
4.5 知识挖掘
知识挖掘是从已有的实体及实体关系出发挖掘新的知识,具体包括知识内容挖掘和知识结构挖掘。
4.5.1 知识内容挖掘:实体链接
实体链接是指将文本中的实体指称(Mention)链向其在给定知识库中目标实体的过程。实体链接可以将文本数据转化为有实体标注的形式,建立文本与知识库的联系,可以为进一步文本分析和处理提供基础。图4-32给出了一个实体链接的例子,图中左侧是给定的文本,右侧展示了知识库中的四个实体及它们之间的关系。通过实体链接,文本中的实体指称与其在知识库中对应的实体建立了链接。
实体链接的基本流程如图4-33所示,包括实体指称识别、候选实体生成和候选实体消歧三个步骤,每个步骤都可以采用不同的技术和方法。
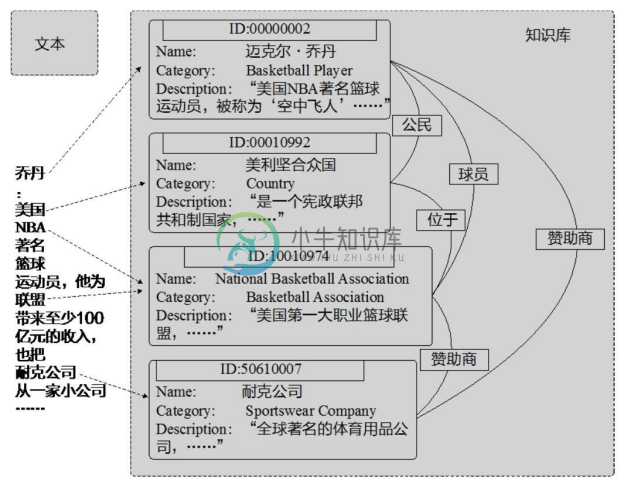
图4-32 实体链接示例
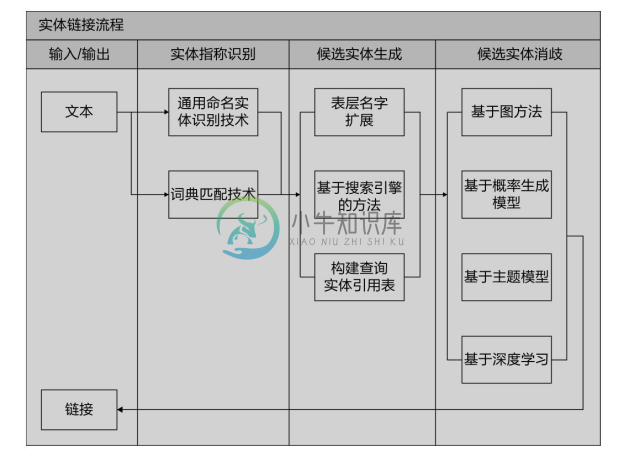
图4-33 实体链接的基本流程
1.实体指称识别
实体链接的第一步是要识别出文本中的实体指称,例如从图4-32给出的文本中识别[乔丹]、[美国]、[NBA]等。该步骤主要通过命名实体识别技术或者词典匹配技术实现。命名实体识别技术在本章前面已经介绍过;词典匹配技术需要首先构建问题领域的实体指称词典,通过直接与文本的匹配识别指称。
2.候选实体生成
候选实体生成是确定文本中的实体指称可能指向的实体集合。例如,上述例子中实体指称[乔丹]可以指代知识库中的多个实体,如[篮球运动员迈克尔乔丹]、[足球运动员迈克尔乔丹]、[运动品牌飞人乔丹]等。生成实体指称的候选实体有以下三种方法:
(1)表层名字扩展。某些实体提及是缩略词或其全名的一部分,因此可以通过表层名字扩展技术,从实体提及出现的相关文档中识别其他可能的扩展变体(例如全名)。 然后,可以利用这些扩展形式形成实体提及的候选实体集合。表层名字扩展可以采用启发式的模式匹配方法实现。例如,常用的模式是提取实体提及邻近括号中的缩写作为扩展结果;例如“University of Illinois at Urbana-Champaign(UIUC)”“Hewlett-Packard(HP)”等。除了使用模式匹配的方法,也有一些方法通过有监督学习的技术从文本中抽取复杂的实体名称缩写。
(2)基于搜索引擎的方法。将实体提及和上下文文字提交至搜索引擎,可以根据搜索引擎返回的检索结果生成候选实体。例如,可以将实体指称作为搜索关键词提交至谷歌搜索引擎,并将其返回结果中的维基百科页面作为候选实体。此外,维基百科自有的搜索功能也可以用于生成候选实体。
