4.4 面向半结构化数据的知识抽取
半结构化数据是一种特殊的结构化数据形式,该形式的数据不符合关系数据库或其他形式的数据表形式结构,但又包含标签或其他标记来分离语义元素并保持记录和数据字段的层次结构。自万维网出现以来,半结构化数据越来越丰富,全文文档和数据库不再是唯一的数据形式,因此半结构化数据也成为知识获取的重要来源。目前,百科类数据、网页数据是可被用于知识获取的重要半结构化数据,本节将介绍面向此类数据的知识抽取方法。
4.4.1 面向百科类数据的知识抽取
以维基百科为代表的百科类数据是典型的半结构化数据。在维基百科中,词条页面结构如图4-27所示,包含了词条标题、词条摘要、跨语言链接、分类、信息框等要素,这些都是关于描述对象的半结构化数据。
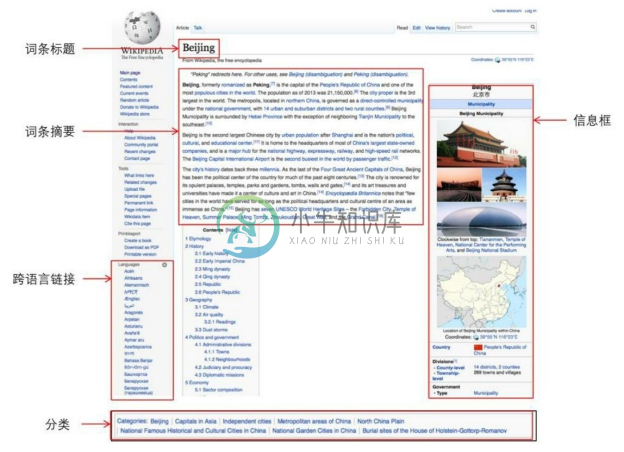
图4-27 维基百科词条页面结构
因为词条包含丰富的半结构化数据,并且其中的信息具有较高的准确度,维基百科已经成为构建大规模知识图谱的重要数据来源。目前,基于维基百科已经构建起多个知识图谱,包括 DBpedia[27] 和 Yago[28] 等。随着中文百科站点的发展,如百度百科、互动百科,一些大规模的中文知识图谱也陆续基于百科数据被构建出来,包括Zhishi.me[29] 、XLore[30] 和 CN-DBpedia[31] 等。在基于百科数据构建知识图谱的过程中,关键问题是如何准确地从百科数据中抽取结构化语义信息。在基于百科数据构建的知识图谱中,DBpedia 是较早发布、具有代表性的知识图谱,下面对它的构建方法进行介绍。
DBpedia 是一个大规模的多语言百科知识图谱,是维基百科的机构化版本。DBpedia采用固定模式对维基百科中的实体信息进行抽取,在 Linking Open Data 原则的指导下,将其以关联数据的形式在Web上发布与共享。得益于维基百科的数据规模,DBpedia是目前最大的跨领域知识图谱之一。截至2019年2月,DBpedia 英文版描述了458万个实体,其中有422万个实体被准确地在一个本体中进行分类,其中包括144.5万个人物、73.5万个地点、41.1万件作品、24.1万个组织、25.1万个物种和6000种疾病。此外,DBpedia 还提供了125种语言的本地化版本,共包含了3830万个事物。完整的 DBpedia数据集包含超过3800万个来自125种不同语言的标签和摘要,2520万个图片链接和2980万个外部网页链接。DBpedia通过大约5000万个RDF链接与其他链接数据集连接,使其成为LOD数据集的重要核心。总体上,DBpedia包含约30亿条RDF三元组,其中5.8亿条是从维基百科的英文版中提取的,24.6亿条是从其他语言版本中提取的。根据抽样评测,DBpedia中RDF三元组的正确率达88%。
图4-28所示为 DBpedia 知识抽取的总体框架。框架的主要组成部分是:页面集合,包含本地及远程的维基百科文章数据;目标数据,存储或序列化提取的 RDF 三元组;将特定类型的维基标记转换为三元组的提取器;支持提取器的解析器,其作用是确定数据类型,在不同单元之间转换值并将标记分解成列表;提取作业,负责将页面集合、提取器和目标数据分组到一个工作流程中;知识提取管理器,负责管理将维基百科文章传递给提取器并将其输出传递到目标数据的过程。
