
3.3 知识存储关键技术
为了适应大规模知识图谱数据的存储管理与查询处理,知识图谱数据库内部针对图数据模型设计了专门的存储方案和查询处理机制。本节首先以图数据库Neo4j为例介绍其内部存储方案,然后简要描述知识图谱数据库的两类索引技术。
3.3.1 知识图谱数据库的存储:以Neo4j为例
这一节将深入Neo4j图数据库底层,探究其原生的图存储方案。对于遵循属性图的图数据库,存储管理层的任务是将属性图编码表示为在磁盘上存储的数据格式。虽然不同图数据库的具体存储方案各有差异,但一般认为具有“无索引邻接”特性(Index-Free Adjacency)的图数据库才称为原生图数据库[35] 。
在实现了“无索引邻接”的图数据库中,每个节点维护着指向其邻接节点的直接引用,这相当于每个节点都可看作是其邻接节点的一个“局部索引”,用其查找邻接节点比使用“全局索引”更能节省时间。这就意味着图导航操作代价与图大小无关,仅与图的遍历范围成正比。
作为对比,来看看在非原生图数据库中使用全局索引关联邻接节点的情形。图3-36给出了一个全局索引的示例,一般用 B+树实现,如查找“张三”认识的人,需要 O(logn)的代价,其中n为节点总数。如果觉得这样的查找代价还是可以接受的话,那么换一个问题,“谁认识张三”的查找代价是多少?显然,对于这个查询,需要通过全局索引检查每个节点,看其认识的人中有没有张三,总代价为 O(nlogn),这样的复杂度对于大图数据的遍历操作是不可接受的。有人说,可为“被认识”关系再建一个同样的全局索引,但那样索引的维护开销就会翻倍,而且仍然不能做到图遍历操作代价与图规模无关。
只有将图数据的边表示的关系当作数据库的“一等公民”(即数据库中最基本、最核心的概念,如关系数据库中的“关系”),才能实现真正的“无索引邻接”特性。图3-37给出的是将“认识”关系作为双向可导航边进行存储的逻辑图,在其中查找“张三”认识的人,只需沿着张三的“认识”出边导航;查找认识“张三”的人,只需沿着张三的“认识”入边导航;显然,这两种操作的代价均为O(1),即与图数据的规模无关。
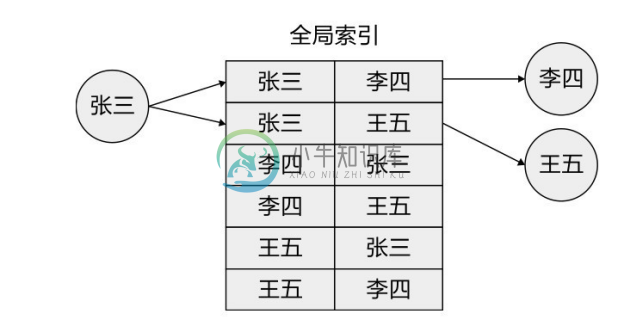
图3-36 邻接关系的全局索引示例
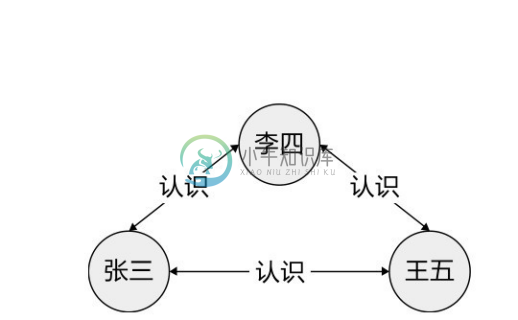
图3-37 将关系作为“一等公民”
在 Neo4j数据库中,属性图的不同部分是被分开存储在不同文件中的。正是这种将图结构与图上属性分开存储的策略,使得 Neo4j 具有高效率的图遍历操作。首先,来看在Neo4j 中是如何存储图节点和边的。图3-38给出了 Neo4j 中节点和边记录的物理存储结构,其中每个节点记录占用9字节,每个边记录占用33字节。
节点记录存储在文件neostore.nodestore.db中。节点记录的第0字节inUse是记录使用标志字节的,告诉数据库该记录是否在使用中,还是已经删除并可回收用来装载新的记录;第1~4字节nextRelId是与节点相连的第1条边的id;第5~8字节nextPropId是节点的第1个属性的id。
