
JavaScript面向对象核心知识与概念归纳整理

本文实例讲述了JavaScript面向对象核心知识与概念。分享给大家供大家参考,具体如下:
一、面向对象
1.1 概念
- 面向对象就是使用对象。面向对象开发就是使用对象开发。
- 面向过程就是用过程的方式进行开发。面向对象是对面向过程的封装。
1.2 三大特性
抽象性
所谓的抽象性就是:如果需要一个对象描述数据,需要抽取这个对象的核心数据
- 提出需要的核心属性和方法
- 不在特定的环境下无法明确对象的具体意义
封装性
对象是将数据与功能组合到一起,即封装
- JS对象就是键值对的集合,键值如果是数据(基本数据、符合数据、空数据)就称为属性,如果键值是函数那么就称为方法
- 对象就是将属性与方法封装起来
- 方法是将过程封装起来
继承性
所谓继承性就是自己没有但是别人有,拿过来成为自己的,就是继承,继承是实现复用的一种手段
- 在Java等语言中继承满足一个class的规则,类是一个class,他规定了一个对象有什么属性和方法。
- 在这些语言中继承是class之间的继承,一个class继承另一个class,那么该class就有了另一个class的成员,那么由该class创建出来的对象就同时具有两个class的成员。
在JS中没有明确的继承语法(ES6提供了class extend语法),一般都是按照继承的理念实现对象的成员扩充实现继承,因此JS中实现继承的方法非常对多。
传统继承基于类,JS继承基于对象
一个简单的继承模式:混入(mix)
function mix ( o1, o2 ) {
for ( var k in o2 ) {
o1[ k ] = o2[ k ];
}
}
1.3 关于面向对象的一些其他概念
类class:在JS中就是构造函数
- 在传统的面向对象语言中,使用一个叫类的东西定义模板,然后使用模板创建对象。
- 在构造方法中也具有类似的功能,因此也称其为类
实例(instance)与对象(object)
- 实例一般是指某一个构造函数创建出来的对象,我们称为XXXX 构造函数的实例
- 实例就是对象。对象是一个泛称
- 实例与对象是一个近义词
键值对与属性和方法
- 在JS中键值对的集合称为对象
- 如果值为数据(非函数),就称该键值对为属性
- 如果值为函数(方法),就称该键值对为方法method
父类与子类(基类和派生类)
- 传统的面向对象语言中使用类来实现继承那么就有父类、子类的概念
- 父类又称为基类,子类又称为派生类
- 在JS中没有类的概念,在JS中常常称为父对象,子对象,基对象,派生对象。
二、构造函数
2.1 构造函数是干什么用的
- 初始化数据的
- 在JS中给对象添加属性用的,初始化属性值用的
2.2 创建对象的过程
- 代码:var p = new Person();
-
首先运算符new创建了一个对象,类似于{},是一个没有任何(自定义)成员的对象。
- 使用new 创建对象,那么对象的类型就是创建他的构造函数名
- 使用{}无论如何都是Object类型,相当于new Object
-
然后调用构造函数,为其初始化成员
- 构造函数在调用的一开始,有一个赋值操作,即this = 刚刚创建出来的对象。
- 因此在构造函数中this表示刚刚创建出来的对象。
- 在构造函数中 利用 对象的动态特性 为其对象添加成员。
三、作用域
3.1 什么是作用域
域表示的就是范围,即作用域,就是一个名字在什么地方可以使用,什么时候不能使用。
简单的说,作用域是针对变量的,比如我们创建一个函数 a1,函数里面又包了一个子函数 a2。
// 全局作用域
functiona a1() {
// a1作用域
function a2() {
// a2作用域
}
}
此时就存 在三个作用域:全局作用域,a1 作用域,a2 作用域;即全局作用域包含了 a1 的作用域,a2 的作用域包含了 a1 的作用域。
当 a2 在查找变量的时候会先从自身的作用域区查找,找不到再到上一级 a1 的作用域查找,如果还没找到就
到全局作用域区查找,这样就形成了一个作用域链。
3.2 JS中词法作用域的规则
- 函数允许访问函数外部的数据
- 整个代码结构中只有函数可以限定作用域
- 作用规则首先使用提升规则分析
- 如果当前作用域中有了名字了,就不考虑外面的名字
3.3 属性搜索原则
- 所谓的属性搜索原则,就是对象在访问属性或方法的时候,首先在当前对象中查找
- 如果当前对象中存储着属性或方法,停止查找,直接使用该属性或方法
- 如果当前对象没有该成员,那么再在其原型对象中查找
- 如果原型对象中含有该成员,那么停止查找,直接使用
- 如果原型中还没有,就到原型的原型中查找
- 如此往复,直到Object.protitype还没有,那么就返回undefined
