
9.1 领域知识图谱构建的技术流程
由于现实世界的知识丰富多样且极其庞杂,通用知识图谱主要强调知识的广度,通常运用百科数据进行自底向上的方法进行构建。而领域知识图谱面向不同的领域,其数据模式不同,应用需求也各不相同,因此没有一套通用的标准和规范来指导构建,而需要基于特定行业通过工程师与业务专家的不断交互与定制来实现。虽然如此,领域知识图谱与通用知识图谱的构建与应用也并非完全没有互通之处,如图9-1所示,其从无到有的构建过程可分为六个阶段,被称为领域知识图谱的生命周期 [1] 。本节以生命周期为视角来阐述领域知识图谱构建过程中的关键技术流程。
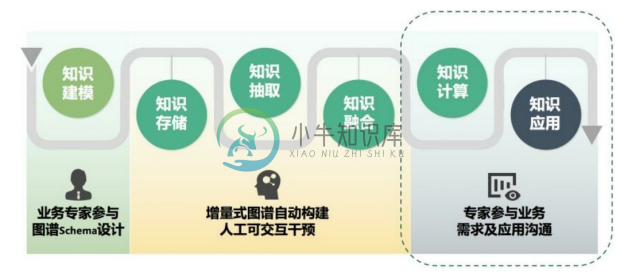
图9-1 领域知识图谱生命周期
9.1.1 领域知识建模
知识建模是建立知识图谱的概念模式的过程,相当于关系数据库的表结构定义。为了对知识进行合理的组织,更好地描述知识本身与知识之间的关联,需要对知识图谱的模式进行良好的定义。一般来说,相同的数据可以有若干种模式定义的方法,设计良好的模式可以减少数据的冗余,提高应用效率。因此,在进行知识建模时,需要结合数据特点与应用特点来完成模式的定义。
知识建模通常采用两种方式:一种是自顶向下(Top-Down)的方法,即首先为知识图谱定义数据模式,数据模式从最顶层概念构建,逐步向下细化,形成结构良好的分类学层次,然后再将实体添加到概念中。
另一种则是自底向上(Bottom-Up)的方法,即首先对实体进行归纳组织,形成底层概念,然后逐步往上抽象,形成上层概念。该方法可基于行业现有标准转换生成数据模式,也可基于高质量行业数据源映射生成。
为了保证知识图谱质量,通常在建模时需要考虑以下几个关键问题:
1)概念划分的合理性,如何描述知识体系及知识点之间的关联关系[1] ;
2)属性定义方式,如何在冗余程度最低的条件下满足应用和可视化展现;
3)事件、时序等复杂知识表示,通过匿名节点的方法还是边属性的方法来进行描述,各自的优缺点是什么[2] ;
4)后续的知识扩展难度,能否支持概念体系的变更以及属性的调整。
关于知识建模的详细知识和技术,请参考本书第2章。
9.1.2 知识存储
知识存储,顾名思义为针对构建完成的知识图谱设计底层存储方式,完成各类知识的存储,包括基本属性知识、关联知识、事件知识、时序知识、资源类知识等。知识存储方案的优劣会直接影响查询的效率,同时也需要结合知识应用场景进行良好的设计。
目前,主流的知识存储解决方案包括单一式存储和混合式存储两种。在单一式存储中,可以通过三元组、属性表或者垂直分割等方式进行知识的存储[3] 。其中,三元组的存储方式较为直观,但在进行连接查询时开销巨大[4] 。属性表指基于主语的类型划分数据表,其缺点是不利于缺失属性的查询[5] 。垂直分割指基于谓词进行数据的划分,其缺点是数据表过多,且写操作的代价比较大[6] 。
对于知识存储介质的选择,可以分为原生(Neo4j、AllegroGraph 等)和基于现有数据库(MySQL、Mongo 等)两类。原生存储的优点是其本身已经提供了较为完善的图查询语言或算法的支持,但不支持定制,灵活程度不高,对于复杂节点等极端数据情况的表现非常差。因此,有了基于现有数据库的自定义方案,这样做的好处是自由程度高,可以根据数据特点进行知识的划分、索引的构建等,但增加了开发和维护成本。
从上述介绍中可以得知,目前尚没有一个统一的可以实现所有类型知识存储的方式。因此,如何根据自身知识的特点选择知识存储方案,或者进行存储方案的结合,以满足针对知识的应用需要,是知识存储过程中需要解决的关键问题。
关于知识存储的详细知识与技术,请参考本书第3章。
9.1.3 知识抽取
知识抽取是指从不同来源、不同数据中进行知识提取,形成知识并存入知识图谱的过程。由于真实世界中的数据类型及介质多种多样,所以如何高效、稳定地从不同的数据源进行数据接入至关重要,其会直接影响到知识图谱中数据的规模、实时性及有效性。