(3)构建查询实体引用表。很多实体链接系统都基于维基百科数据构建查询实体引用表,建立实体提及与候选实体的对应关系。实体引用表示例如表4-5所示,它可以看作是一个<键-值>映射;一个键可以对应一个或多个值。在完成引用表构建后,可以通过实体提及直接从表中获得其候选实体。为了构建查询实体引用表,常用的方法是基于维基百科中的词条页面、重定向页面、消歧页面、词条正文超链接等抽取实体提及与实体的对应关系。维基百科词条页面描述的对象通常被当作知识库中的实体,词条页面的标题即为实体提及;重定向页面的标题可以作为其所指向词条实体的提及;消歧页面标题可作为实体提及,其对应的实体是页面中列出的词条实体。维基百科页面中的链接是以[[实体|实体提及]]的格式标记的,因此处理所有的链接可以提取实体和实体提及的对应关系。
表4-5 实体引用表示例
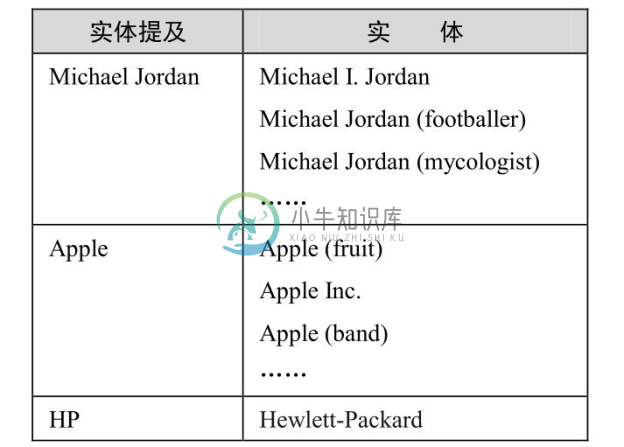
3.候选实体消歧
在确定文本中的实体指称和它们的候选实体后,实体链接系统需要为每一个实体指称确定其指向的实体,这一步骤被称为候选实体消歧。一般地,候选实体消歧被作为排序问题进行求解;即给定实体提及,对它的候选实体按照链接可能性由大到小进行排序。总体上,候选实体消歧方法包括基于图的方法、基于概率生成模型的方法、基于主题模型的方法和基于深度学习的方法等。下面介绍每类方法中具有代表性的工作。[32]
(1)基于图的方法。基于图的方法将实体指称、实体以及它们之间的关系通过图的形式表示出来,然后在图上对实体指称之间、候选实体之间、实体指称与候选实体之间的关联关系进行协同推理。该类方法比较具有代表性的是 Han 等人较早提出的基于参照图(Referent Graph)协同实体链接方法[33] 。Han 等人提出在候选实体消歧时,首先建立如图4-34所示的参照图,图中对实体、提及-实体、实体-实体的关系进行了表示;图中实体提及和实体间的加权边表示了它们的局部依赖性;实体和实体间的加权边代表实体间的语义相关度,为进行全局协同的实体消歧提供了基础。在计算了实体提及的初始重要性度量后,Han 等人的方法将其作为实体消歧的初始依据并在参照图上进行传递,该过程与PageRank 算法中节点 rank 值的传递与更新方式类似。最后,基于实体消歧依据的传递结果,计算一个结合局部相容度和全局依赖性的实体消歧目标函数,为每个实体提及确定能使目标函数最大化的目标实体,从而得到实体消歧结果。采用基于图的方法进行候选实体消歧的实体链接系统还有文献[34]、文献[35]等。