- 如果是调用方法就报错,该xxx不是一个函数
四、闭包
4.1 说说你对闭包的理解
实用闭包主要是为了设计私有方法和变量。闭包的优点是可以避免全局变量的污染;缺点是闭包会常驻内存,增加内存使用量,使用不当很容易造成内存泄露。在JavaScript中,函数即闭包,只有函数才能产生作用域。
闭包有3个特性:
- 函数嵌套函数
- 在函数内部可以引用外部的参数和变量
- 参数和变量不会以垃圾回收机制回收
4.2 闭包有什么用(特性)
闭包的作用,就是保存自己私有的变量,通过提供的接口(方法)给外部使用,但外部不能直接访问该变量。
通过使用闭包,我们可以做很多事情,比如模拟面向对象的代码风格;更优雅,更简洁的表达出代码;在某些方面提升代码的执行效率。利用闭包可以实现如下需求:
- 匿名自执行函数
一个匿名的函数,并立即执行它,由于外部无法引用它内部的变量,因此在执行完后很快就会被释放,关键是这种机制不会污染全局对象。
- 缓存
闭包正是可以做到这一点,因为它不会释放外部的引用,从而函数内部的值可以得以保留。
- 实现封装
- 模拟面向对象的代码风格
4.3 闭包的基本模型
对象模式
函数内部定义个一个对象,对象中绑定多个函数(方法),返回对象,利用对象的方法访问函数内的数据
function createPerson() {
var __name__ = "";
return {
getName: function () {
return __name__;
},
setName: function( value ) {
// 如果不姓张就报错
if ( value.charAt(0) === '张' ) {
__name__ = value;
} else {
throw new Error( '姓氏不对,不能取名' );
}
}
}
}
var p = createPerson();
p.set_Name( '张三丰' );
console.log( p.get_Name() );
p.set_Name( '张王富贵' );
console.log( p.get_Name() );
函数模式
函数内部定义一个新函数,返回新函数,用新函数获得函数内的数据
function foo() {
var num = Math.random();
function func() {
return mun;
}
return func;
}
var f = foo();
// f 可以直接访问这个 num
var res1 = f();
var res2 = f();
沙箱模式
沙箱模式就是一个自调用函数,代码写到函数中一样会执行,但是不会与外界有任何的影响,比如jQuery
(function () {
var jQuery = function () { // 所有的算法 }
// .... // .... jQuery.each = function () {}
window.jQuery = window.$ = jQuery;
})();
$.each( ... )
4.4 闭包的性能问题
js 垃圾回收机制,也就是当一个函数被执行完后,其作用域会被收回,如果形成了闭包,执行完后其作用域就不会被收回。
函数执行需要内存,那么函数中定义的变量,会在函数执行结束后自动回收,凡是因为闭包结构的,被引出的数据,如果还有变量引用这些数据的话,那么这些数据就不会被回收。因此在使用闭包的时候如果不使用某些数据了,一定要赋值一个null
var f = (function () {
var num = 123;
return function () {
return num;
};
})();
// f 引用着函数,函数引用着变量num
// 因此在不使用该数据的时候,最好写上
f = null;
五、原型
5.1 什么是原型
一句话说明什么是原型:原型能存储我们的方法,构造函数创建出来的实例对象能够引用原型中的方法。
JS中一切皆对象,而每个对象都有一个原型(Object除外),这个原型,大概就像Java中的父类,所以,基本上你可以认为原型就是这个对象的父对象,即每一个对象(Object除外)内部都保存了它自己的父对象,这个父对象就是原型。一般创建的对象如果没有特别指定原型,那么它的原型就是Object(这就很类似Java中所有的类默认继承自Object类)。
ES6通过引入class ,extends等关键字,以一种语法糖的形式把构造函数包装成类的概念,更便于大家理解。是希望开发者不再花精力去关注原型以及原型链,也充分说明原型的设计意图和类是一样的。
5.2 查看对象的原型
当对象被创建之后,查看它们的原型的方法不止一种,以前一般使用对象的__proto__属性,ES6推出后,推荐用Object.getPrototypeOf()方法来获取对象的原型
