个 Web 资源具有一个 HTTP URI 作为其唯一的 id;一个 RDF图定义为三元组(s, p, o)的有限集合;每个三元组代表一个陈述句,其中s是主语,p是谓语,o是宾语;(s, p, o)表示资源s与资源o之间具有联系p,或表示资源s具有属性p且其取值为o。实际上,RDF三元组集合即为图中的有向边集合。
如图3-1所示,是一个虚构的软件开发公司的社会网络图,其中有张三、李四、王五和赵六4名程序员,有“图数据库”和“RDF 三元组库”2个项目;张三认识李四和王五;张三、王五和赵六参加“图数据库”的开发,该项目使用 Java 语言;王五参加“RDF三元组库”的开发,该项目使用C++语言。
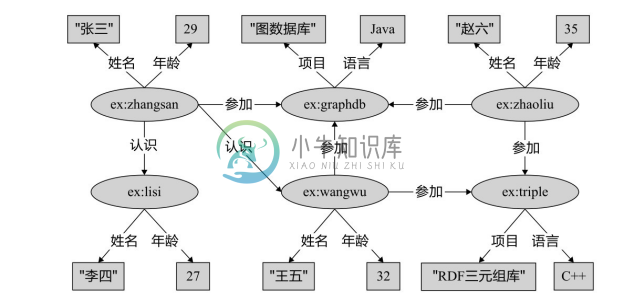
图3-1 RDF图示例
值得注意的是,RDF 图对于节点和边上的属性没有内置的支持。节点属性可用三元组表示,这类三元组的宾语称为字面量,即图中的矩形。边上的属性表示起来稍显烦琐,最常见的是利用 RDF 中一种叫作“具体化”(reification)的技术[2] ,需要引入额外的点表示整个三元组,将边属性表示为以该节点为主语的三元组。例如在图3-2中,引入节点ex:participate 代表三元组(ex:zhangsan, 参加, ex:graphdb),该节点通过 RDF 内置属性rdf:subject、rdf:predicate 和 rdf:object 分别与代表的三元组的主语、谓语和宾语建立起联系,这样三元组(ex:participate, 权重, 0.4)就实现了为原三元组增加边属性的效果。
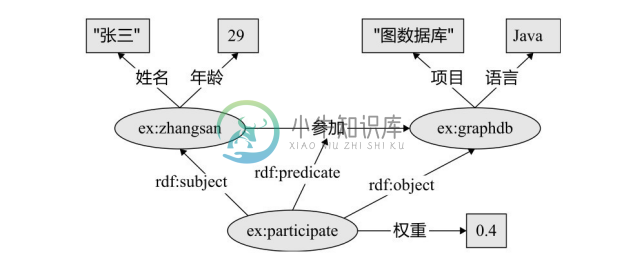
图3-2 RDF图中边属性的表示
2.属性图
属性图可以说是目前被图数据库业界采纳最广的一种图数据模型[3] 。属性图由节点集和边集组成,且满足如下性质:
(1)每个节点具有唯一的id;
(2)每个节点具有若干条出边;
(3)每个节点具有若干条入边;
(4)每个节点具有一组属性,每个属性是一个键值对;
(5)每条边具有唯一的id;
(6)每条边具有一个头节点;
(7)每条边具有一个尾节点;
(8)每条边具有一个标签,表示联系;
(9)每条边具有一组属性,每个属性是一个键值对。
图3-3给出的属性图不仅表达了RDF图的全部数据,而且还增加了边上的“权重”属性。
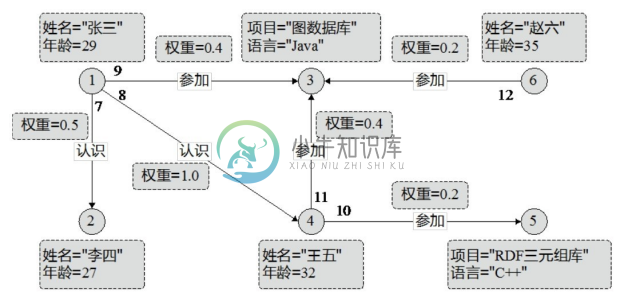
图3-3 属性图示例
图3-3的每个节点和每条边均有id。遵照属性图的要素,节点4的出边集合为{边10,边11},入边集合为{边8},属性集合为{姓名="王五", 年龄=32};边11的头节点是节点3,尾节点是节点4,标签是“参加”,属性集合为{权重=0.4}。
3.1.2 知识图谱查询语言
在知识图谱数据模型上,需要借助知识图谱查询语言进行查询操作。目前,RDF 图上的查询语言是SPARQL;属性图上的查询语言常用的是Cypher和Gremlin。
1.SPARQL
SPARQL 是 W3C 制定的 RDF 图数据的标准查询语言[4] 。SPARQL 从语法上借鉴了SQL,同样属于声明式查询语言。最新的SPARQL 1.1版本为有效查询RDF图专门设计了三元组模式、子图模式、属性路径等多种查询机制。几乎全部的 RDF 三元组数据库都实现了 SPARQL 语言。下面通过几个例子介绍 SPARQL 语言的基本功能。查询使用的是RDF图数据。
(1)查询程序员张三认识的其他程序员

