
8.5 KBQA前沿技术
目前还存在两个很大的困难阻碍着 KBQA 系统被广泛应用。一个困难是现有的自然语言理解技术在处理自然语言的歧义性和复杂性方面还显得比较薄弱。例如,有时候一句话系统可以理解,但是换一个说法就不能理解了。另一个困难是此类系统需要大量的领域知识来理解自然语言问题,而这些一般都需要人工输入。一些系统需要开发一个专用于一个领域的基于句法或者语义的语法分析器。许多系统都引入了一个用户词典或者映射规则,用来将用户的词汇或说法映射到系统本体的词汇表或逻辑表达式中。通常还需要定义一个世界模型(World Model),来指定词典或本体中词汇的上下位关系和关系参数类型的限制。这些工作都是非常消耗人力的。以下围绕 KBQA 的关键阶段——“构建查询”,说明KBQA面临的挑战,然后介绍几种典型的解决方案。
8.5.1 KBQA面临的挑战
图8-20反映了 KBQA 中一个简化的“问题→答案”映射过程,自然语言问题在关联知识库之前,需要转换成结构化查询,利用查询从知识图谱中找到答案后,还需要考虑一个自然语言答案生成的过程。这个过程中的主要挑战在于如何将自然语言表达映射到知识库的查询,也就是Question2Query语义理解。
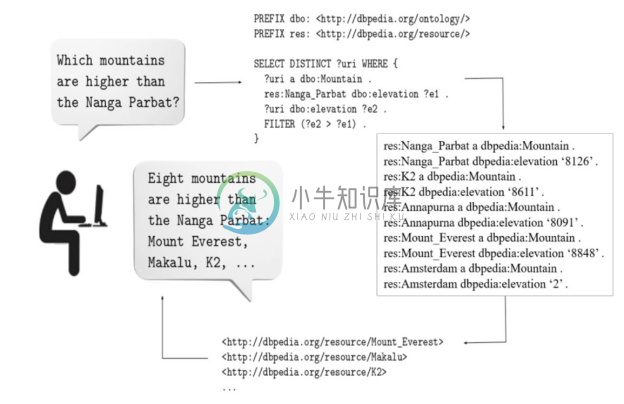
图8-20 问题到答案的映射过程
1.多样的概念映射机制
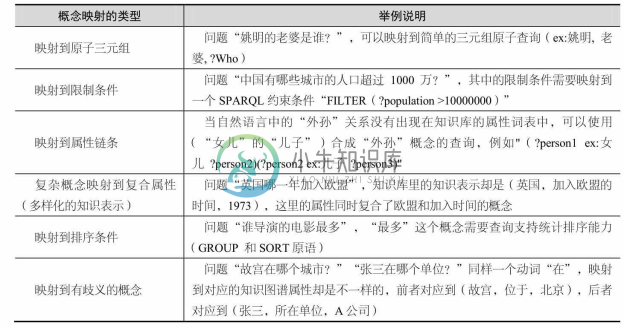
也就是将自然语言表达的查询语义映射知识库的原子查询。自然语言的表达的语义包罗万象,常见语义映射现象如表 8-3所示。
表8-3 常见的语义映射现象
2.不完美的知识库
首先,知识库未必全都是结构化的数据,还有大量的知识存在于文本中。这需要有动态知识抽取解决方案。其次,知识库的知识组织机制各不相同,同样的知识在不同的知识库中未必会采用同样的结构,例如三元组(英国,加入欧盟的时间,1973)等价于四个三元组(事件1,加入方,英国)(事件1,被加入方,欧盟)(事件1,年份,1973)(事件1,类型,加入组织),这样也为查询制造了困难。再次,用户使用的语言以及知识库采用的工作语言也会影响语义理解,例如用中文查询英文的 DBpedia,从中文的关系名称映射到英文的实体属性就不简单。最后,知识库本身并不是完整的,而用户的预期却是希望能找到答案,这样如何判定找不到答案从而避免答非所问也是很重要的。
3.泛化语义理解的预期
当用户使用知识问答时,常见的抱怨就是同一个问题换一种说法就无法理解了。这个问题在智能客服中尤其明显,在保障精确度的前提下智能客服应该匹配尽量可解答的问题。泛化问题通常可以从词语和句子两个层面来研究。
(1)词语层面的泛化匹配[44] 。
① 命名实体的不同说法,例如“上海”对应“沪”,需要从网络或领域专家获取背景知识,而“交通银行股份有限公司”可以通过简单的规则得到简称“交通银行”。
② 生成实体(日期,地址等)的不同说法。例如“2018年1月1日”和“2018年元旦”。注意,生成实体的识别和解析可以通过常规的语法分析工具达成,但是中英文数字的混合、语音识别错误等现象会令解析难度提升。