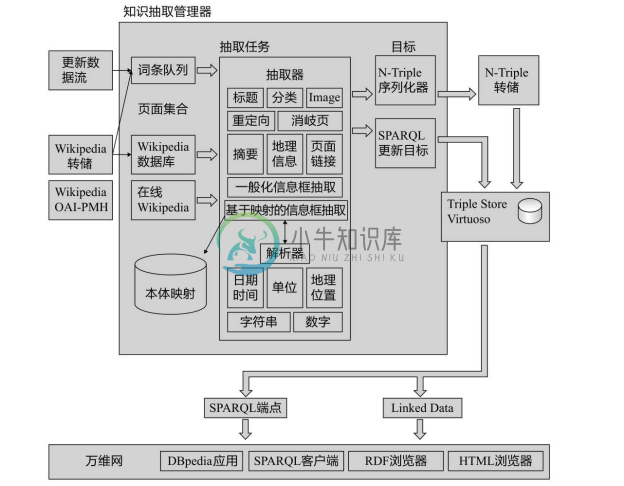
图4-28 DBpedia知识抽取的总体框架[27]
DBpedia使用了多种知识提取器从维基百科中获取结构化数据,具体包括:
●标签(Labels):抽取维基百科词条的标题,并将其定义为实体的标签;
●摘要(Abstracts):抽取维基百科词条页面的第一段文字,将其定义为实体的短摘要;抽取词条目录前最长500字的长摘要。
●跨语言链接(Inter-language Links):抽取词条页面指向其他语言版本的跨语言链接;
●图片(Images):提取指向图片的链接;
●重定向(Redirects):抽取维基百科词条的重定向链接,建立其与同义词条的关联;
●消歧(Disambiguation):从维基百科消歧页面抽取有歧义的词条链接;
●外部链接(External Links):抽取词条正文指向维基百科外部的链接;
●页面链接(Pagelinks):抽取词条正文指向维基百科内部的链接;
●主页(Homepages):抽取诸如公司、机构等实体的主页链接;
●分类(Categories):抽取词条所属的分类;
●地理坐标(Geo-Coordinates):抽取词条页面中存在的地理位置的经纬度坐标。
●信息框(infobox):从词条页面的信息框中抽取实体的结构化信息。
在上述抽取器中,信息框抽取从维基百科中取获得大量的实体属性和实体关系,是DBpedia 中最有价值的信息之一。信息框抽取有两种形式,一种为一般抽取,另一种为基于映射的抽取。信息框的一般抽取直接将信息框中的信息转换为 RDF 三元组。三元组的主语由DBpedia 的URI前缀和词条名称相连组成,谓语由信息框属性URI前缀和属性名相连组成,宾语则基于属性值创建,可以是实体的 URI 或者数据类型的值。然而,这种抽取方式对于维基百科信息框中存在的属性名和信息框模板同义异名问题不作处理,因此抽取出的三元组存在数据不一致的问题。图4-29中展示了两个信息框示例,图4-29(a)中使用birthdata表示出生日期属性,而图4-29(b)中使用databirth表示出生日期属性。为了处理该类问题,DBpedia 使用了基于映射的信息框抽取方法;该方法首先将信息框的模板、属性映射到人工定义的本体中的类型和属性,然后采用本体中的词汇描述抽取出的结构化信息,获得的三元组数据质量更高。

图4-29 信息框示例[27]
4.4.2 面向Web网页的知识抽取
互联网中的网页含有丰富的数据,与普通文本数据相比,网页也具有一定的结构,因此也被视为是一种半结构化的数据。图4-30展示了某电商网站搜索结果页面及其 HTML代码,结果页面中列出一些手机产品的信息。从页面的 HTML 代码中可以看到,产品的名称、价格等具体信息可以通过HTML中的标记区分获取到。
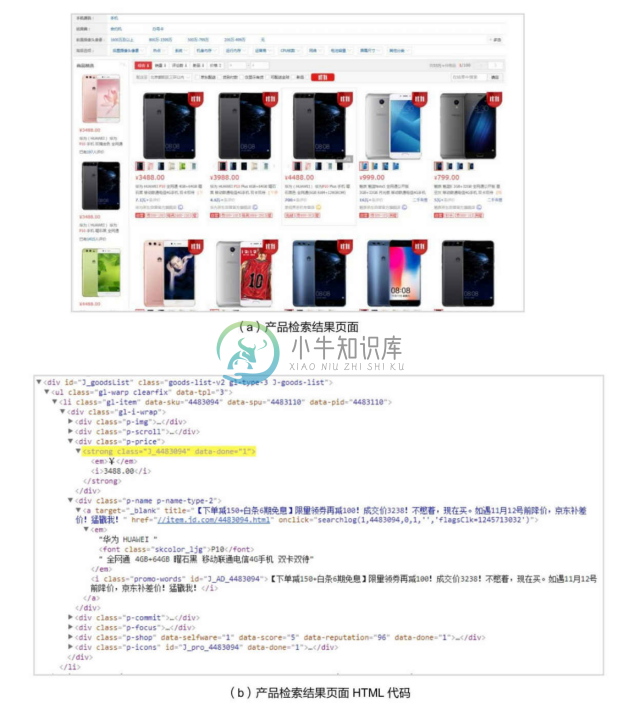