输出:
![]()
说明:PREFIX 关键字将 ex 定义为 URI“http://www.example.com/”的前缀缩写, WHERE关键字指明了查询的三元组模式(Triple Pattern),SELECT关键字列出了要返回的结果变量。三元组模式查询是最基本的SPARQL查询。
(2)查询程序员张三认识的其他程序员参加的项目

输出:
![]()
说明:这是由两个三元组模式组成的一个基本图模式(Basic Graph Pattern)查询,简称为BGP查询。实际上,这两个三元组模式之间通过公共变量?p连接为一个链式查询。
(3)查询节点ex:zhangsan认识的30岁以上的程序员参加的项目名称
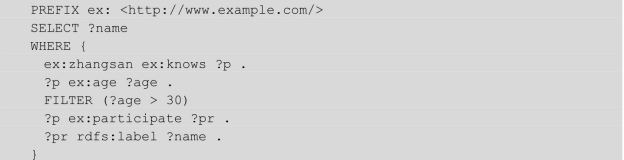
输出:
![]()
说明:关键字 FILTER 用于指明过滤条件,对变量匹配结果进行按条件筛选。这里既有?p和?pr分别作为两个三元组模式的宾语和主语连接起来的链式模式,也有?p作为两个三元组模式的主语连接起来的星形结构,该查询是一个更加一般的 BGP 查询。实际上, BGP 查询相当于一个带有变量的查询图,查询过程是在数据图中寻找与查询图映射匹配的所有子图,等价于图论中的子图同构(Subgraph Isomorphism)或子图同态(Subgraph Homomorphism)问题[5] ,所以也将BGP查询称为子图匹配查询。
(4)查询年龄为29的参加了项目 ex:graphdb 的程序员参加的其他项目及其直接或间接认识的程序员参加的项目
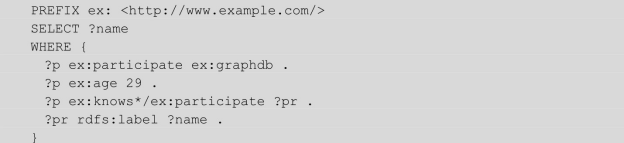
输出:
![]()
说明:这里使用了 SPARQL 1.1引入的属性路径(Property Path)机制, ex:knows*/ex:participate 类似于正则表达式,其表示经过0条、1条或多条 ex:knows 边,再经过一条ex:participate边。
SPARQL 实际上是一整套知识服务标准体系。SPARQL 1.1语言的语法和语义的完整定义请参见 W3C 的推荐标准“SPARQL 1.1查询语言”[4] ,该标准连同其他10个推荐标准共同组成了 SPARQL 知识平台,包括查询[4] 、更新[6] 、服务描述[7] 、联邦查询[8] 、查询结果格式[9] 、蕴涵推理[10] 和接口协议[11] 等。开放的 SPARQL 学习教程有 WikiBooks SPARQL教程[12] 、Wikidata SPARQL教程[13] 和Apache Jena SPARQL教程[14] 等。本章3.4节将以Apache Jena作为实践工具,讲解如何使用SPARQL进行知识图谱的查询和更新。
2.Cypher
Cypher 最初是图数据库 Neo4j 中实现的属性图数据查询语言[15] 。与 SPARQL 一样, Cypher 也是一种声明式语言,即用户只需要声明“查什么”,而无须关心“怎么查”,这就好比乘坐出租车到一个目的地,只需要告诉司机要到哪里,具体的行车路线可由司机安排,乘客并不需要关心。这类语言的优点是便于用户学习掌握,同时给予数据库进行查询优化的空间,缺点是不能满足高级用户导航式查询的要求,数据库规划的查询执行计划有可能并不是最优方案。2015年,Neo4j 公司发起开源项目 openCypher[16] ,旨在对 Cypher进行标准化工作,为其他实现者提供语法和语义的参考标准。虽然 Cypher 的发展目前仍由 Neo4j 主导,但包括 SAP HANA Graph[17] 、Redis Graph[18] 、AgensGraph[19] 和Memgraph[20] 等在内的图数据库产品已经实现了Cypher。下面通过例子了解Cypher语言的基本功能。使用的知识图谱是图3-3中的属性图。
(1)查询图中的所有程序员节点
![]()
输出:

说明:MATCH 关键字指明需要匹配的模式,这里将节点分为了程序员和项目两类, p 作为查询变量会依次绑定到每个类型为 Programmer 的节点,RETURN 关键字返回变量p的值作为查询结果。
(2)查询程序员与“图数据库”项目之间的边
![]()
输出:

说明:此查询返回边及其属性,程序员类型节点与图数据库项目节点之前存在3条标签为参加的边。
(3)查询从节点1出发的标签为“认识”的边
![]()
输出:
![]()
说明:从节点1出发沿“认识”边到达节点2和节点4。
(4)查询节点1认识的30岁以上的程序员参加的项目名称

输出:
![]()
说明:该查询MATCH子句等价于SPARQL BGP查询的链式查询。
(5)查询年龄为29的参加了项目3的程序员参加的其他项目及其直接或间接认识的程序员参加的项目

输出:
![]()
说明:“:认识*0..”表示由一个节点到达另一个节点的路径包括0个、1个或多个“认识”边。对比该查询的SPARQL版本。
3.Gremlin
Gremlin 是 Apache TinkerPop 图计算框架[21] 提供的属性图查询语言[22] 。Apache TinkerPop 被设计为访问图数据库的通用 API 接口,其作用类似于关系数据库上的 JDBC接口。Gremlin 的定位是图遍历语言,其执行机制好比是一个人置身于图中沿着有向边,从一个节点到另一个节点进行导航式的游走。这种执行方式决定了用户使用 Gremlin 需要指明具体的导航步骤,这和自己驾驶汽车到一个目的地需要知道行车路线是一个道理,所以将 Gremlin 归为过程式语言,即需要明确“怎么做”。这类语言的优点是可以时刻知道自己在图中所处的位置,以及是如何到达该位置的;缺点是用户需要“认识路”!与受到SQL 影响的声明式语言 SPARQL 和 Cypher 不同,Gremlin 更像一种函数式的编程语言接口。下面通过几个例子认识Gremlin语言,假设用g代表图3-3中的属性图。
(1)列出图中所有节点的属性
![]()
输出:

说明:V表示节点集合。
(2)列出图中所有的边
![]()
输出:

说明:E表示边集合。
(3)查询从节点1出发的标签为“认识”的边
![]()
输出:
![]()
说明:v(1)选取id为1的节点;outE表示节点的出边集合,outE(’认识’)是标签为“认识”的出边集合。
(4)查询节点1认识的30岁以上的程序员参加的项目名称
![]()
输出:
![]()
说明:out(’认识’)选取标签为“认识”的出边指向的邻接节点集合;filter 为过滤器, filter{it.年龄 > 30}的意思是后面只处理年龄大于30的节点。
(5)查询年龄为29的参加了项目3的程序员参加的其他项目及其直接或间接认识的程序员参加的项目
![]()
输出:
![]()
说明:in(’参加’)选取标签为“参加”的入边连接的邻接节点集合;has(’年龄’, 29)的作用是只选取具有属性“年龄=29”的节点;as('x')将当前的导航步骤命名为 x;loop('x'){it.loops >= 0}为从 x 开始到当前的步骤循环0次、1次或多次。对比该查询的SPARQL和Cypher版本。