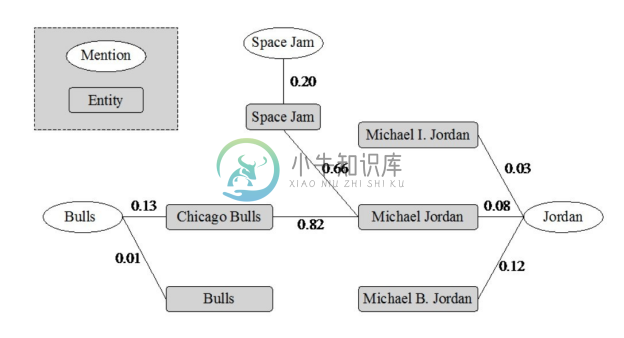
图4-34 参照图[33]
(2)基于概率生成模型的方法。基于概率生成模型对实体提及和实体的联合概率进行建模,可以通过模型的推理求解实体消歧问题。在 Han 等人[36] 提出的实体-提及概率生成模型中,实体提及被作为生成样本进行建模,其生成过程如图4-35所示。
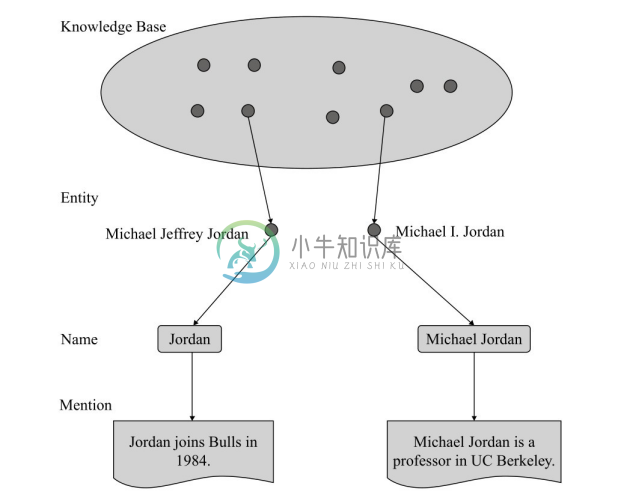
图4-35 实体提及生成过程示例[36]
首先,模型依据实体的概率分布P(e)选择实体提及对应的实体,如例子中的[Michael Jeffrey Jordan]和[Michael I.Jordan];然后,模型依据给定实体 e 实体名称的条件概率P(s|e)选择实体提及的名称,如例子中的[Jordan]和[Michael Jordan];最后,模型依据给定实体 e 上下文的条件概率P(c|e)输出实体提及的上下文。根据上述实体提及的生成过程,实体和提及的联合概率可以定义为
P(m,e)=P(s,c,e)=P(e)P(s|e)P(c|e)
在该方法中,P(e)对应了实体的流行度,P(s|e)对应了实体名称知识,P(c|e)对应了上下文知识。当给定实体提及m时,候选实体消歧通过以下式子实现
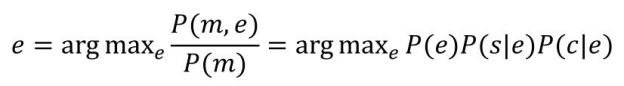
(3)基于主题模型的方法。Han 等人认为,在同一个文本中出现的实体应该与文本表述的主题相关。基于该思想,他们提出了实体-主题模型,可以对实体在文本中的相容度、实体与话题的一致性进行联合建模,从而提升实体链接的结果。实体-主题模型如图4-36所示,给定主题数量T、实体数量E、实体名称数量K和词的数量V,实体-主题模型通过如下过程生成关于主题、实体名称和实体上下文的全局知识。首先,基于E维狄利克雷分布抽样得到每个主题z中实体的分布φz ;然后,基于K维狄利克雷分布抽样得到每个实体e名称的分布ψe ;最后,基于V维狄利克雷分布抽样得到实体e上下文词的分布ξe 。通过吉布斯抽样算法,可以基于实体-主题模型推断获得实体消歧所需的决策信息。
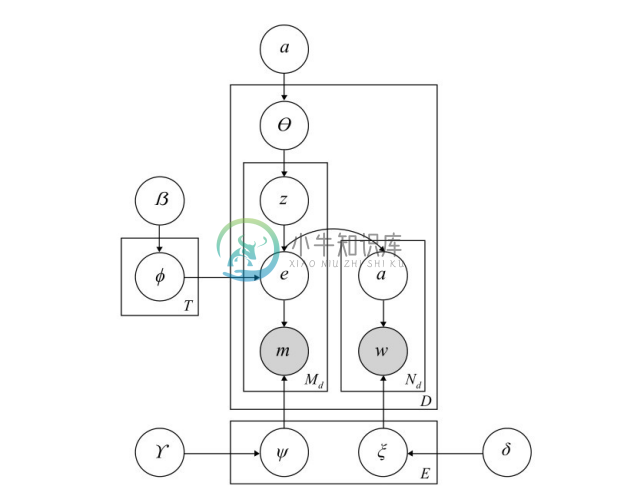
图4-36 实体-主题模型[37]