③ 实体分类和属性或关系的不同说法。例如“还活着吗”对应“死亡日期”,这样的平行语料学习不但可以通过基于知识图谱的关系抽取结果来充实,也可以利用深度学习的分布式表示Embedding来计算。另外,这些语料的目标是建立从自然语言表示到知识图谱表示的映射,所以部分词汇还应该直接映射到知识图谱的实体分类和实体(描述或关系)属性上。还要注意对知识图谱本体的语义融合归一化处理,例如在 Wikidata 里没有统一的“水果”分类,这样就不能通过简单的实体分类获取完整的水果列表。
(2)句子层面的泛化处理。主要是判断问题的语义相似度(Question-Question Similarity)[44] ,常用思路通常采用语言模型、机器翻译模型、句子主题分析模型、句子结构相似度分析模型、基于知识图谱的句子成分相似度模型等,SemEval 的 Task1 和 Task3 SubTaskB[45] 都对这一方面的关键技术做了评测。句子问题相似度算法可以被封装为独立的计算模块,然后将语法分析和前面基于知识图谱的语义解析结果作为特征交给基于LSTM的模型[46] 计算相似度。
8.5.2 基于模板的方法
基于模板(Template)或模式(Pattern)的问答系统定义了一组带变量的模板,直接匹配问题文本形成查询表达式。这样简化了问题分析的步骤,并且通过预制的查询模板替代了本体映射。这样做的优势包括:简单可控,适于处理只有一个查询条件的简单问题;绕过了语法解析的脆弱性。这个方案在工业中得到广泛的应用。
图8-21描述了一个 TrueKnowledge[47] 模板示例,其中包含了以下步骤,首先使用已知的模板成分匹配句子中的内容,包括疑问词(What、Which,反映问题的意图),以及部分已知的模板(is a present central form of,某些固定表达词组),对于未知成分则使用变量字符加以替换(固定表达前后的 a、y 等),这种模板可以实现一对多的问题覆盖效果。但是其缺点也很明显:成熟的应用需要生成大量的模板,True Knowledge 就依赖手工生成了1200个模板,人工处理成本非常高昂;模板由人工生成,不易复用即一个问题可以用多个不同的模板回答,且需要通过全局排序来调优,容易发生冲突;即使生成的模板遵循知识库的 Schema,但由于知识库自身的不完整性以及语义组合的多样性,这些模板也未必就能保障能在知识库中找到答案。注意,TrueKnowledge 利用用户交互的界面降低人工编辑成本,让用户自己将系统无法回答的问题说法链接到一个相关的问题模板上,因此有效地减少了模板的生成数量。

图8-21 TrueKnolwedge 的模板举例[47]
TBSL[48] 在QALD 2012测评任务中提出了一种联合使用语义结构分析以及自然语言词汇—URI 间映射的问答方法。图8-22描述了典型的 TBSL 框架流程,对于用户提出的自然语言问题,经过标注之后,获取具有领域依赖以及独立于领域的两组词法信息;以此为基础进行语义解析,得到问题对应的语义表达;使用模板匹配上述语义表达,完成问题实体的定义过程,包括实体识别、链接以及候选实体排序等。根据模板匹配结果生成多组可能的 SPARQL 查询,通过筛选这些查询,最终生成答案并返回给用户。在基于模板的知识问答框架中,模板一般没有统一的标准或格式,只需结合知识图谱的结构以及问句的句式进行构建即可。TBSL中的模板定义为SPARQL查询模板。