边记录存储在文件neostore.relationshipstore.db中。边记录第0字节inUse含义与节点记录相同,表示是否正被数据库使用的标志;第1~4字节 firstNode 和第5~8字节secondNode分别是该边的起始节点id和终止节点id;第9~12字节relType是指向该边的关系类型的指针;第13~16字节firstPrevRelId和第17~20字节firstNextRelId分别为指向起始节点上前一个和后一个边记录的指针;第21~24字节 secPrevRelId 和第25~28字节secNextRelId 分别为指向终止节点上前一个和后一个边记录的指针;指向前后边记录的4个指针形成了两个“关系双向链”;第29~32字节nextPropId是边上的第1个属性的id。
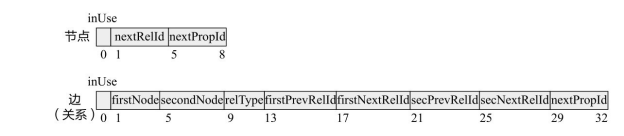
图3-38 Neo4j中节点和边记录的物理存储结构
Neo4j 实现节点和边快速定位的关键是“定长记录”的存储方案,将具有定长记录的图结构与具有变长记录的属性数据分开存储。例如,一个节点记录长度是9字节,如果要查找id为99的节点记录所在位置(id从0开始),则可直接到节点存储文件第891个字节处访问(存储文件从第0个字节开始)。边记录也是“定长记录”,长度为33字节。这样,数据库已知记录 id 可以 O(1)的代价直接计算其存储地址,而避免了全局索引中O(nlogn)的查找代价。
图3-39展示了Neo4j中各种存储文件之间是如何交互的。存储在节点文件中的节点1和节点4均有指针指向存储在属性文件中各自的第1个属性记录;也有指针指向存储在边文件中各自的第1条边,分别为边7和边8。如要查找节点属性,可由节点找到其第1个属性记录,再沿着属性记录的单向链表进行查找;如要查找一个节点上的边,可由节点找到其第1条边,再沿着边记录的双向链表进行查找;当找到了所需的边记录后,可由该边进一步找到边上的属性;还可由边记录出发访问该边连接的两个节点记录(图3-39中的虚线箭头)。需要注意的是,每个边记录实际上维护着两个双向链表,一个是起始节点上的边,一个是终止节点上的边,可以将边记录想象为被起始节点和终止节点共同拥有,双向链表的优势在于不仅可在查找节点上的边时进行双向扫描,而且支持在两个节点间高效率地添加和删除边。
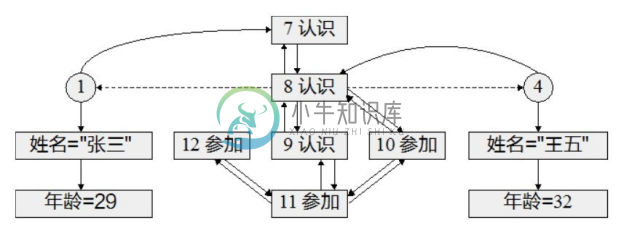
图3-39 Neo4j中图的物理存储
例如,由节点1导航到节点4的过程为:
(1)由节点1知道其第1条边为边7;
(2)在边文件中通过定长记录计算出边7的存储地址;
(3)由边7通过双向链表找到边8;
(4)由边8获得其中的终止节点id(secondNode),即节点4;
(5)在节点文件中通过定长记录计算出节点4的存储地址。
这些操作除了记录字段的读取,就是定长记录地址的计算,均是 O(1)时间的高效率操作。
可见,正是由于将边作为“一等公民”,将图结构实现为定长记录的存储方案,赋予了Neo4j作为原生图数据库的“无索引邻接”特性。
3.3.2 知识图谱数据库的索引
图数据上的索引一种是对节点或边上属性数据的索引,一种是对图结构的索引;前者可应用关系数据库中已有的 B+树索引技术直接实现,而后者仍是业界没有达成共识的、开放的研究问题。
1.属性数据索引