(4)基于深度学习的方法。在候选实体消歧过程中,准确计算实体的相关度十分重要。因为在利用上下文中信息或进行协同实体消歧时,都需要评价实体与实体的相关度。Huang 等人[38] 提出了一个基于深度神经网络的实体语义相关度计算模型,如图4-37所示。在输入层,每个实体对应的输入信息包括实体 E、实体拥有的关系 R、实体类型 ET和实体描述 D。基于词袋和独热表示的输入经过词散列层进行降维,然后经过多层神经网络的非线性变换,得到语义层上实体的表示;两个实体的相关度被定义为它们语义层表示向量的余弦相似度。
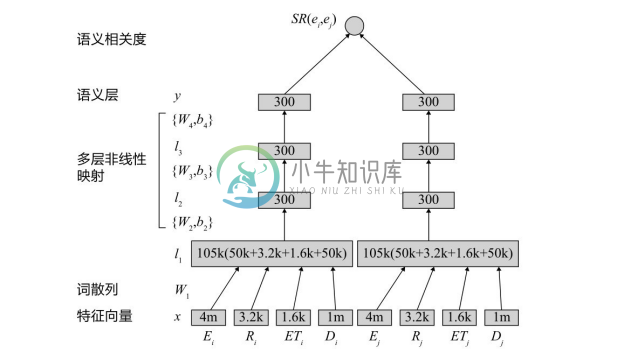
图4-37 实体提及生成过程示例[38]
4.5.2 知识结构挖掘:规则挖掘
1.归纳逻辑程序设计
归纳逻辑程序设计(Inductive Logic Programming,ILP)是以一阶逻辑归纳为理论基础,并以一阶逻辑为表达语言的符号规则学习算法[39] 。知识图谱中的实体关系可看作是二元谓词描述的事实,因此也可通过ILP方法从知识图谱中学习一阶逻辑规则。
给定背景知识和目标谓词(知识图谱中即为关系),ILP 系统可以学习获得描述目标谓词的逻辑规则集合。FOIL[40] 是早期具有代表性的 ILP 系统,它采用顺序覆盖的策略逐条学习逻辑规则,在学习每条规则时,FOIL 采用了基于信息熵的评价函数引导搜索过程,归纳学习一阶规则。下面通过一个例子介绍FOIL的规则学习过程。
设有规则学习问题如表4-6所示。背景知识描述了某一家庭的成员关系,规则学习的目标谓词为 daughter,该目标谓词有若干正例和反例事实。FOIL 在规则学习过程中,从空规则daughter(X,Y)←开始,逐一将可用谓词加入规则体进行考察,按照预定标准评估规则的优劣并选取最优规则;持续谓词的添加直至规则只覆盖正例而不覆盖任何反例。表4-7列出了FOIL学习单个规则的过程。当获得一个满足上述要求的规则后,FOIL将被该规则覆盖的正例移除,然后基于剩余的正例和反例再重复上述过程获得新的规则,直至所有正例都被移除。
表4-6 规则学习问题
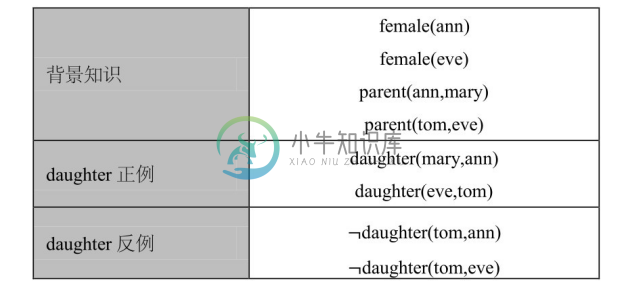
表4-7 FOIL学习单个规则的过程
注:![]() 和
和![]() 分别为被规则ri 覆盖正例和反例的数量。
分别为被规则ri 覆盖正例和反例的数量。
在扩展规则体的每一步,FOIL 选择使得规则 FOIL_Gain 达到最大的谓词加入规则体。FOIL_Gain的定义为:
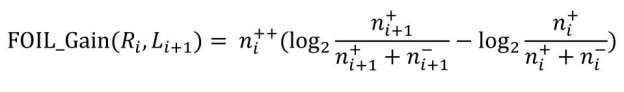
式中,Ri 为当前待扩展的规则;Li+1 为由候选谓词构成的新文字;![]() 和
和![]() 分别为被规则Ri 覆盖正例和反例的数量;
分别为被规则Ri 覆盖正例和反例的数量;![]() 和
和![]() 分别为被新规则Ri+1 覆盖正例和反例的数量;
分别为被新规则Ri+1 覆盖正例和反例的数量;![]() 为同时被规则Ri 和Ri+1 覆盖的正例数量。基于 FOIL_Gain 评价函数,FOIL 在构建规则的每一阶段倾向于选择覆盖较多正例和较少反例的规则。
为同时被规则Ri 和Ri+1 覆盖的正例数量。基于 FOIL_Gain 评价函数,FOIL 在构建规则的每一阶段倾向于选择覆盖较多正例和较少反例的规则。
在早期的 ILP 系统中,还有以 Progol[41] 为代表的基于逆语义蕴涵的学习方法。文献[39,42]对大量 ILP 方法进行了综述。多数 ILP 系统仅适用于小规模的数据集,在较大规模的数据集上运行效率不高。因此,近年来也有大量研究致力于提高 ILP 系统的可扩展性,这些工作包括 FOIL-D[43] 、PILP[44] 、QuickFOIL[45] 和分布式并行的 ILP 系统[46] 等。最近,针对大规模知识图谱的特点,Galarraga 等人研究并提出了 AMIE 系统[47] ;AMIE 采用关联规则挖掘的方法,并定义了新的支持度和覆盖度度量对搜索空间进行剪枝,并可以在知识图谱不完备的条件下评价规则,在规则质量和学习效率方面都比传统ILP方法有很大的提升。在对 AMIE 多个计算过程进行优化后,Galarraga 等人又发布了其升级系统AMIE+[48] ,新系统具有更高的计算效率。
2.路径排序算法(Path Ranking Algorithm,PRA)
PRA[49,50] 是一种将关系路径作为特征的知识图谱链接预测算法,因为其获取的关系路径实际上对应一种霍恩子句,PRA 计算的路径特征可以转换为逻辑规则,便于人们发现和理解知识图谱中隐藏的知识。PRA 的基本思想是通过发现连接两个实体的一组关系路径来预测实体间可能存在的某种特定关系。如图4-38所示,若要预测球员和赛事联盟之间的 AlthletePlaysForLeague 关系,连接实体 HinesWard 和 NFL 的关系路径<AlthletePlaysForTeam, TeamPlaysInLeague>可以作为预测模型的一个重要特征。实际上,该关系路径对应着一个常识知识,可以用图4-39中的霍恩子句表示。在链接预测过程中,PRA 会自动发现有用的关系路径来构建预测模型;PRA 具体的工作流程分为三个重要的步骤:特征选择、特征计算和关系分类。