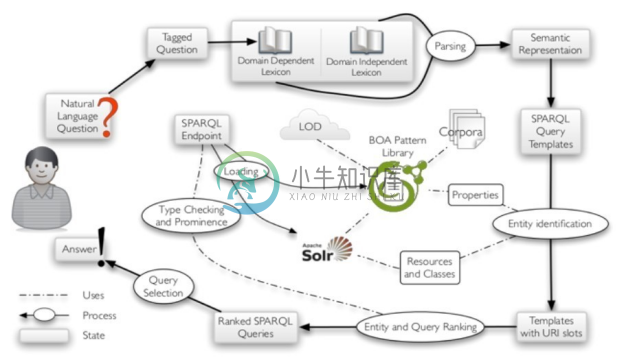
图8-22 典型的TBSL框架流程
TBSL 方法有两个重要的步骤:模板生成和模板实例化。模板生成步骤解析问句结构并生成对应的 SPARQL 查询模板,该查询模板中可能包含过滤和聚合操作。生成模板时,首先需要获取自然语言问题中每个单词的词性标签,然后基于词性标签和语法规则表示问句,接下来利用与领域相关或与领域无关的词汇辅助分析问题,最后将语义表示转化为SPARQL模板。同一条自然语言问句可能对应着不止一条查询模板。因此,TBSL就查询模板的排序也提出了一种方法:首先,每个实体根据字符串相似度以及显著度获得一个打分;其次,根据填充槽的多个实体的平均打分得到一个查询模板的分值。在此基础上,需要检查查询的实体类型。形式化来说,对于所有的三元组 ?x rdf: type <class>,对于查询三元组?x p e和e p ?x,我们需要检查p的定义域(domain)和值域(range)是否与<class>一致。模板实例化步骤将自然语言问句与知识库中的本体概念建立映射。对于Resources和 Classes,实体识别的常用方法主要有两点,一是用WordNet定义知识库中标签的同义词,二是计算字符串间的相似度。对于属性标签,还需要与存储在模式库中的自然语言表示进行比较。最高排位的实体将作为填充查询槽位的候选答案。
1.问题“列举所有的电影出品人”
2.模板生成

3.资源绑定

TBSL 仍然存在的缺点是创建的模板结构未必和知识图谱中的数据契合。另外,考虑到数据建模的各种可能性,对应到一个问题的潜在模板数量会非常的多,同时手工准备海量模板的代价也非常大。针对此问题,CUI等人[49] 针对简单事实问答模板的大规模生成,在自动化处理方面做了进一步优化,如图8-23所示。离线过程(Offline Procedure)侧重基于问题生成模板。利用 NER 结果推算简单二元事实问题(Binary Factorid Question, BFQ)模板,将问题原文中的实体 e 替换为 e 的实体分类,多个实体分类可生成多个模板;基于DBpedia 知识图谱和 Yahoo Answer社区问答对数据的训练数据,利用远程监督技术建立从问题到知识图谱查询的映射。模板映射支持 BFQ,即询问知识图谱中的三元组,例如“how many people are there in Honolulu?”(实体的描述属性)或者“what is the capital of China”(实体的关系属性)。同时,模板映射也支持有特色的问题:排序,例如“which city has the 3rd largest population?”;对比,例如“which city has more people, Honolulu or New Jersey?”;列表,例如“list cities ordered by population”。此外,复杂的问题可以利用语法分析技术,先将问题拆分为多个 BFQ,然后再到本体中逐个映射到属性,最后再从这些结果中挑选合理的组合。例如,“when was Barack Obama's wife born?”可以拆分为who's Barack Obama's wife?