function A(){
this.name='lala';
}
var a=new A();
console.log(a.__proto__)
//输出:Object {}
//推荐使用这种方式获取对象的原型
console.log(Object.getPrototypeOf(a))
//输出:Object {}
无论对象是如何创建的,默认原型都是Object,在这里需要提及的比较特殊的一点就是,通过构造函数来创建对象,函数A本身也是一个对象,而A有两个指向表示原型的属性,分别是__proto__和prototype,而且两个属性并不相同
function A(){
this.name='lala';
}
var a=new A();
console.log(A.prototype)
//输出:Object {}
console.log(A.__proto__)
//输出:function () {}
console.log(Object.getPrototypeOf(A))
//输出:function () {}
函数的的prototype属性只有在当作构造函数创建的时候,把自身的prototype属性值赋给对象的原型。而实际上,作为函数本身,它的原型应该是function对象,然后function对象的原型才是Object。
总之,建议使用ES6推荐的查看原型和设置原型的方法。
5.3 原型的用法
其实原型和类的继承的用法是一致的:当你想用某个对象的属性时,将当前对象的原型指向该对象,你就拥有了该对象的使用权了。
function A(){
this.name='world ';
}
function B(){
this.bb="hello"
}
var a=new A();
var b=new B();
//将b设置为a的原型,此处有一个问题,即a的constructor也指向了B构造函数,可能需要纠正
Object.setPrototypeOf(a,b);
a.constructor=A;
console.log(a.bb); //hello
如果使用ES6来做的话则简单许多,甚至不涉及到prototype这个属性
class B{
constructor(){
this.bb='hello'
}
}
class A extends B{
constructor(){
super();
this.name='world';
}
}
var a=new A();
console.log(a.bb+" "+a.name); //hello world
console.log(typeof(A)) //"function"
怎么样?是不是已经完全看不到原型的影子了?活脱脱就是类继承,但是你也看得到实际上类A 的类型是function,所以说,本质上class在JS中是一种语法糖,JS继承的本质依然是原型,不过,ES6引入class,extends 来掩盖原型的概念也是一个很友好的举动,对于长期学习那些类继承为基础的面对对象编程语言的程序员而言。
我的建议是,尽可能理解原型,尽可能用class这种语法糖。
好了,问自己两个问题:
- 为什么要使用原型?——提高函数的复用性。
-
为什么属性不放在原型上而方法要放在原型上?
- 利用对象的动态特性:构造函数.prototype.xxxx = vvv
- 利用直接替换
Student.prototype = { sayHello : function(){}, study : function(){} };
5.4 原型链
什么是原型链?
凡是对象就有原型,那么原型又是对象,因此凡是给定一个对象,那么就可以找到他的原型,原型还有原型,那么如此下去,就构成一个对象的序列,称该结构为原型链。
每个实例对象都有一个__proto_属性,该属性指向它原型对象,这个实例对象 的构造函数有一个原型属性 prototype,与实例的__proto__属性指向同一个对象。当一个对象在查找一个属性的时, 自身没有就会根据__proto__ 向它的原型进行查找,如果都没有,则向它的原型的原型继续查找,直到查到 Object.prototype._proto_为 null,这样也就形成了原型链。
这个概念其实也变得比较简单,可以类比类的继承链条,即每个对象的原型往上追溯,一直到Object为止,这组成了一个链条,将其中的对象串联起来,当查找当前对象的属性时,如果没找到,就会沿着这个链条去查找,一直到Object,如果还没发现,就会报undefined。
原型链的结构
凡是使用构造函数,创建出对象,并且没有利用赋值的方式修改原型,就说该对象保留默认的原型链。
默认原型链结构是什么样子呢?