Neo4j 数据库在前述存储方案的基础上还支持用户对属性数据建立索引,目的是加速针对某属性的查询处理性能。Neo4j索引的定义通过Cypher语句完成,目前支持对于同一个类型节点的某个属性构建索引。
例如,对所有程序员节点的姓名属性构建索引。
![]()
在一般情况下,在查询中没有必要指定需要使用的索引,查询优化器会自动选择要用到的索引。例如,下面的查询查找姓名为张三的程序员,显然会用到刚刚建立的索引。
![]()
应用该索引无疑会根据姓名属性的值快速定位到姓名是“张三”的节点,而无须扫描程序员节点的全部属性。
删除索引的语句为:
![]()
不难发现,为图节点或边的属性建立索引与为关系表的某一列建立索引在本质上并无不同之处,完全可以通过 B+树或散列表实现。这种索引并不涉及图数据上的任何图结构信息。
2.图结构索引
图结构索引是为图数据中的点边结构信息建立索引的方法。利用图结构索引可以对图查询中的结构信息进行快速匹配,从而大幅削减查询搜索空间。大体上,图结构索引分为“基于路径的”和“基于子图的”两种。
(1)基于路径的图索引。一种典型的基于路径的图索引叫作 GraphGrep[36] 。这种索引将图中长度小于或等于一个固定长度的全部路径构建为索引结构。索引的关键字可以是组成路径的节点或边上属性值或标签的序列。
图3-40是在图3-3的属性图上构建的 GraphGrep 索引。这里构建的是长度小于或等于2的路径索引,关键字为路径上的边标签序列,值为路径经过的节点 id 序列。例如,索引将关键字“认识.参加”映射到节点id序列(1, 4, 3)和(1, 4, 5)。
利用该路径索引,类似前面出现过的“查询年龄为29的参加了项目3的程序员参加的其他项目及其直接或间接认识的程序员参加的项目”的查询处理效率会大幅提高,因为由节点1出发,根据关键字“认识.参加”,可以快速找到满足条件的节点3和节点5。
(2)基于子图的索引。基于子图的索引可以看作是基于路径索引的一般化形式,是将图数据中的某些子图结构信息作为关键字,将该子图的实例数据作为值而构建的索引结构。
图3-41是在图3-3的属性图上构建的一种子图索引。满足第1个关键字子图的节点序列为(1, 2, 4),满足第2个关键字子图的节点序列为(1, 4, 3)。
如果查询中包含某些作为关键字的子图结构,则可以利用该子图索引,快速找到与这些子图结构匹配的节点序列,这样可大幅度减小查询操作的搜索空间。
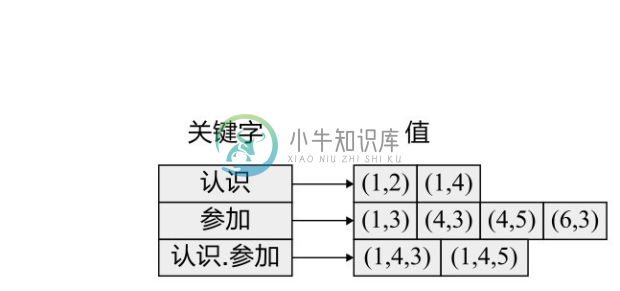
图3-40 基于路径的图索引示例
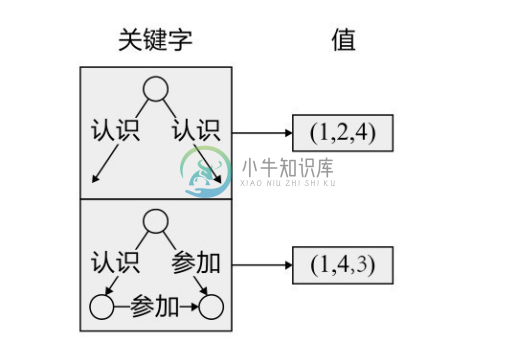
图3-41 基于子图的图索引示例
不过,一个图数据的子图有指数个,将哪些子图作为关键字建立索引尚未得到很好的解决。一种叫作gIndex[37] 的索引方法,首先利用数据挖掘方法,在图数据中发现出现次数超过一定阈值的频繁子图,再将去掉冗余之后的频繁子图作为关键字建立子图索引。但gIndex 建立索引的过程是相当耗时的,而且用户查询中还有可能没有包含任何一个频繁子图,这样就无法利用该子图索引。一种更合理的方法是从用户的查询日志中挖掘频繁使用的子图模式,并以此作为关键字建立索引。