(Michelle Obama)和when was Michelle Obama born?(1964)。离线过程采用E-M方法计算条件概率分布P(p|t),p为属性,t为模板。在线过程(Online Procedure)侧重模板选择。通过概率计算给定问题的最优答案。基于给定问题 q0 ,可以提取出 c1 个实体,每个实体至多有 c2 个实体分类,因而至多有 c3 个模板,这些实体至多有 p 个属性(p 为知识库里的所有属性),而每个(实体,属性)对最多对应 c4 个值。其中,c1 、c2 、c3 、c4 都是常数,所以寻求实体的时间复杂度为 O(p),这意味每个问题都能快速得到解答,文中报告在线过程回答单个问题的平均时间为79ms。要注意的是,这里还包括高效率的内存知识图谱查询引擎。这种基于 BFQ 模板的解决方案提升了自动化处理程度,基于2782个意图从语料中学习生成了2700万个模板。当然,BFQ也未必能覆盖用户的所有问题。
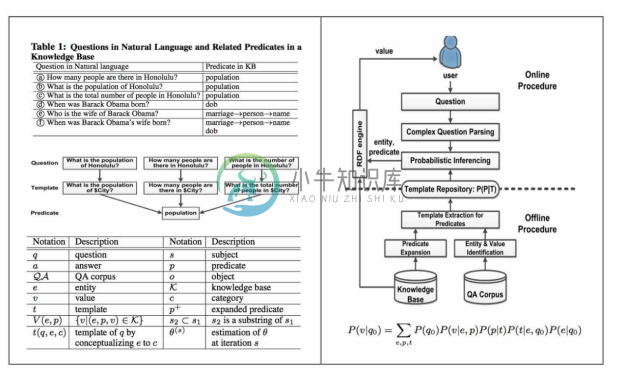
图8-23 CUI等人提出的基于模板的KBQA的架构图及示例[49]
为了解决人工定义模板成本高的问题,Abujabal 等人[50] 提出了 QUINT 模型,可以基于语料自动学习模板,然后基于生成的模板将自然语言查询转换成知识库查询。该方法在WebQuestions数据集上取得了接近最好成绩的效果,在 Free917数据集上取得了当时最好的效果,同时人工监督的工作量也是最少的。
总的来说,基于模板方法的优点是模板查询的响应速度快、准确率较高,可以回答相对复杂的复合问题,而缺点是模板结构通常无法与真实的用户问题相匹配。如果为了尽可能匹配上一个问题的多种不同表述,则需要建立庞大的模板库,耗时耗力且会降低查询效率。
8.5.3 基于语义解析的方法
基于语义解析的方法是指通过对自然语言查询的语法分析,将查询转换成逻辑表达式,然后利用知识库的语义信息将逻辑表达式转换成知识库查询,最终通过查询知识库得到查询结果。
逻辑表达式是语义解析方法与基于模板的方法的主要差异。逻辑表达式是面向知识库的结构化查询,用于查找知识库中的实体及实体关系等知识。相比于模板预先生成且固定的表达方式,逻辑表达式作为人工智能知识表示的经典传承,具备更完备、灵活的知识查询生成体系,包括带参数的原子逻辑表达式,以及基于操作组合的复杂逻辑表达式。原子级别的逻辑表达式通常可分为一元形式(unary)与二元形式(binary),其中一元形式匹配知识库中的实体,二元形式匹配实体之间的二元关系。这两种原子逻辑表达式可以利用连接(Join)、求交集(Intersection)及聚合统计(Aggregate)等操作进一步组合为复杂逻辑表达式。自然语言转化逻辑表达式需要训练一个语法分析器将过程自动化。应注意两个关键步骤:资源映射和逻辑表达式生成。资源映射即将自然语言查询中的短语映射到知识库的资源(类别、关系、实体等),根据处理难度分为简单映射和复杂映射两类。简单映射是指字符形式上比较相似的,一般可以通过字符串相似度匹配来找到映射关系,例如 “出生”和“出生地”的映射。复杂映射是指无法通过字符串匹配找到对应关系的映射,例如“老婆”与“配偶”的映射,这类映射在实际问答中出现的概率更高,一般可以采用基于统计的方法来找到映射关系。