
8.2 知识问答的分类体系
本节围绕问答系统四大要素——问题、答案、知识库、智能体,简要梳理知识问答系统的特征并研究知识问答的分类体系。问答系统还有很多更深入的综述[10-14] 。
8.2.1 问题类型与答案类型
在知识问答中,首先可以通过对问题的类型(Question Type)理解问答目标。问答系统可以针对问题类型,选择对应的知识库、处理逻辑来生成答案[15] 。问题分类体系在很大程度上按照目标答案的差异而区分,所以这里将问题类型和答案类型合并,统一考虑为问题类型。通过对问题的类型(也就是用户问题所期望的答案的类型)的分析,问答系统可以有针对性地选择有效的知识库和处理逻辑解答一类问题。
早期的工作包括TREC测试集问题分类研究[15] 和ISI QA 问题类型分类体系[16] ,另外还有更详细的综述[17] 。LI 等人[15] 通过观察 TREC 的 1000 个问题的数据,从答案类型出发建立了一个问题分类体系,包含 6 个大类和 50 个细分类,并对各类问题的占比进行了统计。从统计结果中可以看出,TREC 中的大部分问题都集中在这几类数据,占总体问题数量的78%。其中,81个问题询问地点(LOCATION)、138个问题询问定义或描述(DESCRIPTION)、65个问题询问人物(HUMAN)、94个问题询问事物(例如动物、颜色、食品等)。可见,在知识问答中,一个合理的分类体系能够体现出问题的类型分布,从而帮助开发者有针对性地设计问答解决方案,并形成良好的问答系统。图8-6展示了ISI QA问题类型分类体系及实例[16] ,例如“Who was Jane Goodall?”这类问题就可以归属为人物定义型问题(WHY-FAMOUS-PERSON)。

图8-6 ISI QA问题类型分类体系及实例
后续也出现了基于功能的问题分类体系。例如,在英文中一个以“Why”开头的问题侧重询问原因,而以“How”开头的问题侧重询问解决方式。但是在中文里,带有“怎么样”这个词的问题,其意图有可能是询问原因,也有可能是询问解决方式。BU 等人[18] 根据百度知道的数据,建立了一个基于功能(Function-Based)的问题分类体系。和 LI 等人[15] 从答案类型出发构建分类体系类似,BU 等人[18] 从利用功能以达成用户目标的角度来构建分类体系。相比于 LI 等人[15] 专注于面向事实的知识问答的分类,BU 等人[18] 提出的分类体系更面向通用问题。表8-2展示了BU等人[18] 提出的问题分类体系机制,其中的事实类别和 LI 等人[15] 提出的分类体系中的大部分类别相对应。图8-7统计各个类在百度知道中的占比。
表8-2 BU等人提出的问题分类机制[18]
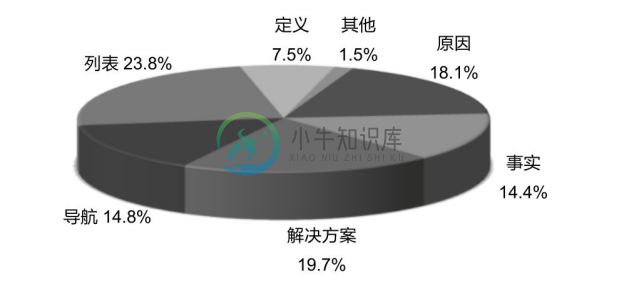
图8-7 基于功能的问题分类体系在百度知道中的占比[18]
综合分类体系的探索工作,本文从问答的功能出发,面向知识图谱问答的构建(即假定知识库的主题为知识图谱)整理出两种问题类型:事实性客观问题和主观深层次问题。
(1)事实性客观问题。 特点是语法结构简单(拥有明确的主谓宾结构,不包括例如并列、否定等复杂结构)、语义结构清晰(通常是关于某个事物或事件的简单描述性属性或关系型属性,可以通过简单的数据库查询解答)。事实型问题是知识问答中处理频度较高的一种问题类型,其中包含了谓词型问题(答案是一个单一的对象)、列表型问题(返回的不止一个答案,而是一列答案)。这两种主要是返回某些对象,从查询的角度来看,类似于数据库的 Select 操作。而对错型的问题更像 SPARQL 中的 Ask 类型的查询。实际上,这并不需要理解为一种“硬边界”的分类,也可能存在某些问题属于多个类别的情况。可以细分如下:
① 询问命名实体的基本定义(ENTITY)
●事物的分类(IS-A),例如“热带水果有哪些?”