图4-30 某电商网站产品搜索结果页面及其HTML代码
从网页中获取结构化信息一般通过包装器实现,图4-31展示了基于包装器抽取网页信息的框架。包装器是能够将数据从HTML网页中抽取出来,并将它们还原为结构化数据的软件程序。包装器的生成方法有三大类:手工方法、包装器归纳方法和自动抽取方法。
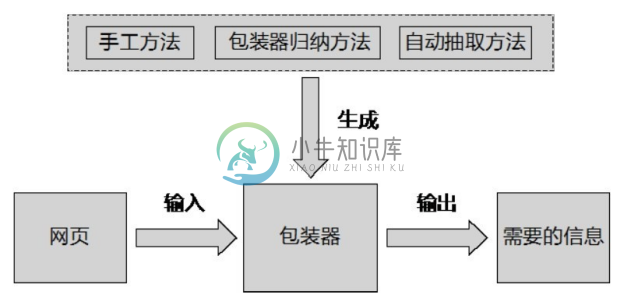
图4-31 基于包装器抽取网页信息的框架
1.手工方法
手工方法是通过人工分析构建包装器信息抽取的规则。手工方法需要查看网页结构和代码,在人工分析的基础上,手工编写出适合当前网站的抽取表达式;表达式的形式一般可以是XPath表达式、CSS选择器的表达式等。
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。借助它可以获取网页中元素的位置,从而获取需要的信息。在图4-30的例子中,如果要获取产品价格信息,则可以定义如下XPath进行抽取:
![]()
CSS 选择器是通过 CSS 元素实现对网页中元素的定位,并获取元素信息的。分析图4-30中的搜索结果页面,价格信息的CSS选择器表达式为:
![]()
2.包装器归纳方法
包装器归纳方法是基于有监督学习方法从已标注的训练样例集合中学习信息抽取的规则,然后对相同模板的其他网页进行数据抽取的方法。典型的包装器归纳流程包括以下步骤:网页清洗、网页标注、包装器空间生成、包装器评估。
(1)网页清洗。纠正和清理网页不规范的HTML、XML标记,可采用TIDY类工具。
(2)网页标注。在网页上标注需要抽取的数据,标注过程一般是给网页中的某个位置打上特殊的标签,表明此处是需要抽取的数据。例如,在图4-30的例子中,如果需要抽取页面上“华为 P10”产品的信息和价格,则可以在产品信息和价格所在的标签里打上一个特殊的标记作为标注。
(3)包装器空间生成。基于标注的数据生成 XPath 集合空间,对生成的集合进行归纳,从而形成若干个子集。归纳的目标是使子集中的XPath能够覆盖尽可能多的已标注数据项,使其具有一定的泛化能力。
(4)包装器评估。包装器可以通过准确率和召回率进行评估。使用待评估包装器对训练数据中的网页进行标注,将包装器输出的与人工标注的相同项的数量表示为 N;准确率是 N 除以包装器输出标注的总数量,而召回率是 N 除以人工标注数据项的总数量。准确率和召回率越高,表示包装器的质量越好。
3.自动抽取方法
包装器归纳方法需要大量的人工标注工作,因而不适用对大量站点进行数据的抽取。此外,包装器维护的工作量也很大,一旦网站改版,需要重新标注数据,归纳新的包装器。自动抽取方法不需要任何的先验知识和人工标注的数据,可以很好地克服上述问题。在自动抽取方法中,相似的网页首先通过聚类被分成若干组,通过挖掘同一组中相似网页的重复模式,可以生成适用于该组网页的包装器。在应用包装器进行数据抽取时,首先将需要抽取的页面划分到先前生成的网页组,然后应用该组对应的包装器进行数据抽取。
上述三种Web页面的信息抽取方法各有优点和缺点,表4-5对它们进行了对比。
表4-5 Web页面的信息抽取方法对比