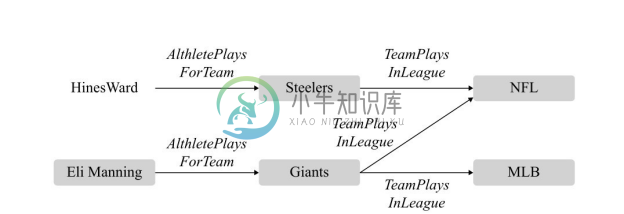
图4-38 示例知识图谱子图[50]
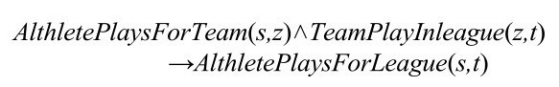
图4-39 霍恩子句
(1)特征选择。因为知识图谱中连接特定实体对的关系路径数量可能会很多,特别是当允许的关系路径长度较长时,关系路径的数量将快速增长。PRA 并不使用连接实体对的所有关系路径作为模型的特征,所以第一步会对关系路径进行选择,仅保留对于预测目标关系潜在有用的关系路径。为了保证特征选择的效率,PRA 使用了基于随机游走的特征选择方法;对于某个关系路径π,PRA 基于随机游走计算该路径的准确度(precision)和覆盖度(coverage)。
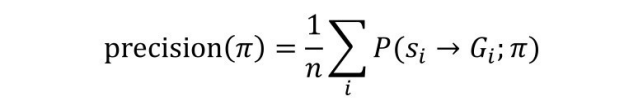
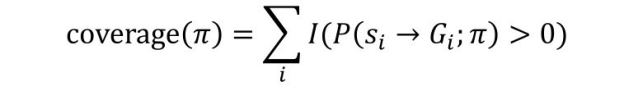
式中,P(si →Gi ;π)是以实体 si 为起点,沿着关系路径π进行随机游走能够抵达目标实体的概率。PRA 对于准确度和覆盖度都分别设定阈值,只有当两个度量值不小于阈值的关系路径时,才被作为特征保留。
(2)特征计算。在选择了有用的关系路径作为特征之后,PRA 将为每个实体对计算其特征值。给定实体对(h,t)和某一特征路径π,PRA将从实体s为起点沿着关系路径π进行随机游走抵达实体 t 的概率作为该实体对在关系路径π特征的值。通过计算实体对在每个特征关系路径上的可达概率,就可以得到该实体对所有特征的值。
(3)关系分类。基于训练样例(目标关系的正例实体对和反例实体对)和它们的特征,PRA 为每个目标关系训练一个分类模型。利用训练完的模型,可以预测知识图谱中任意两个实体间是否存在某特定关系。关系分类可以使用任何一种分类模型,PRA 中使用了逻辑回归分类模型,并取得了较好的效果。PRA 在训练逻辑回归模型的过程中,可以获得关系路径的权重,从而可以对路径的重要性进行排序;而且关系路径具有很好的可解释性。图4-40中列出了PRA在NELL数据集上进行链接预测时获得的重要关系路径和相应解释。

图4-40 PRA在NELL数据集上进行链接预测时获得的重要关系路径和相应解释[50]