逻辑表达式生成即自底向上自动地将自然语言查询解析为语法树,语法树的根节点即是最终对应的逻辑表达式。如图8-24所示,查询“where was Obama born”对应的逻辑表达式是 Type.Location ⊓ PeopleBornHere.BarackObama,其中 lexicon 是指资源映射操作,PeopleBornHere 和 BarackObama 用Join 连接组合,此组合结果再与 Type.Location 用求交集组合成为最终的逻辑表达式。
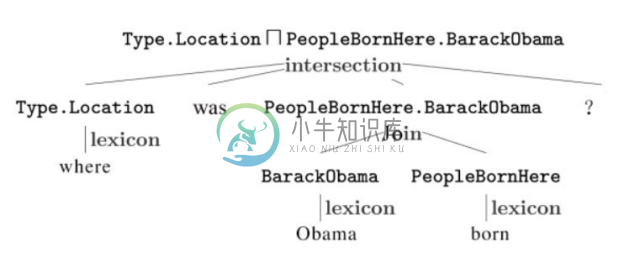
图8-24 自然语言查询转换成逻辑表达式[41]
训练语法分析器需要大量的标注数据,传统的方法是基于规则生成标注数据,通过手工编写规则虽然直接,但是存在较明显的局限性:一方面,规则的编写需要语言学专家完成,导致规则的建立效率低且成本高,还不具备扩展性;另一方面,这种人工规则可能仅适用于某一类语言甚至某一特定领域,泛化能力较弱。为了改进传统方法的缺陷,有大量研究工作采用弱监督或者无监督的方法来训练语法分析器,一个经典的方法是 Berant[41] 提出利用“问题/答案对”数据结合 Freebase 作为语法分析器的训练集。此方法不需要逻辑表示式的专家人工标注数据,可以低成本地获得。Berant 等人[41] 提出的方法重点解决了逻辑表达式生成过程中的四个问题:资源映射(Alignment)、桥接操作(Bridging)、组合操作(Composition)和候选逻辑表达式评估。
(1)资源映射。自然语言实体到知识库实体的映射相对比较简单,属于简单映射,但自然语言关系短语到知识库关系的映射相对复杂,属于复杂映射。例如将“where was Obama born”中的实体 Obama 映射为知识库中的实体 BarackObama,Berant 在文中直接使用字符串匹配的方式实现实体的映射,但是将自然语言短语“was also born in”映射到相应的知识库实体关系 PlaceOfBirth 则运用了基于统计的方法。首先从文本中收集了大量(Obama, was also born in, August 1961)这样的三元组,然后将三元组中的实体进行对齐和并将常量进行归一化,把三元组转换成(BarackObama, was also born in, 1961-08)这样的标准形式,再通过知识库得到三元组中实体的类型,将三元组转换成 r[t1 ,t2 ]的形式,例如“was also born in[Person, Date]”。如图8-25所示,左边的“grew up in”是三元组中的自然语言关系短语 r1 ,右边的“DateOfBirth”是知识库中的关系 r2 。统计所有自然语言三元组中符合 r1 [t1 ,t2 ]的实体对,得到集合 F(r1 ),统计知识库中符合 r2 [t1 ,t2 ]的实体对,得到集合F(r2 )。通过比较集合 F(r1 )和集合 F(r2 )类似 Jaccard 距离特征确定是否建立 r1 与 r2 的资源映射。
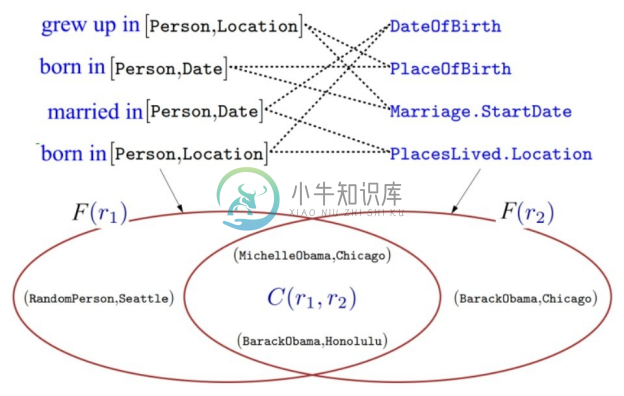
