
5.5 开源工具实践:实体关系发现框架LIMES
5.5.1 简介
LIMES是由德国莱比锡大学计算机科学研究所开发的Web of Data的链接发现框架,遵循cc-by协议。LIMES基于度量空间的特征实现了用于大规模链接发现的高效方法,可以通过配置文件以及图形用户界面轻松配置,LIMES 也可以作为独立工具下载,用于执行链接发现或作为 Java 库。本实践的相关工具、实验数据及操作说明由 OpenKG 提供,地址为http://openkg.cn。
5.5.2 开源工具的技术架构
LIMES 的核心是通过利用度量空间的三角不等式特征来过滤掉大量不满足映射条件的实例对,从而减少比较次数,使链接发现更加高效。对空间 A 上任意三个点x,y,z和度量空间m,有如下三角不等式:
m(x,z)≤m(x,y)+m(y,z)
将上式中的y称为样本点examplar。由上式易得:
m(x,y)−m(y,z)>θ⇒m(x,z)> θ
上式意味着如果空间A中的x,y 和样本点y之间的距离差大于阈值,意味着x,z之间的距离比阈值大,说明二者相似度低,在计算距离的过程中便不需要计算x,z之间的距离。具体的 examplar 计算参考原论文,地址为 http://svn.aksw.org/papers/2011/ WWW_LIMES/public.pdf。
1.框架构成
整体的框架如图5-19所示。
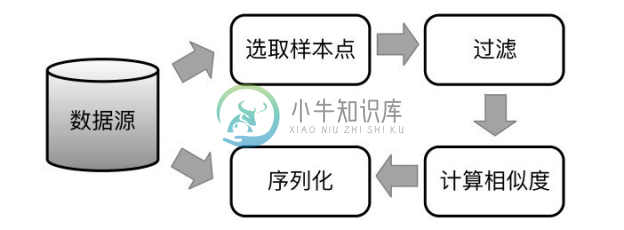
图5-19 整体的框架
框架主要由4部分构成:
(1)选取样本点。为目标数据集T计算样本点集合E,过程中可得m(e,t)。
(2)过滤。计算源数据集 S 中的点和样本点集合 E 中点的距离,得到m(s,e),过滤掉m(s,e)−m(e,t)>θ 的实体对(s,t) 。
(3)计算相似度。计算剩余实体对(s,t)的距离m(s,t)。因为步骤(2)会过滤掉大量的数据,因此本步骤的比较次数会显著减小。
(4)序列化。以用户定义的格式存储步骤(3)得到的结果(s,t,m(s,t))。
2.编写配置文件
使用 LIMES 工具进行实体关系融合的关键步骤是配置文件的编写,包括数据源、融合算法、融合条件等信息。具体来说:
(1)数据源
1)通过<Source>和<Target>标签指定数据源。
2)数据源可以是SPARQL端点,也可以是本地文件(需要绝对路径)。
3)标签内可以通过<VAR>指定参与实体相似度计算的变量,通过<PAGESIZE>指定SPARQL端点每次查询返回的最大Triple数量以及其他的一些限制和预处理操作。
(2)融合算法。可以通过度量表达式或机器学习算法计算相似度。
1)通过<METRIC>标签指定度量表达式来计算相似度。多个 Mertic Expression 可以使用MIN、MAX、ADD操作符结合使用,目前所有操作符只支持两个Expression结合,但可以嵌套使用。
2)目前,METRIC 支持的原子表达式有:Cosine、ExactMatch、Jaccard、Jaro、JaroWinkler、Levenshtein、MongeElkan、Overlap、Qgrams、RatcliffObershelp、Soundex、Trigram。
3)通过<MLALGORITHM>指定机器学习算法自行计算相似度。
●通过<NAME>指定选用的算法,支持womabt simple、wombat complete、eagle。
●通过<PARAMETER>制定训练参数。
(3)融合条件。包括接受条件和复审条件。
1)通过<ACCEPTANCE>指定接受条件,通过<REVIEW>指定复审条件。
2)两个标签中都需要通过<THRESHOLD>、<FILE>和<RELATION>指定阈值,输出文件路径和实体关系名称。
3)复审条件与接受条件类似,一般阈值比前者小。对于某些不满足接受的实体对,可根据复审条件输出到另一个文件进行复审。
访问OpenKG可获取使用实例和整体配置细节。
5.5.3 其他类似工具
Dedupe 基于主动学习的方法,只需用户标注框架在计算过程选择的少量数据,即可有效地训练出复合的 Blocking 方法和 record 间相似性的计算方法,并通过聚类完成匹配。Dedupe支持多种灵活的数据类型和自定义类型。
SILK 关联发现框架的核心是关联发现引擎,其从数据源中获取数据,并对其进行Blocking 处理,进行比较和发现关联,最后过滤结果并进行输出。用 SILK-LSL 语言写成的关联规则描述文件是关联发现引擎工作的依据,它定义了发现数据间关系的规则,供关联发现引擎读取。