function Person(){}
var p = new Person();
//p 具有默认的原型链
默认的原型链结构就是:当前对象 -> 构造函数.prototype -> Object.prototype -> null
在实现继承的时候,有时候会利用替换原型链结构的方式实现原型继承,那么原型链结构就会发生改变
function DunizbCollection(){}
DunizbCollection.prototype = [];
var arr = new DunizbCollection();
此时arr对象的原型链结构被指向了数组对象的原型链结构了:arr -> [] -> Array.prototype -> Object.prototype -> null
用图形表示对象的原型链结构
以如下代码为例绘制原型链结构
function Person(){}
var p = new Person();
原型链结构图为:
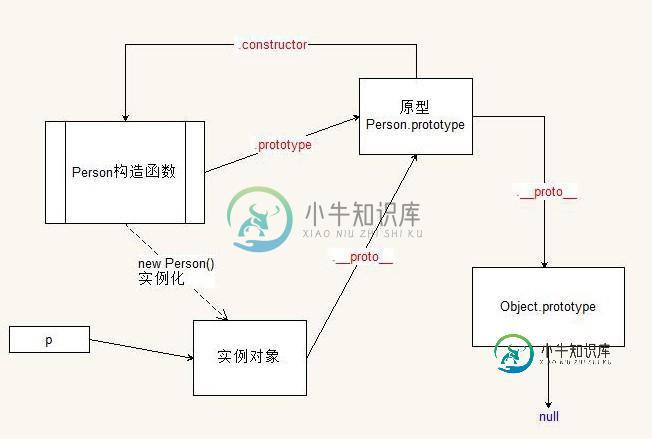
使用原型需要注意两点:
- 原型继承链条不要太长,否则会出现效率问题。
- 指定原型时,注意constructor也会改变。
六、继承
实现继承有两种常见方式:
6.1 混合式继承
最简单的继承就是将别的对象的属性强加到我身上,那么我就有这个成员了。
混合式继承的简单描述:
function Person() {};
Person.prototype.extend = function ( o ) {
for ( var k in o ) {
this[ k ] = o[ k ];
}
};
Person.prototype.extend({
run: function () { console.log( '我能跑了' ); },
eat: function () { console.log( '我可以吃了' ); },
sayHello: function () { console.log( '我吃饱了' ); }
});
6.2 原型继承
利用原型也可以实现继承,不需要在我身上添加任何成员,只要原型有了我就有了。
6.3 借用构造函数继承
这种技术的基本思想相当简单,即在子类型构造函数的内部调用超类型构造函数,而函数只不过是在特定环境中执行代码的对象,因此通过使用apply()和call()方法也可以在(将来)新创建的对象上执行构造函数
function Person ( name, age, gender ) {
this.name = name;
this.age = age;
this.gender = gender;
}
// 需要提供一个 Student 的构造函数创建学生对象
// 学生也应该有 name, age, gender, 同时还需要有 course 课程
function Student ( name, age, gender, course ) {
Person.call( this, name, age, gender );
this.course = course;
}
在《JavaScript高级程序设计(第三版)》中详细介绍了继承的6种方式
七、函数的四种调用模式
7.1 函数模式
就是一个简单的函数调用。函数名的前面没有任何引导内容。
function foo () {}
var func = function () {};
...