图8-25 关系短语映射到知识库关系的方法[41]
(2)桥接操作。在完成资源映射后仍然存在一些问题,首先,例如 go、have、do 等轻动词(Light Verb)由于在语法上使用相对自由,难以通过统计的方式直接映射到实体关系上;其次,部分知识库关系的出现频率较低,利用统计也较难找到准确的映射方式。这样就需要补充一个额外的二元关系将这些词两端的逻辑表达式连接起来,这就是桥接操作。如图8-26所示,“Obama”和“college”映射为 BarackObama和Type.University,但是“go to”却难以找到一个映射,需要寻找一个二元关系 Education 使得查询可以被解析为 Type.University ⊓ Education.BarackObama 的逻辑表达式。由于知识库中的关系是有定义域和值域的,所以文献基于此特点在知识库中查找所有潜在的关系,例如 Education 的定义域和值域分别是 Person 和 University,则 Education 可以是候选的桥接操作。这里针对每一种候选的桥接操作都会生成很多特征,基于这些特征训练分类器,用于最后的候选逻辑表达式评估。
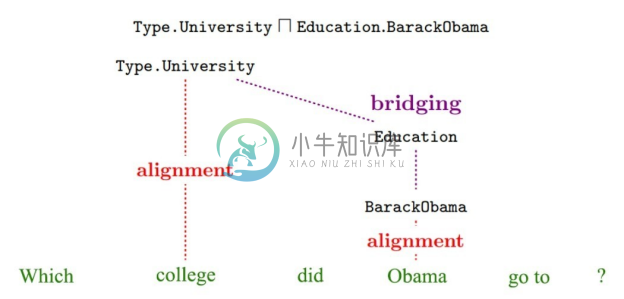
图8-26 桥接操作示例[41]
(3)组合操作。即逻辑表达式间的连接、求交集以及聚合三种操作。至于最终应该用哪种操作,作者同样通过收集大量的上下文特征,基于这些训练分类器,用于最后的候选逻辑表达式评估。
(4)候选逻辑表达式评估。即训练一个分类器,计算每一种候选逻辑表达式的概率, Berant 等人基于前面候选逻辑表达式生成过程中的所有特征,训练了一个 Discriminative Log-Linear模型,最终实现逻辑表达式的筛选。
8.5.4 基于深度学习的传统问答模块优化
基于深度学习的知识问答主要有两个方向,分别是利用深度学习对传统问答方法进行模块级的改进和基于深度学习的端到端问答模型。
深度学习可以直接用于改进传统问答流程的各个模块,包括语义解析、实体识别、意图分类和实体消歧等。实体识别模块可以使用 LSTM+CRF 以及近来兴起的 BERT 提升实体识别正确率;在关系分类、意图分类模块方面,可以使用基于字符级别的文本分类深度学习方法,甚至针对语言和领域提供预训练模型;实体消歧模块也可以使用基于深度学习的排序方法判定一组概念的语义融洽度。
下面通过 Yih[51] 的工作,说明如何使用深度神经网络来提升知识问答的效果。传统的基于语义解析的方法需要将问题转换成逻辑表达式,如图8-27所示。这类方法最大的问题是找到问题中自然语言短语与知识库的映射关系,Yih 等人提出了一种语义解析的框架,首先基于问句生成对应的查询图(Query Graph),然后用该查询图在知识库上进行子图匹配,找到最优子图即找到问题的答案。因为查询图可以直接映射到 Lambda Calculus形式的逻辑表达式,并且在语义上与 λ-DCS(Lambda Dependency-Based Compositional Semantics)紧密相关,因此就可以将语义解析的过程转换成查询图生成的过程。
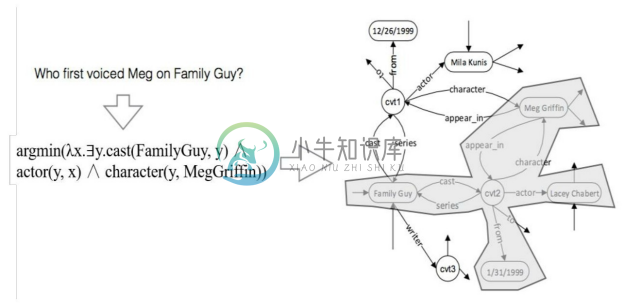
图8-27 通过逻辑表达式转化成知识库查询的过程