●事物的别名(ALIASEs),例如“番茄是西红柿吗?”
●事物的定义(WHAT-IS),例如“什么是西红柿?”
② 询问实体属性,包括描述性属性和关系性属性 (PROPERTY)
●人(WHO),例如“谁写了《平凡的世界》?”
●地点(WHERE),例如“《平凡的世界》的主人公是哪里人?”
●时间(WHEN),例如“北京奥运会是在哪一年举办的?”
●属性(ATTRIBUTE),例如“西红柿是什么颜色的?”
③ 复杂知识图谱查询
●询问实体列表或统计结果,例如“唐宋八大家是哪几位?”“北京奥运会中国得了多少枚金牌?”“北京四月份的平均气温是多少?”“北京最大的公园是哪一个?”
●询问实体差异,例如“颐和园和圆明园哪里相似,哪里不同?”
●询问实体关系,例如“王菲和章子怡有什么关系?”“A 公司和 B 公司有没有控制关系?”
(2)主观深层次问题。包括除事实型问题之外的其他问题,例如观点型、因果型、解释型、关联型与比较型等。这一类问题本身的语法结构并不复杂,但是这些问题需要一定的专业知识和主观的推理计算才能解答,而且这一类问题有时甚至不止一个答案,需要结合用户偏好和智能体的配置找到不同的最优解。可以细分如下:
① 问解释(WHY),例如“为什么天空是蓝色的?”“为什么眼睛会近视?”
② 问方法(HOW),例如“怎么做戚风蛋糕?”“如何在 Windows 上创建一个文件夹?”
③ 问专家意见(CONSULT),例如“左侧内踝骨折累及关节面多少天能下地走路?今年89岁。”
④ 问推荐(RECOMMENDATION),例如“哪个歌手跟刘德华类似?”
另外,问题类型并非问题理解中的唯一语义要素。问题焦点(Focus)指的是问句中出现的与答案实体或属性相关的元素,例如问句“In which city was Barack Obama born?”中的city,以及“What is the population of Galway?”中的population。问题主题(Topic)反映问题是关于哪些主题的,例如问句“What is the height of Mount Everest?”询问的是关于地理及山脉的信息,而“Which organ is affected by the Meniere's disease?”的问题主题则是医疗方面的内容。
8.2.2 知识库类型
从知识库的内容边界,或者知识库覆盖了哪些领域来看,知识问答可以分两类。一是领域相关的问答系统,只回答与选定领域相关的问题。这一类系统相对专注,需要领域专家的深入参与,虽然问题覆盖面小,但是答案的正确率高。早期的成功问答系统都是与领域相关的。近年来,企业的智能客服通常采用领域相关的问答系统,并且逐步转向基于知识图谱的解决方案。二是领域无关的问答系统,基于开放知识库回答任意问题。这一类系统答案虽然覆盖面大,但答案的正确率有限。开放域问答系统经常使用万维网数据(尤其是百科网站、社区问答等)作为数据源解答用户的问题。由于用户的期望较高,开放问题结构并不总是简单,开放域知识相对稀疏等原因,实用产品的用户体验还有待提高。