foo();
func();
(function () {} )();
this 的含义:在函数中 this 表示全局对象,在浏览器中式 window
7.2 方法模式
方法一定式依附与一个对象,将函数赋值给对象的一个属性,那么就成为了方法。
function f() {
this.method = function () {};
}
var o = {
method: function () {}
}
this 的含义:这个依附的对象
7.3 构造器调用模式
创建对象的时候构造函数做了什么?由于构造函数只是给 this 添加成员,没有做其他事情。而方法也可以完成这个操作,就是 this 而言,构造函数与方法没有本质的区别。
特征:
- 使用 new 关键字,来引导构造函数。
- 构造函数中的 this 与方法中的一样,表示对象,但是构造函数中的对象是刚刚创建出来的对象
-
构造函数中不需要 return ,就会默认的 return this。
- 如果手动添加return ,就相当于 return this
- 如果手动的添加 return 基本类型,无效,还是保留原来 返回 this
- 如果手动添加的 return null,或 return undefined ,无效
- 如果手动添加 return 对象类型,那么原来创建的 this 就会被丢掉,返回的是 return 后面的对象
7.4 上下文调用模式
上下文就是环境。就是自己定义设置 this 的含义。
语法
- 函数名.apply( 对象, [ 参数 ] );
- 函数名.call( 对象, 参数 );
描述
- 函数名就是表示函数本身,使用函数进行调用的时候默认 this 是全局变量
- 函数名也可以是方法提供,使用方法调用的时候,this 是指向当前对象
- 使用 apply 进行调用后,无论是函数还是方法都无效了,我们的 this ,由 apply 的第一个参数决定
参数问题
无论是 call 还是 apply 在没有后面的参数的情况下(函数无参数,方法五参数)是完全一致的
function foo(){
console.log( this );
}
foo.apply( obj );
foo.call( obj );
第一个参数的使用也是有规则的:
- 如果传入的是一个对象,那么就相当于设置该函数中的 this 为参数
- 如果不传入参数,或传入 null、undefined 等,那么相当于 this 默认为 window
foo(); foo.apply(); foo.apply( null );
- 如果传入的是基本类型,那么 this 就是基本类型对应的包装类型的引用
在使用上下文调用的时候,原函数(方法)可能会带有参数,那么这个参数再上下文调用中使用 第二个(第 n 个)参数来表示
function foo( num ) {
console.log( num );
}
foo.apply( null, [ 123 ] );
// 等价于
foo( 123 );
参考资料
- 本文原型部分部分引用自《JavaScript原型详解》,版权归原作者所有
- js闭包的用途
感兴趣的朋友可以使用在线HTML/CSS/JavaScript代码运行工具:http://tools.jb51.net/code/HtmlJsRun测试上述代码运行效果。
更多关于JavaScript相关内容感兴趣的读者可查看本站专题:《javascript面向对象入门教程》、《JavaScript错误与调试技巧总结》、《JavaScript数据结构与算法技巧总结》、《JavaScript遍历算法与技巧总结》及《JavaScript数学运算用法总结》
希望本文所述对大家JavaScript程序设计有所帮助。
-
英文原文:http://emberjs.com/guides/concepts/core-concepts/ 要开始学习Ember.js,首先要了解一些核心概念。 Ember.js的设计目标是能帮助广大开发者构建能与本地应用相颦美的大型Web应用。要实现这个目标需要新的工具和新的概念。我们花了很大的功夫从Cocoa、Smalltalk等本地应用框架引入了其优秀的理念。 然而,记住Web的特殊性非常
-
Redux 本身很简单。 当使用普通对象来描述应用的 state 时。例如,todo 应用的 state 可能长这样: { todos: [{ text: 'Eat food', completed: true }, { text: 'Exercise', completed: false }], visibilityFilter: 'SHOW_CO
-
影子字段 判断该条 SQL 是否需要路由到影子数据库,为逻辑字段,数据库中不存在。 生产数据库 生产数据使用的数据库。 影子数据库 进行压测数据隔离的影子数据库,与生产数据库应当使用相同的配置。
-
弹性伸缩作业 指一次将数据由旧分片规则伸缩至新分片规则的完整流程。 数据节点 同数据分片中的数据节点 存量数据 在弹性伸缩作业开始前,数据分片中已有的数据。 增量数据 在弹性伸缩作业执行过程中,业务系统所产生的新数据。
-
主库 添加、更新以及删除数据操作所使用的数据库,目前仅支持单主库。 从库 查询数据操作所使用的数据库,可支持多从库。 主从同步 将主库的数据异步的同步到从库的操作。由于主从同步的异步性,从库与主库的数据会短时间内不一致。 负载均衡策略 通过负载均衡策略将查询请求疏导至不同从库。
-
导览 本小节主要介绍分布式事务的核心概念,主要包括: 基于 XA 协议的两阶段事务 基于 Seata 的柔性事务