查询图由四种节点组成,包括实体(Grounded Entity)、中间变量(Existential Variable)、聚合函数(Aggregation Function)和Lambda变量(Lambda Variable),图8-28是一个查询图示例,其中实体在图中用圆角矩形表示,中间变量在图中用白底圆圈表示,聚合函数用菱形表示,Lambda 变量(即答案节点)用灰底圆圈表示。这个例子对应的问句是“Who first voiced Meg on Family Guy?”,在不考虑聚合操作的情况下,该查询图对应的逻辑表达式是λx.∃y.cast(FamilyGuy, y)∧ actor(y, x)∧ character(y, MegGriffin)。
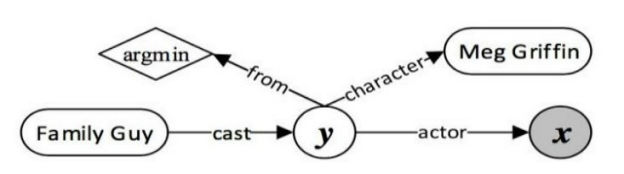
图8-28 查询图示例[51]
下面介绍查询图的生成过程。第一步,选择一个主题实体(Topic Entity)作为根节点,如图8-29(a)中可以选择 s1 “Family Guy”作为根节点。第二步,确定一条从根节点到 Lambda 变量(答案节点)的有向路径,路径上可以有一个或者多个中间变量,这条路径被称为核心推断链(Core Inferential Chain),如图8-29(b)所示从三条路径s3 、s4 、s5 中选取s3 作为核心推断链。核心推断链上除了根节点为实体,其他的都只能是变量,节点间的关系都是知识库中的关系。第三步,给查询图添加约束条件和聚合函数(Augmenting Constraints & Aggregations),形式上就是把其他的实体或者聚合函数节点通过知识库中的关系与核心推断链上的变量连接起来,如图8-29(c)所示对 y 增加两个限制argmin和character(y, MegGriffin)。
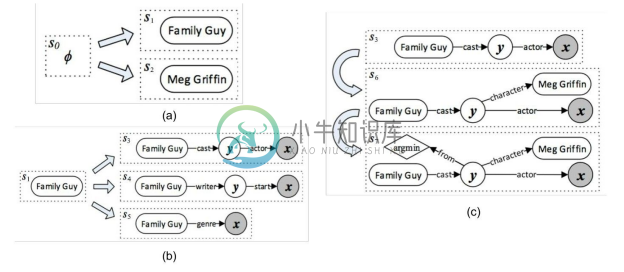
图8-29 查询图的生成过程[51]
对于生成查询图的第二步,需要一种从众多候选核心推断链中选出最优核心推断链的方法,针对图8-29(b)的例子,要评估{cast-actor,writer-start,genre}三个谓语序列中哪个最接近问题中“Family Guy”和“Who”的关系,该文献使用一个 CNN 网络将候选序列和问题文本中的关键词向量化,CNN 结构如图8-30所示,通过语义相似度计算找到最优的核心推断链。具体做法是将自然语言问题和谓语序列分别通过图8-30所示的网络得到两个300维的分布式表达,然后利用表达向量之间的相似度距离(如cosine距离)计算自然语言问题和谓语序列的语义相似度得分。该 CNN 网络的输入运用了词散列技术[52] ,将句子中每个单词拆分成字母三元组,每个字母三元组对应一个向量,比如单词 who 可以拆为#-w-h,w-h-o,h-o-#,每个单词通过前后添加符号#来区分单词界限。然后通过卷积层将3个单词的上下文窗口中的字母三元组向量进行卷积运算得到局部上下文特征向量ht ,通过最大池化层提取最显著的局部特征,以形成固定长度的全局特征向量 v,然后将全局特征向量 v 输送到前馈神经网络层以输出最终的非线性语义特征 y,作为自然语言问题或核心推断链的向量表示。