从知识库的信息组织格式来看,知识库可以是基于文本表示,也可以采用其他组织形式。第一,文本类知识库利用纯文本承载知识,也是最常见的知识组织形式。这类知识库不但支持基于搜索的问答系统,也可以与基于知识图谱的结构化抽取技术结合,支持基于语义查询的解决方案。另外,常见问答对(FAQ)或社区问答也是知识问答(尤其是智能客服)最容易获取的知识,可以直接通过问题匹配帮助用户获取答案。第二,半结构化或结构化的知识库。这一类知识库侧重知识的细粒度组织,利用结构体现知识的语义。电子表格、二维表或者关系数据库是最常见的结构化知识,实体和属性通过简单的二维表表示,大多数事实性客观问题都可以被此类知识解答。图数据库,例如 RDF、属性图、语义网络等,将通过节点、有向边来形成基于图的知识组织,并且利用节点和边的名称与上下文对接自然语言处理并支持语义相似度计算,同时还能支持复杂的结构化图查询机制。第三,除文字外,知识也可以存储在图片、音频、视频等媒体中,这些都可以作为知识问答中答案的一部分,更有效地反馈给终端用户,从而丰富答案的表示并满足更多的交互场景需求。第四,知识库并不限定于文本、符号系统或多媒体,也可以利用可计算的机器学习模型承载。例如近年来出现的端到端的问答系统可以直接使用分布式表示模型记录习得的知识。
另外,知识库的存储访问机制也是知识问答需要考虑的因素。知识问答的知识可以采用单一的集中数据存储(例如数据表、数据库),或者分布式存储(例如分布式数据、数据仓库),甚至是基于互联网的全网数据(例如Linked Data)。
8.2.3 智能体类型
智能体利用知识库实现推理。根据知识库表示形式的不同,目前的知识问答可以分为传统问答方法(符号表示)以及基于深度学习的问答方法(分布式表示)两种类型。传统问答方法使用的主要技术包括关键词检索、文本蕴涵推理以及逻辑表达式等,深度学习方法使用的技术主要是LSTM[19] 、注意力模型[20] 与记忆网络(Memory Network)[21] 等。
传统的知识库问答将问答过程切分为语义解析与查询两个步骤。如图8-8所示,首先将问句“姚明的老婆出生在哪里”通过语义解析转化为 SPARQL 查询语句。这个例子中的难点是将问句中的“老婆”映射到知识图谱中的关系“配偶”,这也是传统的知识库问答研究的核心问题之一;再从知识库(知识图谱)中查询,得到问题的答案“上海”。
不同于传统方法,基于分布式表示的知识库问答利用深度神经网络模型,将问题与知识库中的信息转化为向量表示,通过相似度匹配的方式完成问题与答案的匹配。图8-9描述了一种精简的分布式知识问答过程。首先,利用神经网络模型,将问题“姚明的老婆出生在哪里”表示成向量,这里使用的是一个递归神经网络的表达形式;然后取知识图谱中与实体“姚明”相关的实体向量,计算与问句向量的语义相似度,从而完成知识问答的过程。在整个过程中,并不需要确定问句中的“老婆”与知识图谱中的关系“配偶”的映射,这也是基于深度学习的问答方法的优势所在。
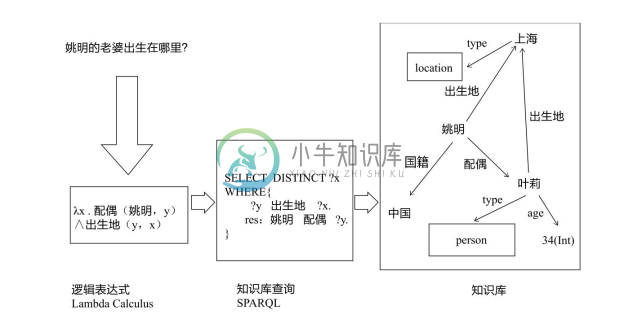
图8-8 基于符号表示(传统)的知识问答
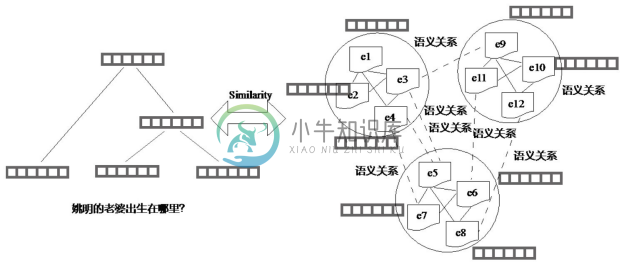
图8-9 基于分布式表示的知识库问答