
4.1 知识抽取任务及相关竞赛
4.1.1 知识抽取任务定义
知识抽取是实现自动化构建大规模知识图谱的重要技术,其目的在于从不同来源、不同结构的数据中进行知识提取并存入知识图谱中。知识抽取的数据源可以是结构化数据(如链接数据、数据库)、半结构化数据(如网页中的表格、列表)或者非结构化数据(即纯文本数据)。面向不同类型的数据源,知识抽取涉及的关键技术和需要解决的技术难点有所不同。
知识抽取的概念最早在20世纪70年代后期出现于 NLP 研究领域,是指自动化地从文本中发现和抽取相关信息,并将多个文本碎片中的信息进行合并,将非结构化数据转换为结构化数据,包括某一特定领域的模式、实体关系或 RDF 三元组。图4-1给出了一个知识抽取的典型例子。给定一段关于苹果公司的文字描述,知识抽取方法可以自动获取关于苹果公司的结构化信息,包括其总部地址、创始人以及创立时间。
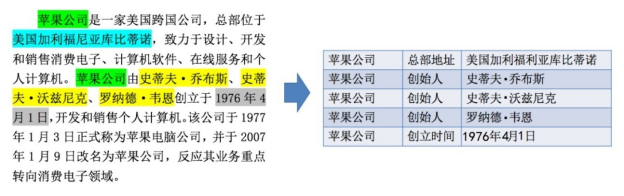
图4-1 知识抽取的典型例子
具体地,知识抽取包括以下子任务:
1.命名实体识别
从文本中检测出命名实体,并将其分类到预定义的类别中,例如人物、组织、地点、时间等。图4-1中高灰色记的文字就是命名实体,在一般情况下,命名实体识别是知识抽取其他任务的基础。
2.关系抽取
从文本中识别抽取实体及实体之间的关系。例如,从句子“[王思聪]是万达集团董事长[王健林]的独子”中识别出实体“[王健林]”和“[王思聪]”之间具有“父子”关系。
3.事件抽取
识别文本中关于事件的信息,并以结构化的形式呈现。例如,从恐怖袭击事件的新闻报道中识别袭击发生的地点、时间、袭击目标和受害人等信息。
4.1.2 知识抽取相关竞赛
一些重要的竞赛对知识抽取技术的发展起到了巨大的推动作用。这些竞赛一般与学术会议同时举办,在明确定义知识抽取相关任务的基础上,提供标准评测数据和评测指标,吸引了大量的参与者。本节将介绍知识抽取相关的重要竞赛。
1.消息理解会议(Message Understanding Conference,MUC)
MUC 由美国国防部高级研究计划局(DARPA)启动并资助,目的是鼓励和开发更好的信息抽取方法。1987—1998年,MUC 会议共举办了七届。MUC 不仅仅是学术会议,其更重要的是在于对信息抽取系统的评测。在每届 MUC 会议前,组织者向参加者提供消息文本的样例和信息抽取任务的说明;参加者开发参赛系统并提交系统的输出结果。各个系统的结果与标准结果比对后得到最终的评测结果,参与者最后在会议上交流技术和感受。
在MUC的评测中,召回率(Recall)和精确率(Precision)是评价信息抽取系统性能的两个重要评价指标。召回率是系统抽取的正确结果占标准结果的比例;精确率是系统抽取的正确结果占其抽取的所有结果的比例。为了综合两个方面的因素考量系统的性能,通常基于召回率和准确率计算F1值。
MUC 会议积极推动了命名实体识别和共指消解等技术的进步与发展。在 MUC 会议中,出现了一些F1值高达90%左右的系统,接近于人工标注的质量。MUC定义的一系列规范以及确立的评价体系也已经成为知识抽取领域的标准。
2.自动内容抽取(Automatic Content Extraction,ACE)
ACE是一项由美国国家标准技术研究所(NIST)组织的评测会议,该会议从1999年至2008年共举办了八次评测。ACE与MUC解决的问题类似,但是ACE对MUC定义的任务进行了融合、分类和细化。ACE 评测涉及英语、阿拉伯语和汉语三种语言,主要包括以下任务:
(1)实体检测和跟踪。这是 ACE 最基础和核心的任务,该任务要求识别文本中的实体,实体类型包括人物(Person,PER)、组织(Organization,ORG)、设施(Facility, FAC)、地缘政治实体(Geographical Political Entity,GPE)和位置(Location,LOC)等。
(2)关系检测与表征。该任务要求识别和表征实体间的关系,关系被分为五大类,包括角色(role)关系、部分整体(part-whole)关系、位于(at)关系、邻近(near)关系和社会(social)关系,每个大类关系又被进一步细分,总共有24种类型。
(3)事件检测与表征。该任务要求识别实体参与的五类事件,包括交互(interaction)、移动(movement)、转移(transfer)、创建(creation)和销毁(destruction)事件。任务要求自动标注每个事件的文本提及或锚点,并按类型和子类型对其进行分类;最后,还需要根据类型特定的模板进一步确定事件参数和属性。
3.知识库填充(Knowledge Base Population,KBP)
KBP 评测由文本分析会议(Text Analysis Conference,TAC)主办,其目标是开发和评估从非结构化文本中获取知识填充知识库的技术。KBP 评测从2009年开始,每年举办一次,截至2017年,已经举办了九届。KBP 评测覆盖了知识库填充的独立子任务以及被称为“冷启动”的端到端知识库构建任务。
独立子任务主要包括以下四个方面:
(1)实体发现与链接(Entity Discovery and Linking,EDL)。主要的EDL任务是在评估文档集合中提取特定个人(PER)、组织(ORG)、设施(FAC)、地缘政治实体(GPE)和位置(LOC)实体的名称和提及,并将每个提及链接到其对应的KB节点。
(2)槽填充(Slot Filling,SF)。插槽填充任务是搜索文档集合以填充特定实体的特定属性(“插槽”)值。
(3)事件跟踪(Event Track)。事件跟踪旨在从非结构化文本中提取关于事件的信息,使其作为结构化知识库的输入。该任务具体包括事件块(Event Nugget)任务(检测和链接事件块)和事件参数(Event Argument)任务(提取属于同一事件的事件参数和链接属于同一事件的参数)。
(4)信念和情感(Belief and Sentiment,BeSt)。信仰和情感跟踪检测实体对另一个实体、关系或事件的信念和情绪。
端到端冷启动知识库构建任务基于给定的知识库模式(KB schema)从文本中获取以下信息:实体,在实体发现与链接任务中定义的实体和实体提及;槽关系,在槽填充中涉及的实体属性(“槽”);事件,在事件跟踪任务中的事件和事件块;事件参数,在事件跟踪任务中的事件参数;情绪,信念和情感任务中源实体向目标实体的情绪。
4.语义评测(Semantic Evaluation,SemEval)
SemEval 是由 ACL-SIGLEX 组织的国际权威的词义消歧评测,目标是增进人们对词义与多义现象的理解。该评测前期被称为 SenseEval,于1998年举办第一届。截至2017年,已经成功举办了十一届。早期评测比较关注词义消歧问题,后来出现了更多文本语义理解的任务,包括语义角色标注、情感分析、跨语言语义分析等。