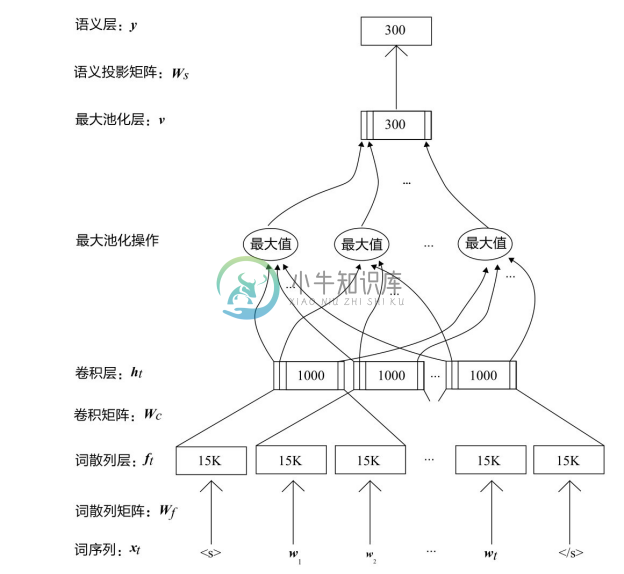
图8-30 Yih[51] 中的CNN结构
8.5.5 基于深度学习的端到端问答模型
端到端的深度学习问答模型将问题和知识库中的信息均转化为向量表示,通过向量间的相似度计算的方式完成用户问题与知识库答案的匹配。首先根据问题中的主题词在知识库中确定候选答案,然后把问题和知识库中的候选答案都通过神经网络模型映射到一个低维空间,得到它们的分布式向量(Distributed Embedding),则可计算候选答案分布式向量与问题向量的相似度得分,找出相似度最高的候选答案作为最终答案。该神经网络模型通过标注数据对进行训练,使得问题向量与知识库中正确答案的向量在低维空间的关联得分尽量高。
典型的工作有Bordes A等人[53] 提出的方法,为解决WebQuestions上数据量不够的问题,文献作者使用一些规则从 Freebase、ClueWeb 等知识库中构建了大量(问题,知识库答案)的标注数据用于训练模型。如图8-31所示,自底向上计算。第一步,利用实体链接定位问题中的核心实体,对应到Freebase的实体;第二步,找到从问题中核心实体到候选答案实体的路径;第三步,生成候选答案的子图;第四步,分别将问题和答案子图映射成Embedding向量;第五步,进行点积运算,获得候选答案和问题之间的匹配度。该方法取得了比Berant[41] 更好的结果(F1=0.392, P@1=0.40)。
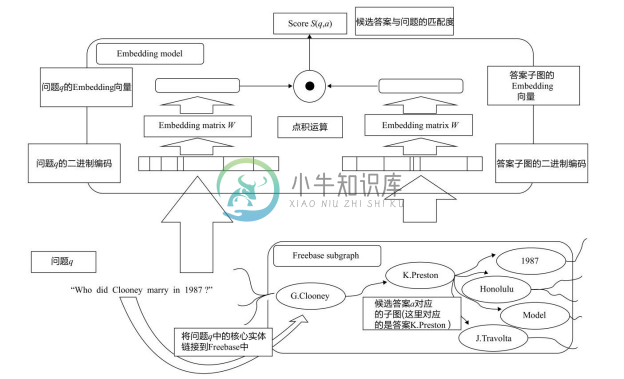
图8-31 Bordes A等人提出方法的核心流程[53]
另一个基于 Multi-Column CNN[54] 的工作,该工作同时训练自然语言问句词向量与知识库三元组,将问题与知识库映射到同一个语义空间。该工作针对知识库的特点,定义了答案路径(Answer Path)、答案上下文(Answer Context)和答案类型(Answer Type)三类特征,每一类特征都对应一个训练好的卷积神经网络,以此计算问题和答案的相似度。这三个 CNN 被称为多列卷积神经网络(Multi-Column Convolutional Neural Network, Multi-Column CNN)。该方法的核心流程如图8-32所示,对于问题“when did Avatar release in UK”,首先通过 Multi-Column 卷积神经网络提取该问题的三个分布式向量。然后利用命名实体识别、实体链接等技术,从问题文本中找到能链接到知识库的实体,与该实体相关联的每一个实体都是候选答案实体;再基于候选答案实体形成三个分布式向量,包括斜线矩形(“Avatar”)对应主题词路径向量,虚线椭圆(“United Kingdom”“film.file_region”)对应上下文向量,“datetime”对应答案类型向量。最后,通过分别点乘运算再求和的方式得到最终的答案-问题对得分。在实验中,该方法取得了当时最好的效果(F1=0.408,P@1=0.45)。
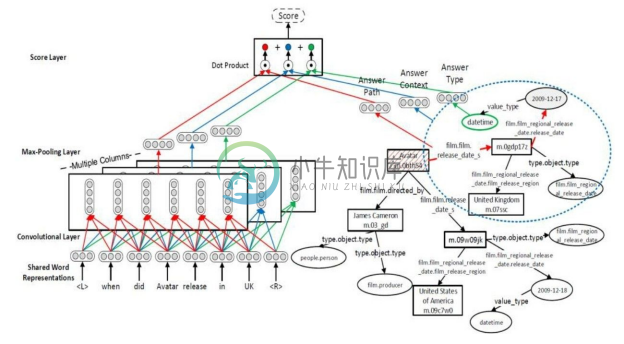
图8-32 基于Multi-Column CNN方法的核心流程[54]