在现有的数据源中,数据大致可分为三类:一类是结构化的数据,这类数据包括以关系数据库(MySQL、Oracle 等)为介质的关系型数据,以及开放链接数据,如 Yago、Freebase 等;第二类为半结构化数据,如百科数据(Wikipedia、百度百科等),或是垂直网站中的数据,如IMDB、丁香园等;第三类是以文本为代表的非结构化数据。
结构化数据中会存在一些复杂关系,针对这类关系的抽取是此类研究的重点,主要方法包括直接映射或者映射规则定义等;半结构化数据通常采用包装器的方式对网站进行解析,包装器是一个针对目标数据源中的数据制定了抽取规则的计算机程序。包装器的定义、自动生成以及如何对包装器进行更新及维护以应对网站的变更,是当前获取需要考虑的问题;非结构化数据抽取难度最大,如何保证抽取的准确率和覆盖率是这类数据进行知识获取需要考虑的科学问题。
关于知识抽取的详细知识和技术,请参考本书第4章。
9.1.4 知识融合
知识融合指将不同来源的知识进行对齐、合并的工作,形成全局统一的知识标识和关联。知识融合是知识图谱构建中不可缺少的一环,知识融合体现了开放链接数据中互联的思想。良好的融合方法能有效地避免信息孤岛,使得知识的连接更加稠密,提升知识应用价值,因此知识融合是构建知识图谱过程中的核心工作与重点研究方向。
知识图谱中的知识融合包含两个方面,即数据模式层的融合和数据层的融合。数据模式层的融合包含概念合并、概念上下位关系合并以及概念的属性定义合并,通常依靠专家人工构建或从可靠的结构化数据中映射生成。在映射的过程中,一般会通过设置融合规则确保数据的统一。数据层的融合包括实体合并、实体属性融合以及冲突检测与解决。
进行知识融合时需要考虑使用什么方式实现不同来源、不同形态知识的融合;如何对海量知识进行高效融合[7] ;如何对新增知识进行实时融合以及如何进行多语言融合等问题[8] 。
关于知识融合的详细知识和技术,请参考本书第5章。
9.1.5 知识计算
知识计算是领域知识图谱能力输出的主要方式,通过知识图谱本身能力为传统的应用形态赋能,提升服务质量和效率。其中,图挖掘计算和知识推理是最具代表性的两种能力,如何将这两种能力与传统应用相结合是需要解决的一个关键问题。
知识推理一般运用于知识发现、冲突与异常检测,是知识精细化工作和决策分析的主要实现方式。知识推理又可以分为基于本体的推理和基于规则的推理。一般需要依据行业应用的业务特征进行规则的定义,并基于本体结构与所定义的规则执行推理过程,给出推理结果。知识推理的关键问题包括:大数据量下的快速推理,记忆对于增量知识和规则的快速加载[9] 。
知识图谱的挖掘计算与分析指基于图论的相关算法,实现对图谱的探索与挖掘。图计算能力可辅助传统的推荐、搜索类应用。知识图谱中的图算法一般包括图遍历、最短路径、权威节点分析、族群发现最大流算法、相似节点等,大规模图上的算法效率是图算法设计与实现的主要问题。
关于知识推理与分析的详细知识和技术,请参考本书的第6章。
9.1.6 知识应用
知识应用是指将知识图谱特有的应用形态与领域数据和业务场景相结合,助力领域业务转型。知识图谱的典型应用包括语义搜索、智能问答以及可视化决策支持。如何针对业务需求设计实现知识图谱应用,并基于数据特点进行优化调整,是知识图谱应用的关键研究内容。
其中,语义搜索是指基于知识图谱中的知识,解决传统搜索中遇到的关键字语义多样性及语义消歧的难题,通过实体链接实现知识与文档的混合检索。语义检索需要考虑如何解决自然语言输入带来的表达多样性问题,同时需要解决语言中实体的歧义性问题。
而智能问答是指针对用户输入的自然语言进行理解,从知识图谱或目标数据中给出用户问题的答案。智能问答的关键技术及难点包括:
1)准确的语义解析,如何正确理解用户的真实意图。
2)对于返回的答案,如何评分以确定优先级顺序。
可视化决策支持则指通过提供统一的图形接口,结合可视化、推理、检索等,为用户提供信息获取的入口。对于可视化决策支持,需要考虑的关键问题包括:如何通过可视化方式辅助用户快速发现业务模式;如何提升可视化组件的交互友好程度,例如高效地缩放和导航;大规模图环境下底层算法的效率。
关于知识图谱的搜索及问答技术,请参考本书的第7章和第8章。